1. 简介
本项目基于 PaddleOCR 和 Docker 实现了 OCR 应用的快速部署。核心推理功能(文本检测与文本识别)使用 C++ 实现,场景应用(通用识别、身份证识别、文档识别等)使用 Python 实现。最后使用 FastAPI 编写接口并通过 Docker 进行服务化部署,使用 streamlit 实现简单的前端界面。
2. 项目结构
├── app.py # OCR 场景功能
├── Dockerfile # 构建 docker 镜像
├── LICENSE.txt
├── ocr-web.py # streamlit 前端
├── requirements.txt # python 依赖
├── run_docker.sh # 创建 docker 容器
├── server.py # FastAPI 接口构建依赖:
- Paddle Inference C++ 推理库(v2.3.1;gcc8.2;MKL)
- OpenCV-3.4.16
- docker image(paddlepaddle/paddle:2.2.2)
- Python 3.7
3. 部署
1.克隆仓库到本地
git clone https://github.com/BruceHan98/ocr-docker
cd ocr-docker
2.构建 docker 镜像并创建容器
bash run_docker.shFastAPI 端口为 9000,访问 http://<your_ip>:9000/docs 查看接口文档。
3.运行前端 demo
修改 ocr-web.py 中的 your_ip 为服务器 ip 地址,your_port 为 FastAPI 端口号。
pip install streamlit
streamlit run ocr-web.py前端访问端口默认为 8501。
4. 功能
为了部署方便,项目首先将 OCR 推理功能构建为 docker 镜像:基础镜像为 paddlepaddle/paddle:2.2.2,基于该镜像构建 C++ 推理功能,并封装为镜像 brucehan98/ppocr-cpu:latest。在此镜像中可调用 ppocr system --image_dir <image_dir> 实现 OCR 推理。
在业务层,使用 Python 编写场景应用,通过执行系统命令调用 C++ 推理功能,实现文本检测与识别。具体可参考 app.py 与 server.py。
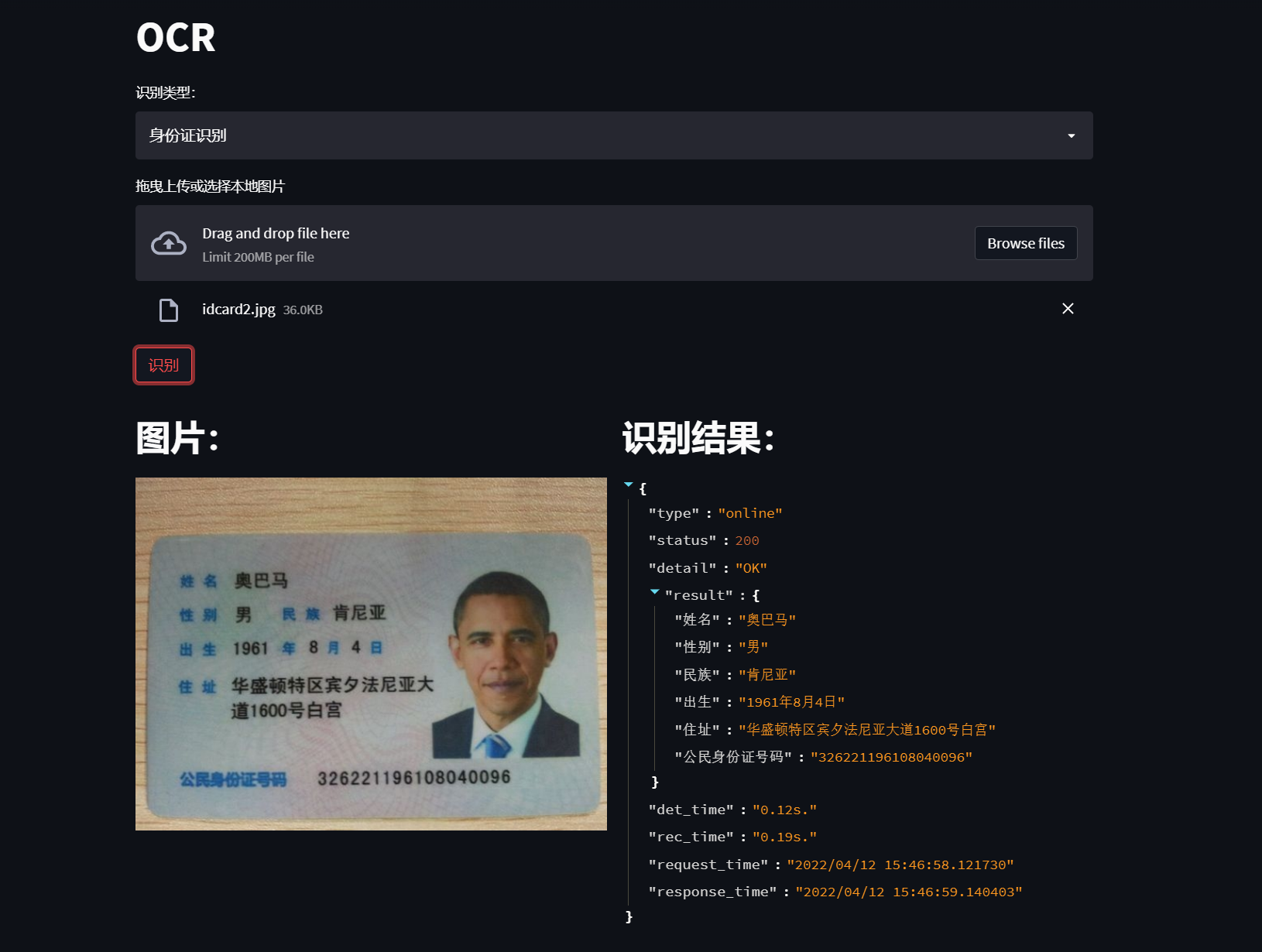
效果展示:
开源协议:Apache 2.0 license