![]()


Kryo is a fast and efficient binary object graph serialization framework for Java. The goals of the project are high speed, low size, and an easy to use API. The project is useful any time objects need to be persisted, whether to a file, database, or over the network.
Kryo can also perform automatic deep and shallow copying/cloning. This is direct copying from object to object, not object to bytes to object.
This documentation is for Kryo version 5.x. See the Wiki for version 4.x.
Please use the Kryo mailing list for questions, discussions, and support. Please limit use of the Kryo issue tracker to bugs and enhancements, not questions, discussions, or support
- Recent releases
- Installation
- Quickstart
- IO
- Reading and writing objects
- Serializer framework
- Implementing a serializer
- Kryo versioning and upgrading
- Interoperability
- Compatibility
- Serializers
- Logging
- Thread safety
- Benchmarks
- Links
- 4.0.3 - brings bug fixes and performance improvements for chunked encoding.
- 5.6.0 - brings bug fixes and performance improvements.
- 5.5.0 - brings bug fixes and performance improvements.
- 5.4.0 - brings bug fixes and performance improvements.
- 5.3.0 - brings bug fixes and performance improvements.
- 5.2.1 - brings minor bug fixes and improvements.
- 5.2.0 - brings bug fixes for
RecordSerializerand improvements. Important: If you are currently storing serializedjava.util.Record, please see the release notes for upgrade instructions. - 5.1.1 - brings bug fixes for
CompatibleFieldSerializerand removes dependency from versioned artifact - 5.1.0 - brings support for
java.util.Recordand improved support for older Android versions - 5.0.0 - the final Kryo 5 release fixing many issues and making many long awaited improvements over Kryo 4. Note: For libraries (not applications) using Kryo, there's now a completely self-contained, versioned artifact (for details see installation). For migration from Kryo 4.x see also Migration to v5.
Kryo publishes two kinds of artifacts/jars:
- the default jar (with the usual library dependencies) which is meant for direct usage in applications (not libraries)
- a dependency-free, "versioned" jar which should be used by other libraries. Different libraries shall be able to use different major versions of Kryo.
Kryo JARs are available on the releases page and at Maven Central. The latest snapshots of Kryo, including snapshot builds of master, are in the Sonatype Repository.
To use the latest Kryo release in your application, use this dependency entry in your pom.xml:
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.6.0</version>
</dependency>To use the latest Kryo release in a library you want to publish, use this dependency entry in your pom.xml:
<dependency>
<groupId>com.esotericsoftware.kryo</groupId>
<artifactId>kryo5</artifactId>
<version>5.6.0</version>
</dependency>To use the latest Kryo snapshot, use:
<repository>
<id>sonatype-snapshots</id>
<name>sonatype snapshots repo</name>
<url>https://oss.sonatype.org/content/repositories/snapshots</url>
</repository>
<!-- for usage in an application: -->
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.6.1-SNAPSHOT</version>
</dependency>
<!-- for usage in a library that should be published: -->
<dependency>
<groupId>com.esotericsoftware.kryo</groupId>
<artifactId>kryo5</artifactId>
<version>5.6.1-SNAPSHOT</version>
</dependency>Not everyone is a Maven fan. Using Kryo without Maven requires placing the Kryo JAR on your classpath along with the dependency JARs found in lib.
Building Kryo from source requires JDK11+ and Maven. To build all artifacts, run:
mvn clean && mvn install
Jumping ahead to show how the library can be used:
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;
import java.io.*;
public class HelloKryo {
static public void main (String[] args) throws Exception {
Kryo kryo = new Kryo();
kryo.register(SomeClass.class);
SomeClass object = new SomeClass();
object.value = "Hello Kryo!";
Output output = new Output(new FileOutputStream("file.bin"));
kryo.writeObject(output, object);
output.close();
Input input = new Input(new FileInputStream("file.bin"));
SomeClass object2 = kryo.readObject(input, SomeClass.class);
input.close();
}
static public class SomeClass {
String value;
}
}The Kryo class performs the serialization automatically. The Output and Input classes handle buffering bytes and optionally flushing to a stream.
The rest of this document details how this works and advanced usage of the library.
Getting data in and out of Kryo is done using the Input and Output classes. These classes are not thread safe.
The Output class is an OutputStream that writes data to a byte array buffer. This buffer can be obtained and used directly, if a byte array is desired. If the Output is given an OutputStream, it will flush the bytes to the stream when the buffer becomes full, otherwise Output can grow its buffer automatically. Output has many methods for efficiently writing primitives and strings to bytes. It provides functionality similar to DataOutputStream, BufferedOutputStream, FilterOutputStream, and ByteArrayOutputStream, all in one class.
Tip: Output and Input provide all the functionality of ByteArrayOutputStream. There is seldom a reason to have Output flush to a ByteArrayOutputStream.
Output buffers the bytes when writing to an OutputStream, so flush or close must be called after writing is complete to cause the buffered bytes to be written to the OutputStream. If the Output has not been provided an OutputStream, calling flush or close is unnecessary. Unlike many streams, an Output instance can be reused by setting the position, or setting a new byte array or stream.
Tip: Since Output buffers already, there is no reason to have Output flush to a BufferedOutputStream.
The zero argument Output constructor creates an uninitialized Output. Output setBuffer must be called before the Output can be used.
The Input class is an InputStream that reads data from a byte array buffer. This buffer can be set directly, if reading from a byte array is desired. If the Input is given an InputStream, it will fill the buffer from the stream when all the data in the buffer has been read. Input has many methods for efficiently reading primitives and strings from bytes. It provides functionality similar to DataInputStream, BufferedInputStream, FilterInputStream, and ByteArrayInputStream, all in one class.
Tip: Input provides all the functionality of ByteArrayInputStream. There is seldom a reason to have Input read from a ByteArrayInputStream.
If the Input close is called, the Input's InputStream is closed, if any. If not reading from an InputStream then it is not necessary to call close. Unlike many streams, an Input instance can be reused by setting the position and limit, or setting a new byte array or InputStream.
The zero argument Input constructor creates an uninitialized Input. Input setBuffer must be called before the Input can be used.
The ByteBufferOutput and ByteBufferInput classes work exactly like Output and Input, except they use a ByteBuffer rather than a byte array.
The UnsafeOutput, UnsafeInput, UnsafeByteBufferOutput, and UnsafeByteBufferInput classes work exactly like their non-unsafe counterparts, except they use sun.misc.Unsafe for higher performance in many cases. To use these classes Util.unsafe must be true.
The downside to using unsafe buffers is that the native endianness and representation of numeric types of the system performing the serialization affects the serialized data. For example, deserialization will fail if the data is written on X86 and read on SPARC. Also, if data is written with an unsafe buffer, it must be read with an unsafe buffer.
The biggest performance difference with unsafe buffers is with large primitive arrays when variable length encoding is not used. Variable length encoding can be disabled for the unsafe buffers or only for specific fields (when using FieldSerializer).
The IO classes provide methods to read and write variable length int (varint) and long (varlong) values. This is done by using the 8th bit of each byte to indicate if more bytes follow, which means a varint uses 1-5 bytes and a varlong uses 1-9 bytes. Using variable length encoding is more expensive but makes the serialized data much smaller.
When writing a variable length value, the value can be optimized either for positive values or for both negative and positive values. For example, when optimized for positive values, 0 to 127 is written in one byte, 128 to 16383 in two bytes, etc. However, small negative numbers are the worst case at 5 bytes. When not optimized for positive, these ranges are shifted down by half. For example, -64 to 63 is written in one byte, 64 to 8191 and -65 to -8192 in two bytes, etc.
Input and Output buffers provides methods to read and write fixed sized or variable length values. There are also methods to allow the buffer to decide whether a fixed size or variable length value is written. This allows serialization code to ensure variable length encoding is used for very common values that would bloat the output if a fixed size were used, while still allowing the buffer configuration to decide for all other values.
| Method | Description |
|---|---|
| writeInt(int) | Writes a 4 byte int. |
| writeVarInt(int, boolean) | Writes a 1-5 byte int. |
| writeInt(int, boolean) | Writes either a 4 or 1-5 byte int (the buffer decides). |
| writeLong(long) | Writes an 8 byte long. |
| writeVarLong(long, boolean) | Writes an 1-9 byte long. |
| writeLong(long, boolean) | Writes either an 8 or 1-9 byte long (the buffer decides). |
To disable variable length encoding for all values, the writeVarInt, writeVarLong, readVarInt, and readVarLong methods would need to be overridden.
It can be useful to write the length of some data, then the data. When the length of the data is not known ahead of time, all the data needs to be buffered to determine its length, then the length can be written, then the data. using a single, large buffer for this would prevent streaming and may require an unreasonably large buffer, which is not ideal.
Chunked encoding solves this problem by using a small buffer. When the buffer is full, its length is written, then the data. This is one chunk of data. The buffer is cleared and this continues until there is no more data to write. A chunk with a length of zero denotes the end of the chunks.
Kryo provides classes to make chunked encoding easy to use. OutputChunked is used to write chunked data. It extends Output, so has all the convenient methods to write data. When the OutputChunked buffer is full, it flushes the chunk to another OutputStream. The endChunk method is used to mark the end of a set of chunks.
OutputStream outputStream = new FileOutputStream("file.bin");
OutputChunked output = new OutputChunked(outputStream, 1024);
// Write data to output...
output.endChunk();
// Write more data to output...
output.endChunk();
// Write even more data to output...
output.endChunk();
output.close();To read the chunked data, InputChunked is used. It extends Input, so has all the convenient methods to read data. When reading, InputChunked will appear to hit the end of the data when it reaches the end of a set of chunks. The nextChunks method advances to the next set of chunks, even if not all the data has been read from the current set of chunks.
InputStream outputStream = new FileInputStream("file.bin");
InputChunked input = new InputChunked(inputStream, 1024);
// Read data from first set of chunks...
input.nextChunks();
// Read data from second set of chunks...
input.nextChunks();
// Read data from third set of chunks...
input.close();Generally Output and Input provide good performance. Unsafe buffers perform as well or better, especially for primitive arrays, if their crossplatform incompatibilities are acceptable. ByteBufferOutput and ByteBufferInput provide slightly worse performance, but this may be acceptable if the final destination of the bytes must be a ByteBuffer.
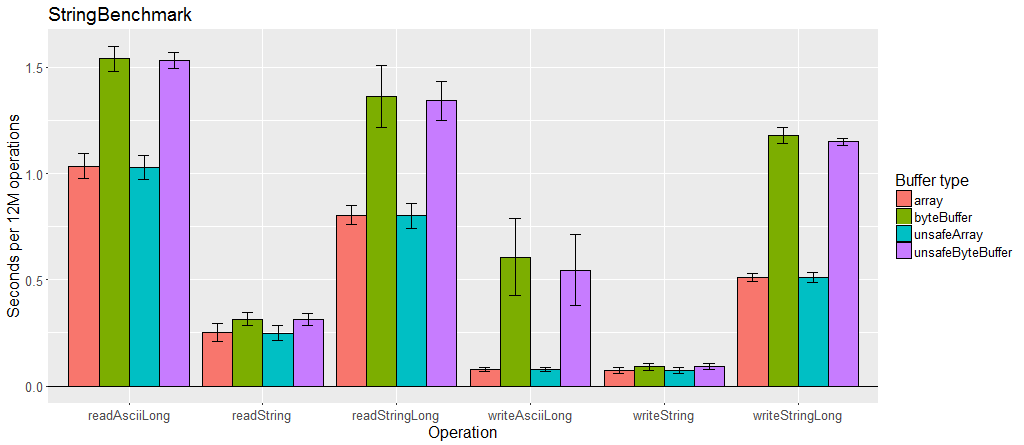
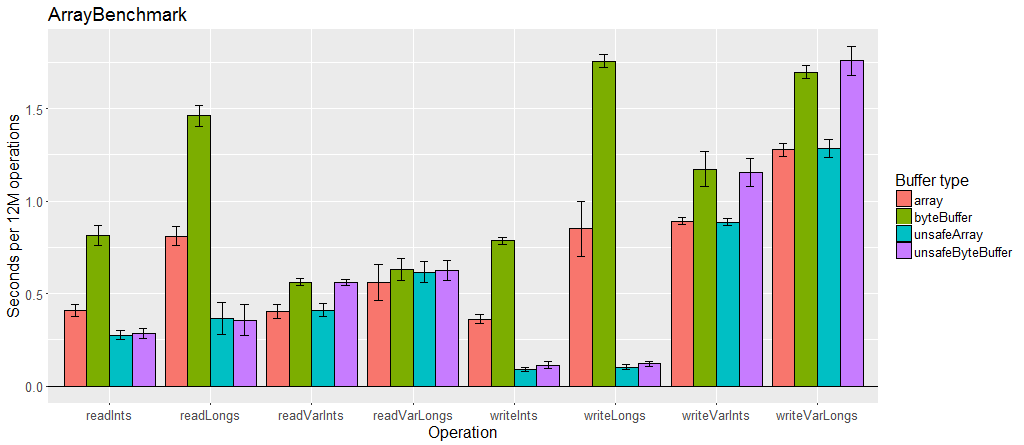
Variable length encoding is slower than fixed values, especially when there is a lot of data using it.
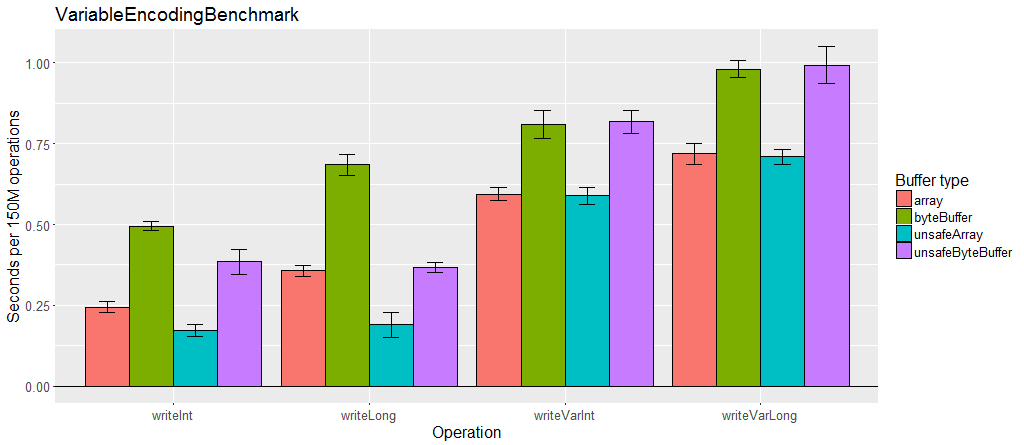
Chunked encoding uses an intermediary buffer so it adds one additional copy of all the bytes. This alone may be acceptable, however when used in a reentrant serializer, the serializer must create an OutputChunked or InputChunked for each object. Allocating and garbage collecting those buffers during serialization can have a negative impact on performance.
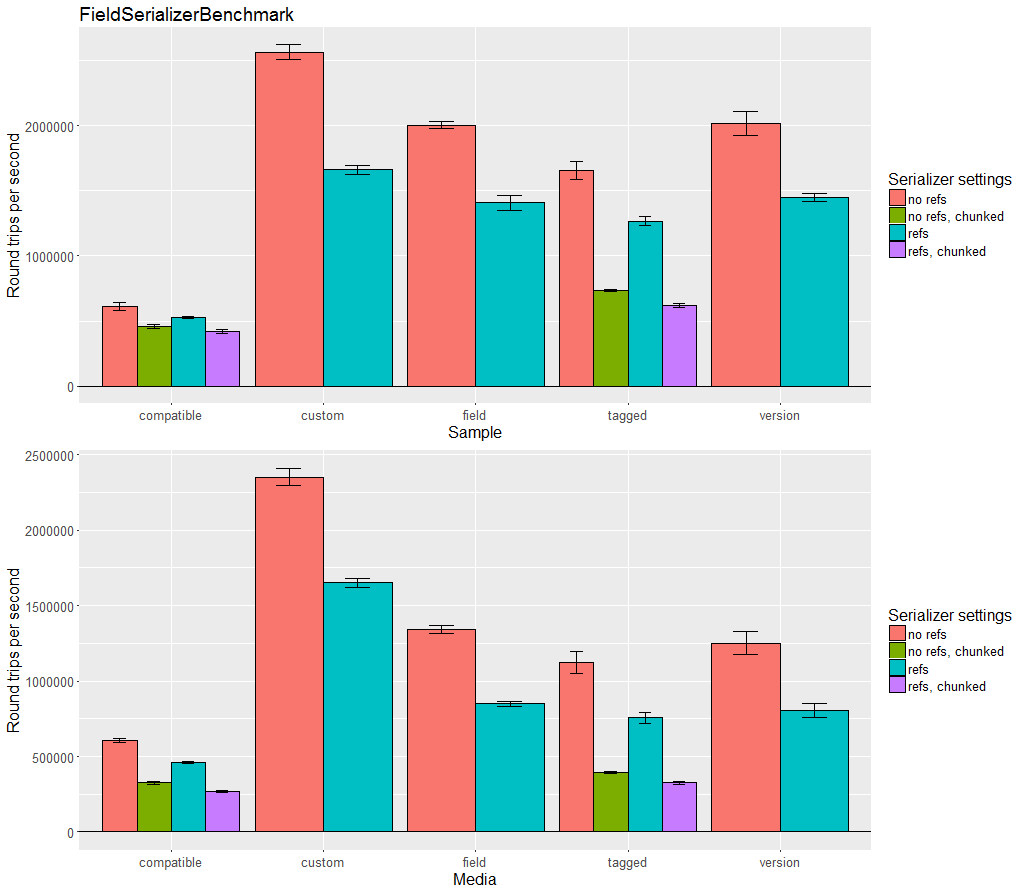
Kryo has three sets of methods for reading and writing objects. If the concrete class of the object is not known and the object could be null:
kryo.writeClassAndObject(output, object);
Object object = kryo.readClassAndObject(input);
if (object instanceof SomeClass) {
// ...
}If the class is known and the object could be null:
kryo.writeObjectOrNull(output, object);
SomeClass object = kryo.readObjectOrNull(input, SomeClass.class);If the class is known and the object cannot be null:
kryo.writeObject(output, object);
SomeClass object = kryo.readObject(input, SomeClass.class);All of these methods first find the appropriate serializer to use, then use that to serialize or deserialize the object. Serializers can call these methods for recursive serialization. Multiple references to the same object and circular references are handled by Kryo automatically.
Besides methods to read and write objects, the Kryo class provides a way to register serializers, reads and writes class identifiers efficiently, handles null objects for serializers that can't accept nulls, and handles reading and writing object references (if enabled). This allows serializers to focus on their serialization tasks.
While testing and exploring Kryo APIs, it can be useful to write an object to bytes, then read those bytes back to an object.
Kryo kryo = new Kryo();
// Register all classes to be serialized.
kryo.register(SomeClass.class);
SomeClass object1 = new SomeClass();
Output output = new Output(1024, -1);
kryo.writeObject(output, object1);
Input input = new Input(output.getBuffer(), 0, output.position());
SomeClass object2 = kryo.readObject(input, SomeClass.class);In this example the Output starts with a buffer that has a capacity of 1024 bytes. If more bytes are written to the Output, the buffer will grow in size without limit. The Output does not need to be closed because it has not been given an OutputStream. The Input reads directly from the Output's byte[] buffer.
Kryo supports making deep and shallow copies of objects using direct assignment from one object to another. This is more efficient than serializing to bytes and back to objects.
Kryo kryo = new Kryo();
SomeClass object = ...
SomeClass copy1 = kryo.copy(object);
SomeClass copy2 = kryo.copyShallow(object);All the serializers being used need to support copying. All serializers provided with Kryo support copying.
Like with serialization, when copying, multiple references to the same object and circular references are handled by Kryo automatically if references are enabled.
If using Kryo only for copying, registration can be safely disabled.
Kryo getOriginalToCopyMap can be used after an object graph is copied to obtain a map of old to new objects. The map is cleared automatically by Kryo reset, so is only useful when Kryo setAutoReset is false.
By default references are not enabled. This means if an object appears in an object graph multiple times, it will be written multiple times and will be deserialized as multiple, different objects. When references are disabled, circular references will cause serialization to fail. References are enabled or disabled with Kryo setReferences for serialization and setCopyReferences for copying.
When references are enabled, a varint is written before each object the first time it appears in the object graph. For subsequent appearances of that class within the same object graph, only a varint is written. After deserialization the object references are restored, including any circular references. The serializers in use must support references by calling Kryo reference in Serializer read.
Enabling references impacts performance because every object that is read or written needs to be tracked.
Under the covers, a ReferenceResolver handles tracking objects that have been read or written and provides int reference IDs. Multiple implementations are provided:
- MapReferenceResolver is used by default if a reference resolver is not specified. It uses Kryo's IdentityObjectIntMap (a cuckoo hashmap) to track written objects. This kind of map has very fast gets and does not allocate for put, but puts for very large numbers of objects can be somewhat slow.
- HashMapReferenceResolver uses a HashMap to track written objects. This kind of map allocates for put but may provide better performance for object graphs with a very high number of objects.
- ListReferenceResolver uses an ArrayList to track written objects. For object graphs with relatively few objects, this can be faster than using a map (~15% faster in some tests). This should not be used for graphs with many objects because it has a linear look up to find objects that have already been written.
ReferenceResolver useReferences(Class) can be overridden. It returns a boolean to decide if references are supported for a class. If a class doesn't support references, the varint reference ID is not written before objects of that type. If a class does not need references and objects of that type appear in the object graph many times, the serialized size can be greatly reduced by disabling references for that class. The default reference resolver returns false for all primitive wrappers and enums. It is common to also return false for String and other classes, depending on the object graphs being serialized.
public boolean useReferences (Class type) {
return !Util.isWrapperClass(type) && !Util.isEnum(type) && type != String.class;
}The reference resolver determines the maximum number of references in a single object graph. Java array indices are limited to Integer.MAX_VALUE, so reference resolvers that use data structures based on arrays may result in a java.lang.NegativeArraySizeException when serializing more than ~2 billion objects. Kryo uses int class IDs, so the maximum number of references in a single object graph is limited to the full range of positive and negative numbers in an int (~4 billion).
Kryo getContext returns a map for storing user data. The Kryo instance is available to all serializers, so this data is easily accessible to all serializers.
Kryo getGraphContext is similar, but is cleared after each object graph is serialized or deserialized. This makes it easy to manage state that is only relevant for the current object graph. For example, this can be used to write some schema data the first time a class is encountered in an object graph. See CompatibleFieldSerializer for an example.
By default, Kryo reset is called after each entire object graph is serialized. This resets unregistered class names in the class resolver, references to previously serialized or deserialized objects in the reference resolver, and clears the graph context. Kryo setAutoReset(false) can be used to disable calling reset automatically, allowing that state to span multiple object graphs.
Kryo is a framework to facilitate serialization. The framework itself doesn't enforce a schema or care what or how data is written or read. Serializers are pluggable and make the decisions about what to read and write. Many serializers are provided out of the box to read and write data in various ways. While the provided serializers can read and write most objects, they can easily be replaced partially or completely with your own serializers.
When Kryo goes to write an instance of an object, first it may need to write something that identifies the object's class. By default, all classes that Kryo will read or write must be registered beforehand. Registration provides an int class ID, the serializer to use for the class, and the object instantiator used to create instances of the class.
Kryo kryo = new Kryo();
kryo.register(SomeClass.class);
Output output = ...
SomeClass object = ...
kryo.writeObject(output, object);During deserialization, the registered classes must have the exact same IDs they had during serialization. When registered, a class is assigned the next available, lowest integer ID, which means the order classes are registered is important. The class ID can optionally be specified explicitly to make order unimportant:
Kryo kryo = new Kryo();
kryo.register(SomeClass.class, 9);
kryo.register(AnotherClass.class, 10);
kryo.register(YetAnotherClass.class, 11);Class IDs -1 and -2 are reserved. Class IDs 0-8 are used by default for primitive types and String, though these IDs can be repurposed. The IDs are written as positive optimized varints, so are most efficient when they are small, positive integers. Negative IDs are not serialized efficiently.