本專案以Spark-MLlib API實現爬蟲資料缺失自動補救機制,先透過FinMind API爬取每日股票,將資料存入Influx Database,當爬蟲部分出現錯誤而無法依序取得資料時,系統將自動呼叫MLlib API存取Database資料並進行預測,再將預測結果寫回Database,最後以Plotly API 和 Dash API進行資料視覺化比較有補救與未補救的差異,以下為我們整體專案的介紹和相關API的安裝流程。

每20秒call一次 FinMind API,並存到 influxDB,形成時間序列資料。當無法在時間內爬取到新資料(斷網、API故障),會視為缺失並且以資料缺失的日期為參數去 call spark 來預測這筆缺失的資料。本專案使用 2330(台積電) 為例,並以 API 回傳的 close 值為預測目標。
在資料的儲存上,我們選擇使用時間序列資料庫 - InfluxDB。並將其建立在 AWS 的 EC2(Win) 上,使用公開 IP 的方式和三方程式互動。
在資料庫這部分我們設計兩個 table web_crawler_data 和 prediction_data,兩個 table 都會儲存爬蟲的資料,差別是 prediction_data 會額外儲存 spark 預測的缺失值。
在 spark 的叢集上,我們選擇使用 vagrant 的方式在一台電腦建立多個 VM 作為節點。其中包含一個主節點(master)、兩個工作節點(worker),每個節點分配 2g 記憶體和3顆 cpu。
在首次 vagrant up 時 master 節點用 ssh-keygen 產生公鑰,並且複製到其他 worker 節點的 /root/.ssh 底下,並在 /etc/host 底下加入各節點的 IP 資訊,方便後續叢集的連接。此外,還會自動安裝 packages 底下預先下載好的 spark 和 java 的壓縮檔,並且將 spark 和 java 環境變數加入到使用者設定檔 .bashrc 底下,讓我們可以在 user 的資料夾裡直接執行 spark 環境。
- 程式碼為spark_predict.py,程式是以pyspark為基礎撰寫,由五個自訂函數組成,函數分別為:
-
get_args(): 用來取得預設參數,包括資料缺失的日期、時間及要預測的筆數、訓練模型所需的特徵數,而特徵則為近二筆的價格。 -
get_data(): 從influxdb撈取目前時點最近20筆(data_num*2)的資料,在20筆資料中篩選出早於缺失資料的時間的近10筆資料。由於我們要預測的是股價,屬於時間序列資料,因此透過一連串資料處理,產生sliding window的資料集,作為訓練預測模型的資料。 -
predict_price(): 輸入get_data產生資料集,製成dataframe,以T(當前close)作為label,近二筆的價格作為features,透過pipeline進行資料處理及訓練,訓練模型為Linear Regression,經過訓練後預測缺失資料時間的價格,將預測結果儲存成json格式,並判斷預測結果是否有正確產生,若無則輸出False狀態。 -
write_data(): 輸入predict_price()產生的預測結果與狀態,若狀態為True,則將預測結果寫回db的prediction_data表,否則,只印出失敗訊息不做任何動作。 -
main():依序執行將前述的四大功能,並印出各階段所花時間。
-
透過Plotly套件將資料庫讀取的DataFrame資料視覺化,並利用Dash套件將視覺化圖表呈現於網站,由於資料為時間序列資料,會不停地更新,因此設定每五秒從資料庫更新視覺化資料,即時呈現資料變動。
其中上下分別為 原始爬蟲資料(web_crawler_data) 與 經過 spark 填補的資料 (prediction_data),透過這種方式可以很值觀的比較兩者差別。
git clone https://github.com/C-WeiYu/Distributed-System-Spark.git
cd Distributed-System-Spark- 透過
Vagrantfile建立 spark cluster VM。(可以更改Vagrantfile的 num_nodes 設定總共要建立幾個工作節點)
vagrant up- 進入到 master 節點的 VM,啟動 master 節點。 (預設 spark-node1 為 master)
vagrant ssh spark-node1sudo $SPARK_HOME/sbin/start-master.sh- 依序進入到 worker 節點的 VM,下面以 spark-node2 為例。 (預設 spark-node2、spark-node... 為 worker)
vagrant ssh spark-node2sudo $SPARK_HOME/sbin/start-worker.sh spark://$MASTERIP:7077- 可以到 local 的電腦,進到 http://10.0.1.101:8080/ 去監控 VM 中的 Spark cluster。(10.0.1.101 為 master-node IP)

- 在 master 安裝所需的 python 套件。
cd Distributed-System-Spark
sudo pip3 install -r requirements.txt- 打開Windows PowerShell,貼上以下連結,安裝influxdb
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.8.6_windows_amd64.zip -UseBasicParsing -OutFile influxdb-1.8.6_windows_amd64.zip
Expand-Archive .\influxdb-1.8.6_windows_amd64.zip -DestinationPath 'C:\Program Files\InfluxData\influxdb\'- 修改C:\Program Files\InfluxData\influxdb\influxdb-1.8.6-1(預設路徑)底下的influxdb.conf
(45行、48行) 可修改預設檔案夾路徑
(251行) enabled = true
(260行) bind-address = ":8086"- 安裝NSSM,並執行
nssm.exe installPath的路徑為influxd.exe的檔案位置
Arguments的路徑為influxdb.conf的檔案位置- 在nssm/win64的目錄下,執行
sc start (Service name)- 在C:\Program Files\InfluxData\influxdb\influxdb-1.8.6-1(預設路徑)執行以下指令,啟動InfluxDB Server
influxd.exe --config influxdb.conf-
在aws控制台的安全設定中,對外開放8086 port
-
在Windows防火牆的進階設定中,對外開放8086 port
- 建立乾淨的 python 環境。(conda 為例也可以使用 virtualenv)
conda create --name env python=3.6
conda activate env- 安裝需要的套件。
pip install -r requirements.txt| 軟體 | 版本 | 網址 | 備註 |
|---|---|---|---|
| JAVA | JDK8(linux、x86 64bit) | OpenLogic’s OpenJDK Downloads | 可使用: Java 8/11, Scala 2.12/2.13 |
| Spark | 3.2.1(hadoop3.2) | Downloads | Apache Spark | |
| Python | 3.6.9 | ||
| Vagrant | 2.2.19 | Vagrant by HashiCorp (vagrantup.com) | 需先自行安裝 |
| Ubuntu | Ubuntu 18.04.6 LTS (Bionic Beaver) | Discover Vagrant Boxes - Vagrant Cloud (vagrantup.com) | 透過 vagrant 安裝 |
| InfluxDB | 1.8.6 | InfluxDB: Open Source Time Series Database |
- 在開始前,請確定設定好環境(看上一章 Dev Environment)
- 以下命令皆在
Distributed-System-Spark資料夾底下運行
python scripts/stock_dash.py
- Local: 跑視覺化 dashboard,透過瀏覽器開啟。
- Spark UI: Spark 內建,監控 spark cluster 的狀態,master node 執行後就可以在 local 的瀏覽器透過 http://10.0.1.101:8080/
- Master: 主要節點,負責執行爬蟲程式和 pyspark 預測資料
- Worker: 工作節點,負責執行 master 派下來的工作,這邊使用
htop開啟效能監控,可以呈現資源使用的狀態。
python3 scripts/crawler_version1.py- 註: 因目標是爬取股市資料,9:00 -13:30 才會有資料
vagrant halt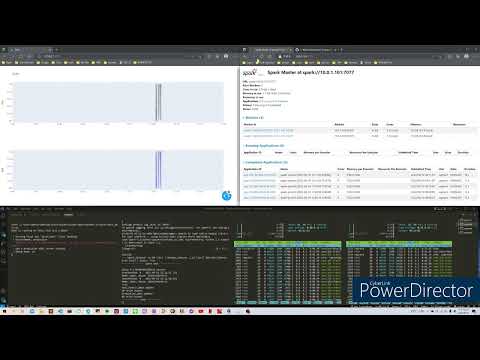
- Spark 叢集(Standalone Mode)
- 官方說明
- spark 叢集的設定
- vagrant 自動化部屬範例
- Ruby (vagrantfile)
- Pyspark
- 視覺化 Dashboard
- plotly + Dash
| 組員 | 系級 | 學號 | 工作分配 | github |
|---|---|---|---|---|
| 莊崴宇 | 資科碩一 | 110753117 | 簡報、github | C-WeiYu |
| 何彥南 | 資科碩一 | 110753202 | Spark 叢集、github、Demo 影片 | aaron1aaron2 |
| 姚惠馨 | 資科碩一 | 110753135 | Dashboard | Hsin0705 |
| 吳仁凱 | 資科碩一 | 110753157 | Pyspark(數據處理與分析)、github程式碼說明 | k0341055 |
| 張修誠 | 資科碩一 | 110753165 | 爬蟲 | juzowa |
| 吳泓澈 | 資科碩一 | 107306009 | InfluxDB | Hunter107306009 |