Source code for EMNLP 2020 paper: Double Graph Based Reasoning for Document-level Relation Extraction
Document-level relation extraction aims to extract relations among entities within a document. Different from sentence-level relation extraction, it requires reasoning over multiple sentences across a document. In this paper, we propose Graph Aggregation-and-Inference Network (GAIN) featuring double graphs. GAIN first constructs a heterogeneous mention-level graph (hMG) to model complex interaction among different mentions across the document. It also constructs an entity-level graph (EG), based on which we propose a novel path reasoning mechanism to infer relations between entities. Experiments on the public dataset, DocRED, show GAIN achieves a significant performance improvement (2.85 on F1) over the previous state-of-the-art.
-
Architecture
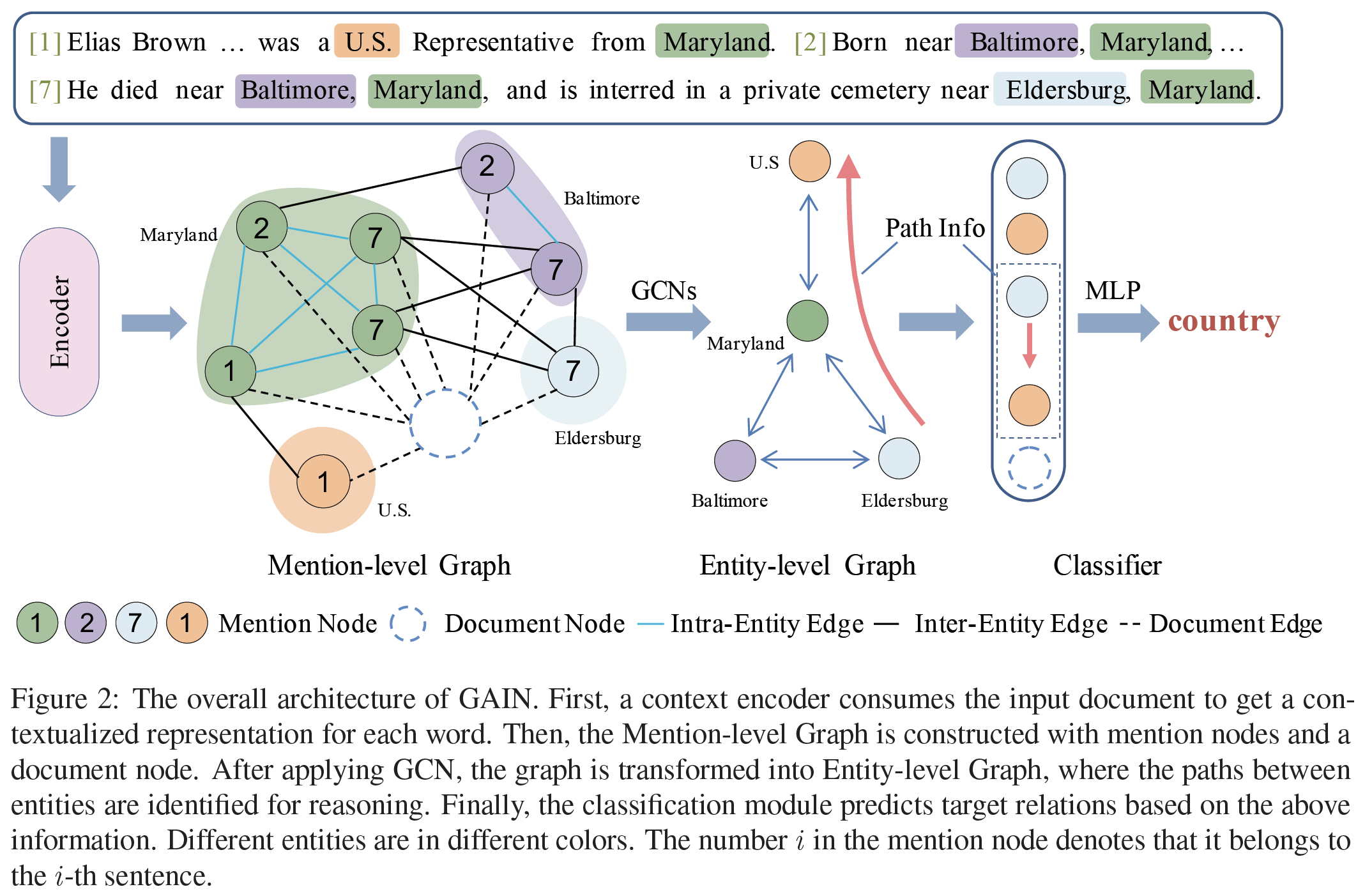
-
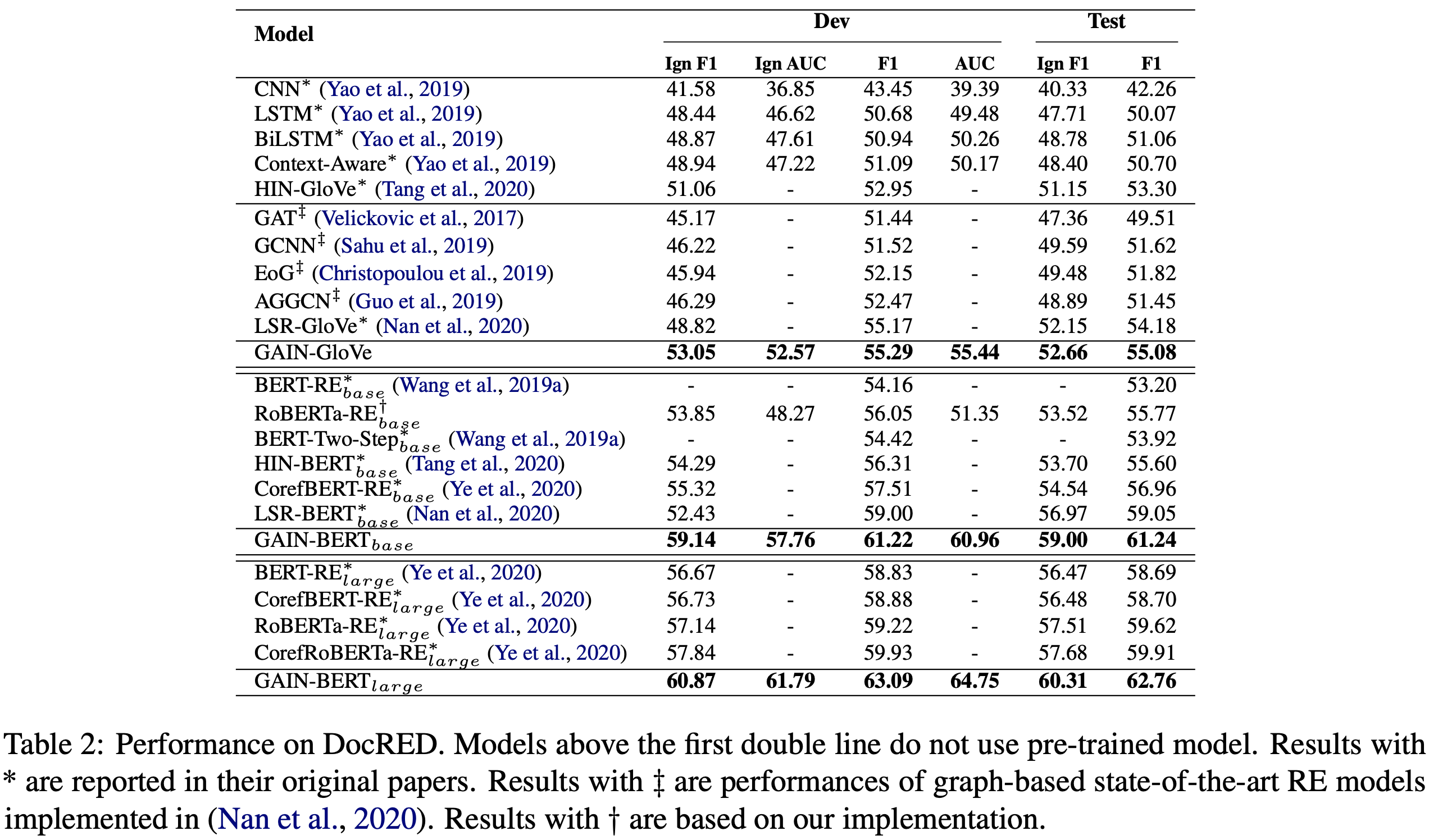
Overall Results


GAIN/
├─ code/
├── checkpoint/: save model checkpoints
├── fig_result/: plot AUC curves
├── logs/: save training / evaluation logs
├── models/:
├── GAIN.py: GAIN model for GloVe or BERT version
├── GAIN_nomention.py: GAIN model for -hMG ablation
├── config.py: process command arguments
├── data.py: define Datasets / Dataloader for GAIN-GloVe or GAIN-BERT
├── test.py: evaluation code
├── train.py: training code
├── utils.py: some tools for training / evaluation
├── *.sh: training / evaluation shell scripts
├─ data/: raw data and preprocessed data about DocRED dataset
├── prepro_data/
├── README.md
├─ PLM/: save pre-trained language models such as BERT_base / BERT_lagrge
├── bert-base-uncased/
├── bert-large-uncased/
├─ test_result_jsons/: save test result jsons
├─ LICENSE
├─ README.md
- python (3.7.4)
- cuda (10.2)
- Ubuntu-18.0.4 (4.15.0-65-generic)
- numpy (1.19.2)
- matplotlib (3.3.2)
- torch (1.6.0)
- transformers (3.1.0)
- dgl-cu102 (0.4.3)
- scikit-learn (0.23.2)
PS: dgl >= 0.5 is not compatible with our code, we will fix this compatibility problem in the future.
-
Download data from Google Drive link shared by DocRED authors
-
Put
train_annotated.json,dev.json,test.json,word2id.json,ner2id.json,rel2id.json,vec.npyinto the directorydata/ -
If you want to use other datasets, please first process them to fit the same format as DocRED.
Following the hint in this link, download possible required files (pytorch_model.bin, config.json, vocab.txt, etc.) into the directory PLM/bert-????-uncased such as PLM/bert-base-uncased.
>> cd code
>> ./runXXX.sh gpu_id # like ./run_GAIN_BERT.sh 2
>> tail -f -n 2000 logs/train_xxx.log>> cd code
>> ./evalXXX.sh gpu_id threshold(optional) # like ./eval_GAIN_BERT.sh 0 0.5521
>> tail -f -n 2000 logs/test_xxx.logPS: we recommend to use threshold = -1 (which is the default, you can omit this arguments at this time) for dev set, the log will print the optimal threshold in dev set, and you can use this optimal value as threshold to evaluate test set.
-
You will get json output file for test set at step 5.
-
And then you can rename it as
result.jsonand compress it asresult.zip. -
At last, you can submit the
result.zipto CodaLab.
This project is licensed under the MIT License - see the LICENSE file for details.
If you use this work or code, please kindly cite the following paper:
@inproceedings{zeng-etal-2020-gain,
title = "Double Graph Based Reasoning for Document-level Relation Extraction",
author = "Zeng, Shuang and
Xu, Runxin and
Chang, Baobao and
Li, Lei",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
year = "2020",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.127",
pages = "1630--1640",
}If you have any questions, please feel free to contact Shuang Zeng, we will reply it as soon as possible.