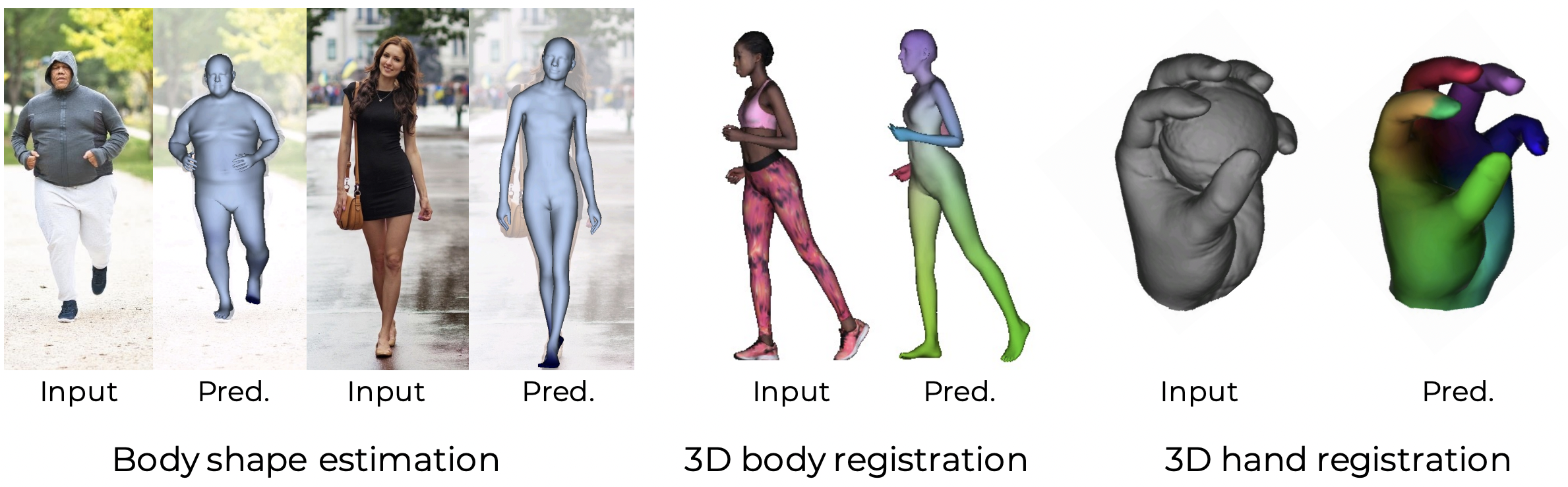
Learned Vertex Descent works with the parametric models SMPL or MANO, which can be downloaded from their websites. In particular, we use the neutral SMPL with cocoplus regressor and the original MANO layer for pytorch. If you need to train the model on humans you will need supervision on SMPL, which we had on 3D scans with SMPL registrations. However, we also provide trained checkpoints for the task of SMPL estimation from images, SMPL estimation from 3D scans and MANO estimation from 3D hand scans.
We trained our networks with the neutral SMPL model. Please download the neutral SMPL files from the [official website] and place the neutral_smpl_with_cocoplus_reg.txt under the utils/ folder.
With the task of 3D hand reconstruction, we use MANO and follow the pytorch implementation from https://github.com/hassony2/manopth. Please follow their instructions to download MANO from the official website and install the MANO library.
Please respect the license of the respective works.
For training on the task of SMPL estimation from images or pointclouds, we use the [RenderPeople], [AXYZ] and [Twindom] datasets.
The pre-processing follows a similar approach as in other works and, in particular, should follow the same procedure as in IP-Net. Please go to their repo to follow these steps: https://github.com/bharat-b7/IPNet
Get the trained checkpoints from [this link] and unzip the file on the main folder
We provide a few examples to test the trained checkpoints, on all the tasks proposed in our paper. We also provide a few testing samples, and all results will be saved under results/
To test LVD on the task of SMPL estimation from monocular images, run one of the following commands. The test script will take the input image and mask and predict SMPL. By default we also fit SMPL after the prediction, which will help to correct any imperfection or get pose and shape SMPL parameters. However, you can disactivate this option to get much faster predictions.
python test_LVD_images.py --model LVD_images_SMPL --name LVD_images_SMPL
We noticed that predictions are a bit more robust when also passing the mask as input to the network, which can be concatenated to the RGB input image:
python test_LVD_images.py --model LVD_images_wmask_SMPL --name LVD_images_wmask_SMPL
The previous script requires both input image and segmentation mask, both being roughly centered. We also provide the following script to take just a normal image and preprocess it automatically. For that, we leverage the mediapipe library, which is straightforward to install and easy to use. To install it, just run pip install mediapipe, and execute the following script:
python test_LVD_images.py --model LVD_images_SMPL --name LVD_images_SMPL
OR
python test_LVD_images.py --model LVD_images_wmask_SMPL --name LVD_images_wmask_SMPL
Note, however, that our method will likely fail in complex poses that are different from the poses in the RenderPeople dataset, which are mostly in standing poses. On the other hand, it should capture better the body shape of the input images.
When taking volumetric inputs, we need to convert them to voxel representations. The following script will run automatically for any input 3D scan and generate the SMPL predictions:
python test_LVD_3Dscans.py --model LVD_voxels_SMPL --name LVD_voxels_SMPL --batch_size 1
For the task of MANO estimation when taking 3D pointclouds of hands as input, we can run the following command. This will test the trained checkpoint on all the pointclouds under the demo folder.
python test_LVD_MANO.py --model LVD_voxels_MANO --name LVD_voxels_MANO --batch_size 1
We provide code for training but our training used the RenderPeople/Axyz datasets. If you have access to these datasets, follow the instructions from IP-Net (https://github.com/bharat-b7/IPNet) to fit SMPL and SMPL+D on the scans.
We also provide data of a single user to show how the training works. This 3D scan is freely available on the RenderPeople website, but we here provide pre-processed data and the SMPL fit. For all scans we followed PIFu and rendered images with their code, with different lighting and viewpoint. After downloading the SMPL model, you can train this example with the following instruction
python train.py --dataset_mode overfit_demo_image_SMPL --model LVD_images_SMPL --nepochs_no_decay 300 --nepochs_decay 300 --lr_G 0.001 --name model_images_overfitting_one_user --batch_size 4 --display_freq_s 600 --save_latest_freq_s 600
On another tab, one can check the progress with tensorboard by running:
tensorboard --logdir=.
If you want to train LVD on a larger dataset, we provide an example of our dataloader for the RenderPeople dataset, where we train with the following commands:
Training original model:
xvfb-run -a python train.py --dataset_mode images_SMPL --model LVD_images_SMPL --nepochs_no_decay 500 --nepochs_decay 500 --lr_G 0.001 --name model_images_smplprediction_nomask --batch_size 2 --display_freq_s 3600 --save_latest_freq_s 3600
The model is slightly more stable if we also add the mask as a fourth channel on input images:
python train.py --dataset_mode images_SMPL --model LVD_images_wmask_SMPL --nepochs_no_decay 500 --nepochs_decay 500 --lr_G 0.001 --name model_images_smplprediction_wmask --batch_size 2 --display_freq_s 3600 --save_latest_freq_s 3600
We also provide code to train LVD for the task of SMPL estimation from input volumetric representations, following:
python train.py --dataset_mode voxels_SMPL --model LVD_voxels_SMPL --nepochs_no_decay 50 --nepochs_decay 50 --lr_G 0.001 --name hand_lvd_v3 --batch_size 4 --display_freq_s 300
And finally, use the following command to run on volumetric representations of hands, which include noisy hands or hands grasping objects:
python train.py --dataset_mode voxels_MANO --model LVD_voxels_MANO --nepochs_no_decay 50 --nepochs_decay 50 --lr_G 0.001 --name hand_lvd_v3 --batch_size 4 --display_freq_s 300
If you have any issue when running on a headless server, run any of the previous commands with XVFB: xvfb-run -a python ...
@article{corona2022learned,
title={Learned Vertex Descent: A New Direction for 3D Human Model Fitting},
author={Corona, Enric and Pons-Moll, Gerard and Aleny{\`a}, Guillem and Moreno-Noguer, Francesc},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2022}
}