



FASTopic: Pretrained Transformer is a Fast, Adaptive, Stable, and Transferable Topic Model (NeurIPS 2024)
[Video]
[TowardsDataScience Blog]
[Huggingface Blog]
FASTopic is a fast, adaptive, stable, and transferable topic model, different from the previous conventional (LDA), VAE-based (ProdLDA, ETM), or clustering-based (Top2Vec, BERTopic) methods. It leverages optimal transport between the document, topic, and word embeddings from pretrained Transformers to model topics and topic distributions of documents.
If you want to use FASTopic, please cite our paper as
@article{wu2024fastopic,
title={FASTopic: A Fast, Adaptive, Stable, and Transferable Topic Modeling Paradigm},
author={Wu, Xiaobao and Nguyen, Thong and Zhang, Delvin Ce and Wang, William Yang and Luu, Anh Tuan},
journal={arXiv preprint arXiv:2405.17978},
year={2024}
}
FASTopicOverview.mp4
| Tutorial | Link |
|---|---|
| A complete tutorial on FASTopic. | |
| FASTopic with other languages. |
Install FASTopic with pip:
pip install fastopicOtherwise, install FASTopic from the source:
pip install git+https://github.com/bobxwu/FASTopic.gitDiscover topics from 20newsgroups with the topic number as 50.
from fastopic import FASTopic
from sklearn.datasets import fetch_20newsgroups
from topmost.preprocessing import Preprocessing
docs = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))['data']
preprocessing = Preprocessing(vocab_size=10000, stopwords='English')
model = FASTopic(50, preprocessing)
topic_top_words, doc_topic_dist = model.fit_transform(docs)topic_top_words is a list containing the top words of discovered topics.
doc_topic_dist is the topic distributions of documents (doc-topic distributions),
a numpy array with shape
from fastopic import FASTopic
from topmost.preprocessing import Preprocessing
# Prepare your dataset.
docs = [
'doc 1',
'doc 2', # ...
]
# Preprocess the dataset. This step tokenizes docs, removes stopwords, and sets max vocabulary size, etc.
# Pass your tokenizer as:
# preprocessing = Preprocessing(vocab_size=your_vocab_size, tokenizer=your_tokenizer, stopwords=your_stopwords_set)
preprocessing = Preprocessing(stopwords='English')
model = FASTopic(50, preprocessing)
topic_top_words, doc_topic_dist = model.fit_transform(docs)We can get the top words and their probabilities of a topic.
model.get_topic(topic_idx=36)
(('cancer', 0.004797671),
('monkeypox', 0.0044828397),
('certificates', 0.004410268),
('redfield', 0.004407463),
('administering', 0.0043857736))We can visualize these topic info.
fig = model.visualize_topic(top_n=5)
fig.show()
We use the learned topic embeddings and scipy.cluster.hierarchy to build a hierarchy of discovered topics.
fig = model.visualize_topic_hierarchy()
fig.show()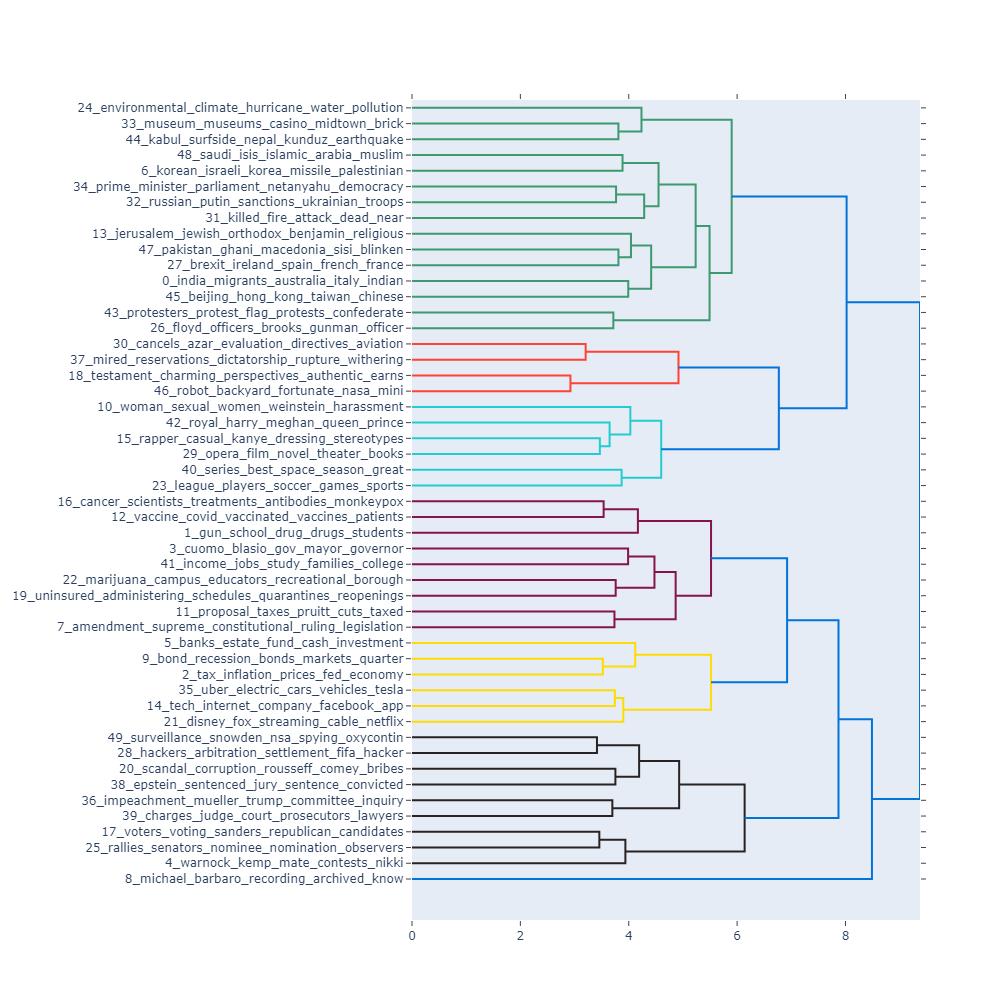
We plot the weights of topics in the given dataset.
fig = model.visualize_topic_weights(top_n=20, height=500)
fig.show()
Topic activity refers to the weight of a topic at a time slice.
We additionally input the time slices of documents, time_slices to compute and plot topic activity over time.
act = model.topic_activity_over_time(time_slices)
fig = model.visualize_topic_activity(top_n=6, topic_activity=act, time_slices=time_slices)
fig.show()
We summarize the frequently used APIs of FASTopic here. It's easier for you to look up.
| Method | API |
|---|---|
| Fit the model | .fit(docs) |
| Fit the model and predict documents | .fit_transform(docs) |
| Predict new documents | .transform(new_docs) |
| Get topic-word distribution matrix | .get_beta() |
| Get top words of all topics | .get_top_words() |
| Get top words and probabilities of a topic | .get_topic(topic_idx=10) |
| Get topic weights over the input dataset | .get_topic_weights() |
| Get topic activity over time | .topic_activity_over_time(time_slices) |
| Save model | .save(path=path) |
| Load model | .from_pretrained(path=path) |
| Method | API |
|---|---|
| Visualize topics | .visualize_topic(top_n=5) or .visualize_topic(topic_idx=[1, 2, 3]) |
| Visualize topic weights | .visualize_topic_weights(top_n=5) or .visualize_topic_weights(topic_idx=[1, 2, 3]) |
| Visualize topic hierarchy | .visualize_topic_hierarchy() |
| Visualize topic activity | .visualize_topic_activity(top_n=5, topic_activity=topic_activity, time_slices=time_slices) |
-
Meet the
out of memoryerror. My GPU memory is not enough due to large datasets. What should I do?You can try to set
save_memory=Trueandbatch_sizein FASTopic.batch_sizeshould not be too small, otherwise it may damage performance.model = FASTopic(50, save_memory=True, batch_size=2000)
Or you can run FASTopic on the CPU as
model = FASTopic(50, device='cpu')
-
Can I try FASTopic with the languages other than English?
Yes! You can pass a multilingual document embedding model, like
paraphrase-multilingual-MiniLM-L12-v2, and the tokenizer and the stop words for your language, like pipelines of spaCy.
Please refer to the tutorial in Colab. -
Loss value can not decline, and the discovered topics all are repetitive.
This may be caused by the less discriminative document embeddings, due to the used document embedding model or extremely short texts as inputs.
Try to (1) normalize document embeddings asFASTopic(50, normalize_embeddings=True); or (2) increaseDT_alphato5.0,10.0or15.0, asFASTopic(num_topics, DT_alpha=10.0). -
Can I use my own document embedding models?
Yes! You can wrap your model and pass it to FASTopic:
class YourDocEmbedModel: def __init__(self): ... def encode(self, docs: List[str], show_progress_bar: bool=False, normalize_embeddings: bool=False ): ... return embeddings your_model = YourDocEmbedModel() FASTopic(50, doc_embed_model=your_model)
- We welcome your contributions to this project. Please feel free to submit pull requests.
- If you encounter any issues, please either directly contact Xiaobao Wu (xiaobao002@e.ntu.edu.sg) or leave an issue in the GitHub repo.
- TopMost: a topic modeling toolkit, including preprocessing, model training, and evaluations.
- A Survey on Neural Topic Models: Methods, Applications, and Challenges