若只需要找到Frequent Itemsets,輸入以下指令到命令提示字元:
$ java -jar Apriori.jar [dataset file path] [minimum support]
若同時需要找到Association Rule,則須加上[minimum confidence]參數:
$ java -jar Apriori.jar [dataset file path] [minimum support] [minimum confidence]
若需要將找到的結果輸出到一個文字檔中,則須加上 > [output file]:
$ java -jar Apriori.jar ... > [output file]
下圖為範例示意截圖

在開發中,比較多的時間都在思考應該用什麼樣的方式才能最大限度地減少執行時間及記憶體,所以使用了
而在實作Support Counting時,因為時間關係,我沒有來得及實作Candidate Hash Tree。我的作法是將每一筆候選都進行排序,這樣它們在和一開始就先排序好的transactions之間比對時,就不需要原本的
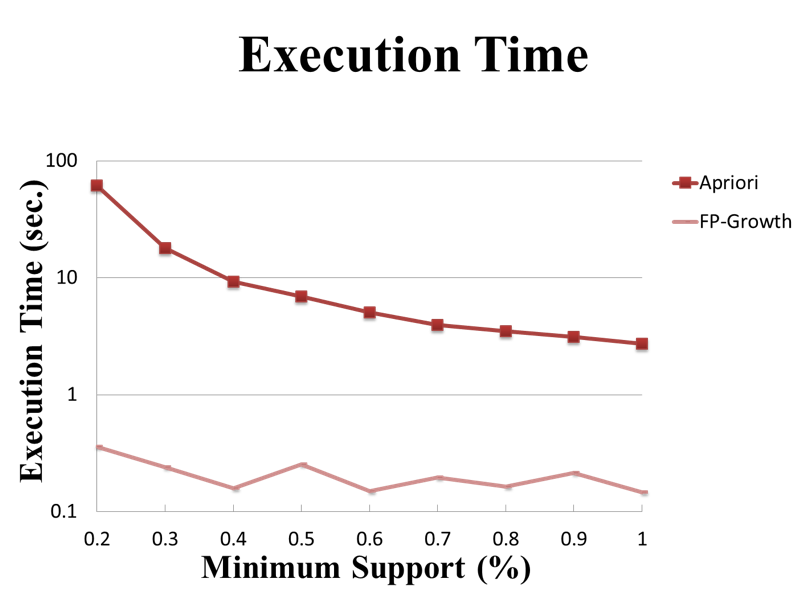
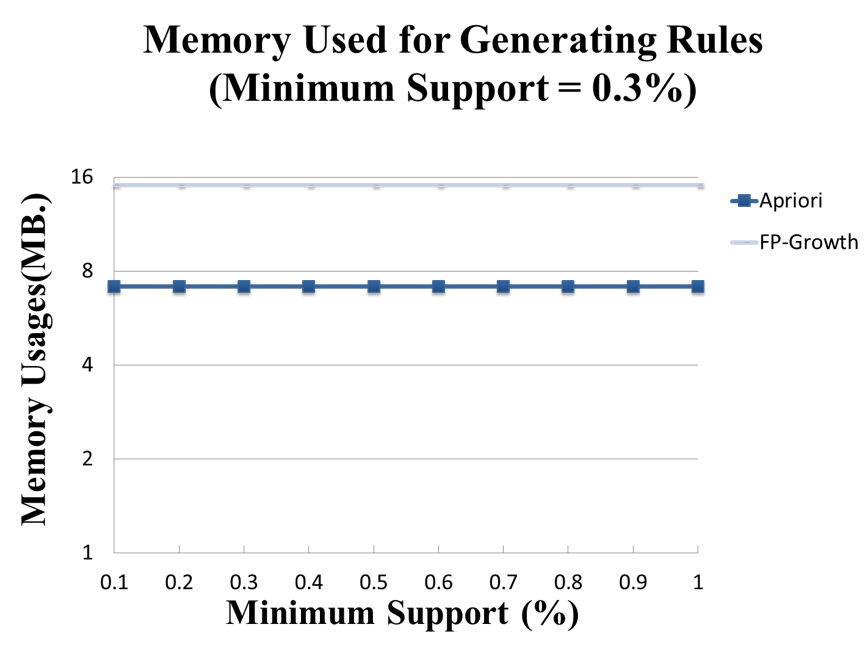
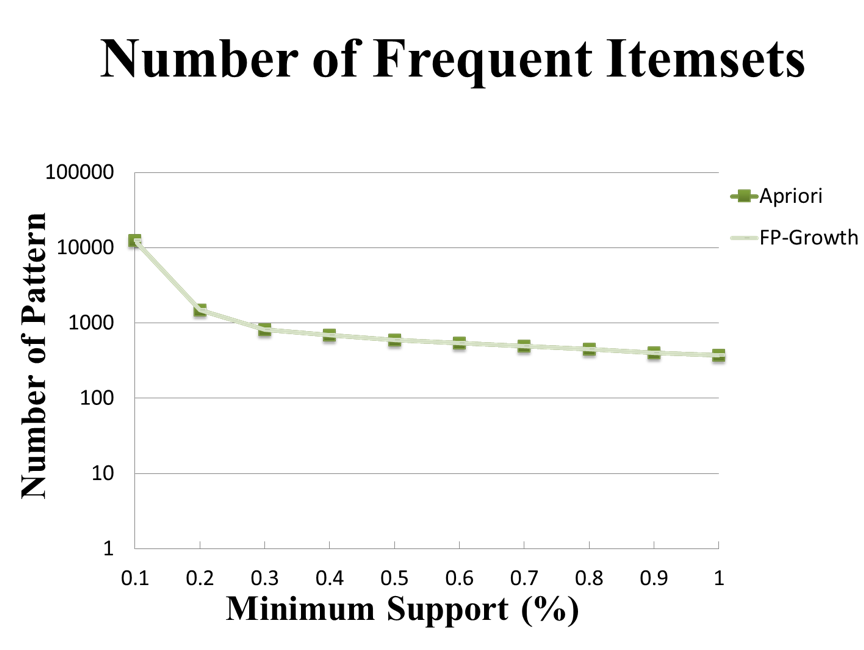
這裡的實驗結果會和FP-Growth�實作的表現進行比較。