2019秋分布式系统
-
瞬时并发量大,秒杀时候会有大量用户在同一时间进行抢购,并发访问量会突然暴增
-
库存量少,一般用户数目远远大于库存数量,需要防止超卖现象出现
-
业务流程简单: 下订单->数据库的库存减少->支付订单
-
网络流量暴增,对应网络带宽的突然增加
-
读多写少:一趟火车其实只有2000张票,200w个人来买,最多2000个人下单成功,其他人都是查询库存,写比例只有0.1%,读比例占99.9%
-
限流
限制大部分用户流量,只允许少量用户进入后端服务器
-
削峰
通过使用缓存和消息队列中间件把瞬间的流量高峰变得平缓
-
异步
异步其实也是削峰的一种实现方式,可以提高系统并发量
-
内存缓存
数据库读写为磁盘IO,因此可以把部分数据或者业务逻辑转移到内存缓存(Redis)
-
负载均衡 利用Nginx使用多个服务器并发处理请求,以减少单个服务器的压力
核心**:
-
尽量把请求拦截在上流,层层过滤,通过充分利用缓存与消息队列,提高请求处理速度以及削峰,根本核心是最终减轻对数据库的压力.如果不在上流拦截,会导致数据库读写锁冲突变得严重,并且导致死锁,最终请求超时.
-
优化方案主要放在服务端优化与数据库优化
服务端优化:并发处理,队列处理 数据库优化:数据库缓存,分库分表,分区操作,读写分离,负载均衡
- 架构图
完全版
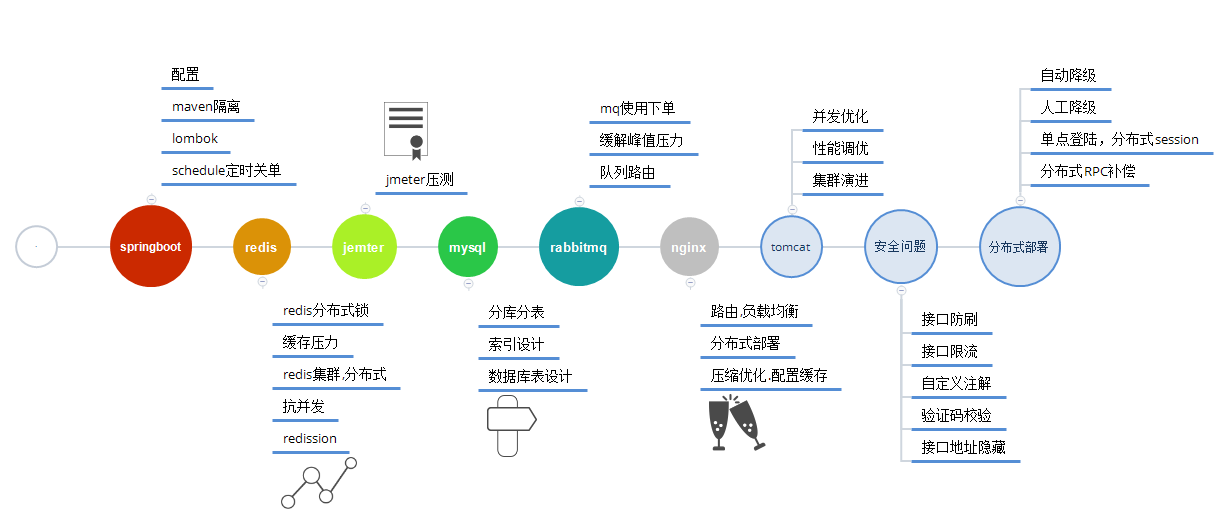
简要版

Nginx:反向代理&负载均衡,把用户的请求分发到不同的机器上
Redis: 内存缓存:实现分布式锁,提高读写速度,分担数据库压力
Kafka: 消息队列,削峰,处理流量猛增的情况,拦截大量并发请求,同时实现了消息异步处理
MYSQL: 持久化存储商品信息,实现数据的强一致性检验,同时大规模高并发下要实现分库分表,读写分离mysql在高并发场景中使用
大概流程如下,rabbitMQ也是一种消息队列
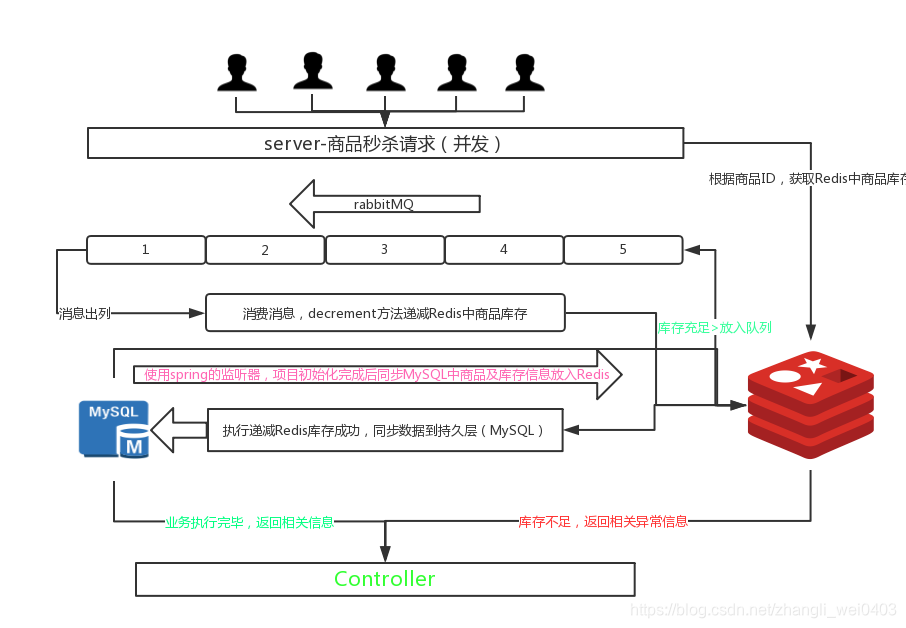
Kafka 异步削峰 与 Redis耦合的示意图
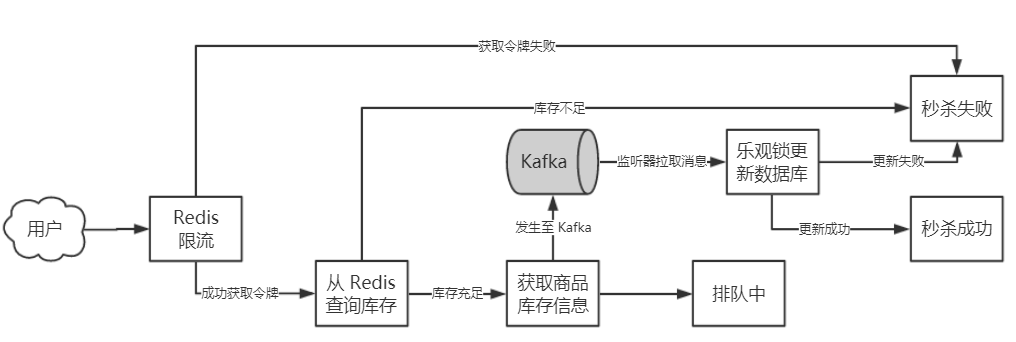
- Redis限流
假设现在有 10 个商品,有 1000 个并发秒杀请求,最终只有 10 个订单会成功创建,也就是说有 990 的请求是无效的,这些无效的请求也会给数据库带来压力,因此可以在在请求落到数据库之前就将无效的请求过滤掉,将并发控制在一个可控的范围,这样落到数据库的压力就小很多.要求实现一个Redis 限流算法,限制只有少部分秒杀请求获得"令牌"
这部分demo代码并没有涉及.
- 限流之后,获得令牌的请求将首先向Redis查询是否库存足够
如果库存是充足的,才把下单请求发送给Kafka.
/**
* 秒杀的请求
* @param sid stock id
*/
@Override
public void checkRedisAndSendToKafka(int sid) {
//首先检查Redis(内存缓存)的库存
Stock stock = checkStockWithRedis(sid);
//下单请求发送到Kafka,序列化类
kafkaTemplate.send(kafkaTopic, gson.toJson(stock));
log.info("消息发送至Kafka成功");
}
检查Redis库存是否充足的逻辑
private Stock checkStockWithRedis(int sid) {
Integer count = Integer.parseInt(RedisPool.get(StockWithRedis.STOCK_COUNT + sid));
Integer version = Integer.parseInt(RedisPool.get(StockWithRedis.STOCK_VERSION + sid));
Integer sale = Integer.parseInt(RedisPool.get(StockWithRedis.STOCK_SALE + sid));
if (count < 1) {
log.info("库存不足");
throw new RuntimeException("库存不足 Redis currentCount: " + sale);
}
Stock stock = new Stock();
stock.setId(sid);
stock.setCount(count);
stock.setSale(sale);
stock.setVersion(version);
// 此处应该是热更新,但是在数据库中只有一个商品,所以直接赋值
stock.setName("mobile phone");
return stock;
}
- Kafka负责监听发送到Kafka的信息,尝试用乐观锁机制更新数据库
@Override
public int createOrderAndSendToDB(Stock stock) throws Exception {
//TODO 乐观锁更新库存和Redis
updateMysqlAndRedis(stock);
// 创建订单,更新MYSQL数据库
int result = createOrder(stock);
if (result == 1) {
System.out.println("Kafka 消费成功");
} else {
System.out.println("Kafka 消费失败");
}
return result;
}
我们来看看updateRedis的逻辑实现 先更新MYSQL,MYSQL更新成功了再去更新Redis
int result = stockService.updateStockInMYSQL(stock);
if (result == 0) {
throw new RuntimeException("并发更新MYSQL失败");
}
StockWithRedis.updateStockWithRedis(stock);
}
其中stockService的updateStockInRedis方法对应一条乐观锁更新的SQL语句
该函数定义在dao层(data access object层)
/**
* 乐观锁 version
*/
@Update("UPDATE stock SET count = count - 1, sale = sale + 1, version = version + 1 WHERE " +
"id = #{id, jdbcType = INTEGER} AND version = #{version, jdbcType = INTEGER}")
int updateByOptimistic(Stock stock);
该语句可以返回结果并发更新MYSQL能否成功,如果成功则说明秒杀成功.然后调用StockWithRedis.updateStockWithRedis()方法更新redis. 更新redis的是原子操作,即使失败了也会回滚。 失败了也没关系,没必要保持MYSQL和Redis强一致性,即使Redis是脏数据,那么最后也会经过MYSQL的乐观锁来保证数据安全,不会超卖。
public static void updateStockWithRedis(Stock stock) {
Jedis jedis = null;
try {
jedis = RedisPool.getJedis();
Transaction transaction = jedis.multi();
//开始事务
RedisPool.decr(STOCK_COUNT + stock.getCount());
RedisPool.incr(STOCK_SALE + stock.getCount());
RedisPool.incr(STOCK_VERSION + stock.getVersion());
transaction.exec();
} catch (Exception e) {
log.error("updateStock fail", e);
e.printStackTrace();
}finally {
RedisPool.jedisPoolClose(jedis);
}
}
好到这里我们完成了对updateRedis的流程分析.
我们回头看createOrderAndSendToDB函数
int result = createOrder(stock);
接下来是createOrder函数.修改完redis中的数据后,我们接下来修改MYSQL层的数据
/**
* 创建持久化到数据库的订单
*/
private int createOrder(Stock stock) {
StockOrder order = new StockOrder();
order.setId(stock.getId());
order.setCreateTime(new Date());
order.setName(stock.getName());
int result = stockOrderMapper.insertToDB(order);
if (result == 0) {
throw new RuntimeException("创建订单失败");
}
return result;
}
核心就是insertToDB()这个函数,这个函数同样定义在dao,对应了一个SQL语句
这个语句表示插入一个新的订单.
@Insert("INSERT INTO stock_order (id, sid, name, create_time) VALUES " +
"(#{id, jdbcType = INTEGER}, #{sid, jdbcType = INTEGER}, #{name, jdbcType = VARCHAR}, #{createTime, jdbcType = TIMESTAMP})")
int insertSelective(StockOrder order);
这就是一个最基础的秒杀流程,主要所用到的是Redis缓存来抗大量的读请求+Kafka异步削峰+MYSQL乐观锁更新
demo待实现的部分:(2019.10.15)
归根到底我们的终极目标是减少对MYSQL数据库的写访问,尽量把大量请求拦截在上流,demo里只实现了利用Redis缓存来应对大量额外的读请求和 Kafka消息队列异步削峰这两个拦截方法.
可以参考的方法
1.整合Nginx反向代理,把大量的请求平摊到多个Nginx服务器
2.一开始订单来的时候,可以在内存用ConcurrentHashMap设置商品是否已经卖完的标识,如果卖完了的话就没有必要访问redis了
1.运行startApplication函数,可以在浏览器中打开,http://localhost:8088/swagger-ui.html#/ 进行你开发的restful api的测试 2.打开Jmeter,模拟秒杀请求(http://jmeter.apache.org)
- 新建线程组
- 修改线程数量,参数

- 添加HTTP请求
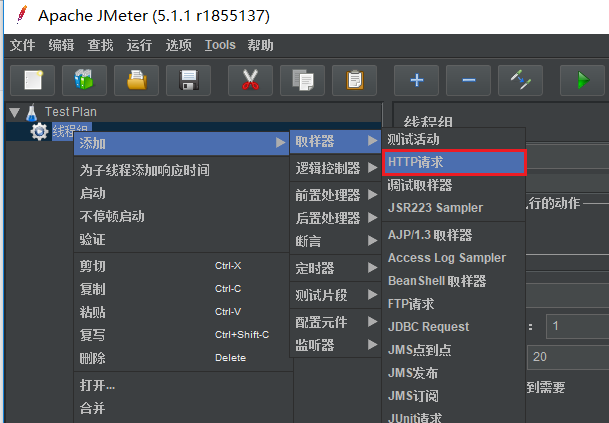
- 增加http协议,服务器ip(本地测试填本地地址),路径填你开发的restful api名称

- 汇总报告

- controller层定义了你开发的restfulapi,也是秒杀最基本的逻辑
- dao层是数据访问接口,定义了与MYSQL语句相耦合的函数
- pojo层是你定义的Java Beans类
- service层的api层,定义了具体函数逻辑的接口
- service层的impl层,实现了上述定义的接口,是具体代码逻辑的实现地方
4.在resources的application.yaml文件下修改集群的地址和端口
CREATE TABLE `stock` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL DEFAULT '' COMMENT '名称',
`count` int(11) NOT NULL COMMENT '库存',
`sale` int(11) NOT NULL COMMENT '已售',
`version` int(11) NOT NULL COMMENT '乐观锁,版本号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
CREATE TABLE `stock_order` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`sid` int(11) NOT NULL COMMENT '库存ID',
`name` varchar(30) NOT NULL DEFAULT '' COMMENT '商品名称',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=55 DEFAULT CHARSET=utf8;
-
主要开发语言: JAVA
建议使用 IntelliJ Idea 2019.3 企业版
-
项目框架: Spring Boot
-
消息队列 Kafka
-
内存数据库 Redis
-
数据库 MYSQL
-
反向传播与负载均衡 Nginx
-
容器化部署 Docker
-
压力测试 Jmeter
[RPC架构示例]https://github.com/SwordfallYeung/CustomRpcFramework