Imagine having a data collection of hundreds of thousands to millions of images
without any metadata describing the content of each image. How can we build a
system that is able to find a sub-set of those images that best answer a user’s
search query ?
What we will basically need is a search engine that is able
to rank image results given how well they correspond to the search query, which
can be either expressed in a natural language or by another query image.
The
way we will solve the problem in this post is by training a deep neural model
that learns a fixed length representation (or embedding) of any input image and
text and makes it so those representations are close in the euclidean space if
the pairs text-image or image-image are “similar”.
I could not find a data-set of search result ranking that is big enough but I was able to get this data-set : http://jmcauley.ucsd.edu/data/amazon/ which links E-commerce item images to their title and description. We will use this metadata as the supervision source to learn meaningful joined text-image representations. The experiments were limited to fashion (Clothing, Shoes and Jewelry) items and to 500,000 images in order to manage the computations and storage costs.
The data-set we have links each image with a description written in natural language. So we define a task in which we want to learn a joined, fixed length representation for images and text so that each image representation is close to the representation of its description.
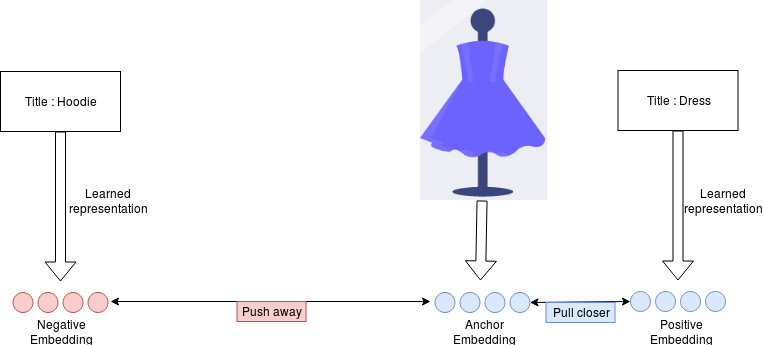
The model takes 3 inputs : The image (which is the anchor), the image
title+description ( the positive example) and the third input is some randomly
sampled text (the negative example).
Then we define two sub-models :
- Image encoder : Resnet50 pre-trained on ImageNet+GlobalMaxpooling2D
- Text encoder : GRU+GlobalMaxpooling1D
The image sub-model produces the embedding for the Anchor **E_a **and the text sub-model outputs the embedding for the positive title+description E_p and the embedding for the negative text E_n.
We then train by optimizing the following triplet loss:
L = max( d(E_a, E_p)-d(E_a, E_n)+alpha, 0)
Where d is the euclidean distance and alpha is a hyper parameter equal to 0.4 in this experiment.
Basically what this loss allows to do is to make **d(E_a, E_p) small and make d(E_a, E_n) **large, so that each image embedding is close to the embedding of its description and far from the embedding of random text.
Once we learned the image embedding model and text embedding model we can visualize them by projecting them into two dimensions using tsne (https://scikit-learn.org/stable/modules/generated/sklearn.manifold.TSNE.html ).
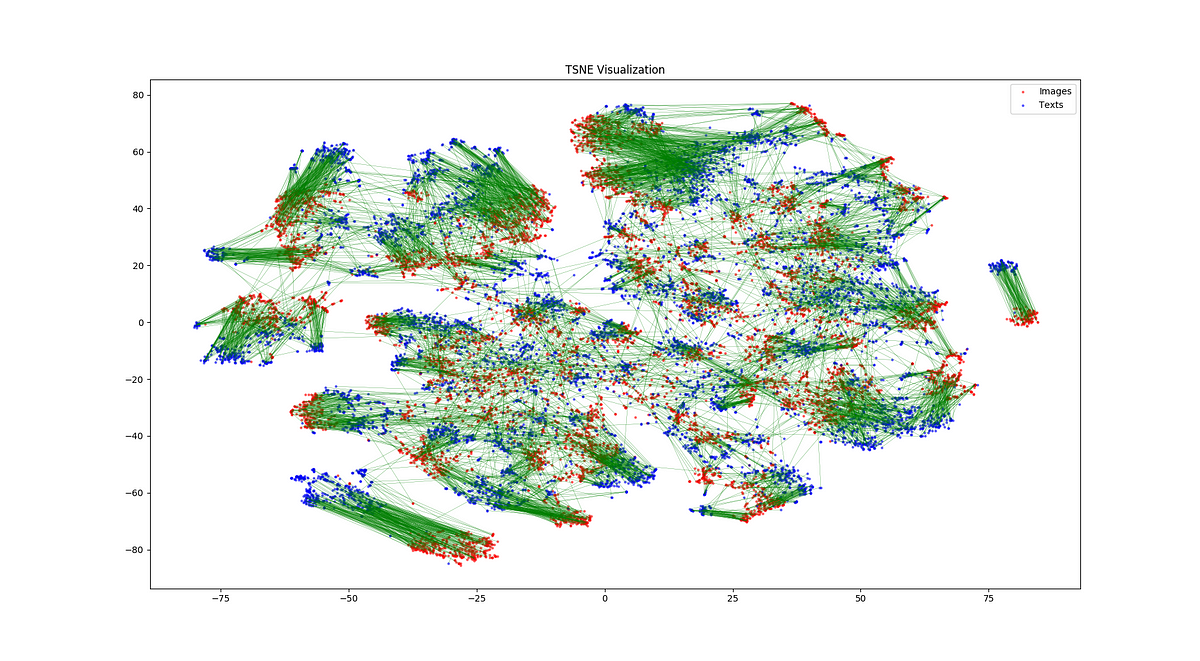
We can see from the plot that generally, in the embedding space, images and their corresponding descriptions are close. Which is what we would expect given the training loss that was used.
Here we use few examples of text queries to search for the best matches in a set of 70,000 images. We compute the text embedding for the query and then the embedding for each image in the collection. We finally select the top 9 images which are the closest to the query in the embedding space.


These examples show that the embedding models are able to learn useful representations of images and embeddings of simple composition of words.
Here we will use an image as a query and then search in the database of 70,000 images for the examples that are most similar to it. The ranking is determined by how close each pair of images are in the embedding space using the euclidean distance.


The results illustrate that the embeddings generated are high level representations of images that capture the most important characteristics of the objects represented without being excessively influenced by the orientation, lighting or minor local details, without being trained explicitly to do so.
In this project we worked on the Machine learning blocks that allow us to build a keyword and image based search engine applied to a collection of images. The basic idea is to learn a meaningful and joined embedding function for text and image and then use the distance between items in the embedding space to rank search results.
References :