language:中文
- sklearn
- python3.6
- Ubuntu18.04
-
不同之处在于: 文章里用的L-M 算法作为训练算法,我采用的是sklearn中现成的算法,在加大样本量后(从700多到6000多),epoch(max_iter)=2500,训练算法采用"adam",得分率去到0.95067...
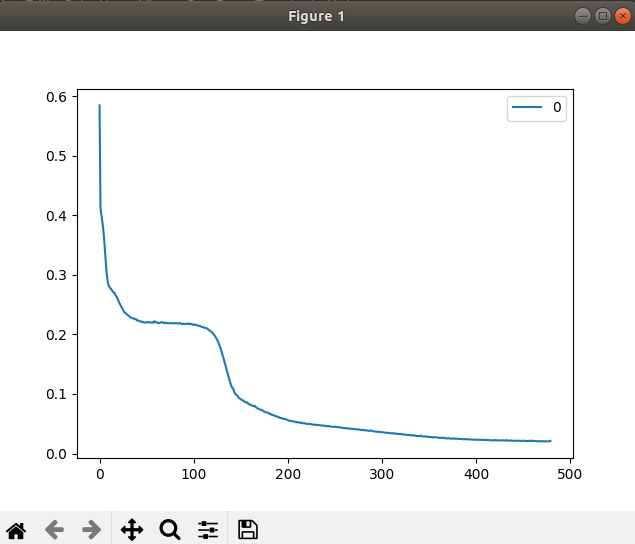
-
维持低样本量时,max_iter=2500,采用"lbfgs",得分率可去到0.96....

- 样本量低时请使用“lbfgs”;
- 训练数据一定要进行正则化,使其变化到[-1,1]之间;
- 受限与sklearn的nn网络设置的影响,只能对adam画出损失函数的图像。后续可考虑采用TensorFlow
- 损失函数中部分概念还不清楚。需要进一步学习。