Audio samples for the paper "TinyLSTMs: Efficient Neural Speech Enhancement for Hearing Aids".
Modern speech enhancement algorithms achieve remarkable noise suppression by means of large recurrent neural networks (RNNs). However, large RNNs limit practical deployment inhearing aid hardware (HW) form-factors, which are battery powered and run on resource-constrained microcontroller units (MCUs) with limited memory capacity and compute capability. In this work, we use model compression techniques to bridge this gap. We define the constraints imposed on the RNN by the HW and describe a method to satisfy them. Although model compression techniques are an active area of research, we are the first to demonstrate their efficacy for RNN speech enhancement using pruning and integer quantization of weights and activations. We also demonstrate state update skipping, which reduces the computational load. Finally, we conduct a perceptual evaluation of the compressed models to verify audioquality on human raters. Results show a reduction in model sizeand operations of 11.9× and 2.9×, respectively, over the base-line for compressed models, without a statistical difference inlistening preference and only exhibiting a loss of 0.55dB SDR. Our model achieves a computational latency of 2.39ms, well within the 10ms target and 351× better than previous work.
Audio files are organized using the following folder structure:
audio
└── model_name
└── snr_level
└── utterance_id
├── clean.wav
├── dirty.wav
└── proc.wav
Corresponds to the model name from the paper.
baseline-> baseline (FP32)pruned_and_quantized_1-> Pruned (INT8) 1pruned_and_quantized_2-> Pruned (INT8) 2skip_rnn_pruned_and_quantized-> SkipRNN Pruned and Quantized (not included in perceptual eval)
Ranges from -6 dB to 9 dB in 3dB increments. Indicates the original SNR level of the utterance from the CHiME2 dataset.
Indicates the original clean utterance ID from the CHiME2 dataset.
Each folder contains three 16kHz .wav files.
dirty.wavis the original (unprocessed) noisy utterance.proc.wavis the processed de-noised utterance by the corresponding SE model.clean.wavis the clean target utterance.
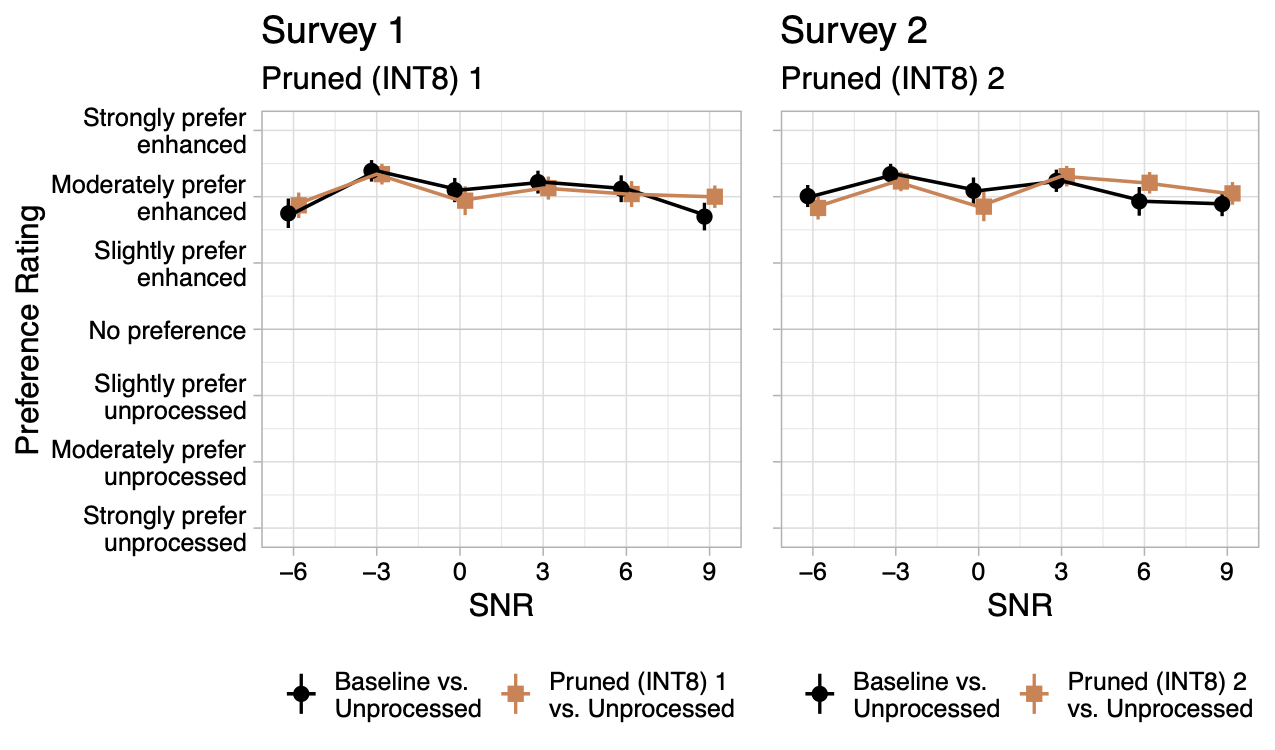
Preference of perceptual study participants (N = 50) for enhanced audio vs. unprocessed audio for both compressed (Baseline) and pruned & quantized (Pruned INT 8) models across input SNR's. Left is Pruned (INT8) 1 and right is Pruned (INT8) 2.