Demo for the paper (Now upgraded to Pytorch, for the Lua-Torch version please see commit).
Visual Dialog (CVPR 2017 Spotlight)
Abhishek Das, Satwik Kottur, Khushi Gupta, Avi Singh, Deshraj Yadav, José M. F. Moura, Devi Parikh, Dhruv Batra
Arxiv Link: arxiv.org/abs/1611.08669
Live demo: http://visualchatbot.cloudcv.org
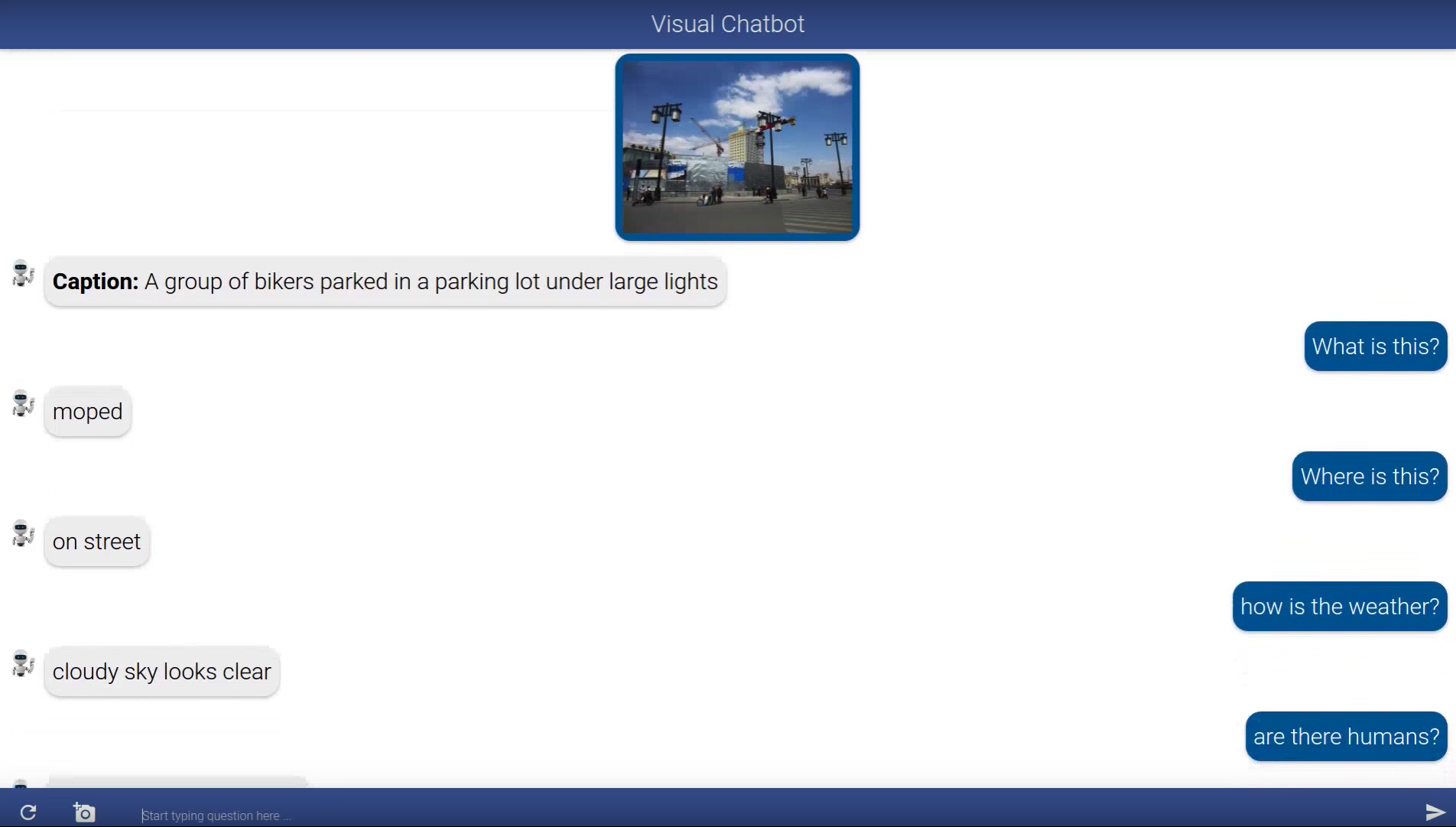
Visual Dialog requires an AI agent to hold a meaningful dialog with humans in natural, conversational language about visual content. Given an image, dialog history, and a follow-up question about the image, the AI agent has to answer the question. Putting it all together, we demonstrate the first ‘visual chatbot’!
The model-building code is completely shifted to Pytorch, we have put in a much improved Bottom Up Top Down captioning model from Pythia and Mask-RCNN feature extractor from maskrcnn-benchmark. The Visdial model is borrowed from visdial-challenge-starter code.
Please follow the instructions below to get the demo running on your local machine. For the previous version of this repository which supports Torch-Lua based models see commit.
Start with installing the Build Essentials , Redis Server and RabbiMQ Server.
sudo apt-get update
# download and install build essentials
sudo apt-get install -y git python-pip python-dev
sudo apt-get install -y autoconf automake libtool
sudo apt-get install -y libgflags-dev libgoogle-glog-dev liblmdb-dev
sudo apt-get install -y libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler
# download and install redis-server and rabbitmq-server
sudo apt-get install -y redis-server rabbitmq-server
sudo rabbitmq-plugins enable rabbitmq_management
sudo service rabbitmq-server restart
sudo service redis-server restartYou can use Anaconda or Miniconda to setup this code base. Download and install Anaconda or Miniconda distribution based on Python3+ from their downloads page and proceed below.
# clone and download submodules
git clone https://github.com/Cloud-CV/visual-chatbot.git
git submodule update init --recursive
# create and activate new environment
conda create -n vischat python=3.6.8
conda activate vischat
# install the requirements of chatbot and visdial-starter code
cd visual-chatbot/
pip install -r requirements.txtDownload the BUTD, Mask-RCNN and VisDial model checkpoints and their configuration files.
sh viscap/download_models.shInstall Pythia to use BUTD captioning model and maskrcnn-benchmark for feature extraction.
# install fastText (dependency of pythia)
cd viscap/captioning/fastText
pip install -e .
# install pythia for using butd model
cd ../pythia/
sed -i '/torch/d' requirements.txt
pip install -e .
# install maskrcnn-benchmark for feature extraction
cd ../vqa-maskrcnn-benchmark/
python setup.py build
python setup.py develop
cd ../../../Note: CUDA and cuDNN is only required if you are going to use GPU. Download and install CUDA and cuDNN from nvidia website.
We use PunktSentenceTokenizer from nltk, download it if you haven't already.
python -c "import nltk; nltk.download('punkt')"# create the database
python manage.py makemigrations chat
python manage.py migrate
Launch two separate terminals and run worker and server code.
# run rabbitmq worker on first terminal
# warning: on the first-run glove file ~ 860 Mb is downloaded, this is a one-time thing
python worker_viscap.py
# run development server on second terminal
python manage.py runserverYou are all set now. Visit http://127.0.0.1:8000 and you will have your demo running successfully.
If you run into incompatibility issues, please take a look here and here.
Performance on v1.0 test-std (trained on v1.0 train + val):
| Model | R@1 | R@5 | R@10 | MeanR | MRR | NDCG |
|---|---|---|---|---|---|---|
| lf-gen-mask-rcnn-x101-demo | 0.3930 | 0.5757 | 0.6404 | 18.4950 | 0.4863 | 0.5967 |
Extracted features from VisDial v1.0 used to train the above model are here:
- features_mask_rcnn_x101_train.h5: Mask-RCNN features with 100 proposals per image train split.
- features_mask_rcnn_x101_val.h5: Mask-RCNN features with 100 proposals per image val split.
- features_mask_rcnn_x101_test.h5: Mask-RCNN features with 100 proposals per image test split.
Note: Above features have key image_id (from earlier versions) renamed as image_ids.
If you find this code useful, consider citing our work:
@inproceedings{visdial,
title={{V}isual {D}ialog},
author={Abhishek Das and Satwik Kottur and Khushi Gupta and Avi Singh
and Deshraj Yadav and Jos\'e M.F. Moura and Devi Parikh and Dhruv Batra},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2017}
}
- Rishabh Jain (rishabhjain@gatech.edu)
- Yash Kant (ysh.kant@gmail.com)
- Deshraj Yadav (deshraj@gatech.edu)
- Abhishek Das (abhshkdz@gatech.edu)
BSD
- Visual Chatbot Image: "Robot-clip-art-book-covers-feJCV3-clipart" by Wikimedia Commons is licensed under CC BY-SA 4.0
- The beam-search implementation was borrowed as it is from AllenNLP.
- The vqa-maskrcnn-benchmark code used was forked from @meetshah1995's fork of the original repository.
- The VisDial model is borrowed from visdial-starter-challenge .
- The BUTD captioning model comes from this awesome repository Pythia.