SDU《信息检索》课程设计,Cooapk应用列表爬取+索引构建+搜索引擎查询练习程序
| Author | Collapsar-G |
|---|---|
| collapsar@gmail.xiheye.club |
-
- Web网页信息抽取 以Coolapk官网为起点进行遍历爬取,保持爬虫在 https://www.coolapk.com/apk/ 之内(即只爬取这个站点的网页),爬取的网页数量越多越好。
-
- 索引构建 对上一步爬取到的网页进行结构化预处理,包括基于模板的信息抽取、分字段解析、分词、构建索引等。抽取的主要内容是酷安网中手机app的简介、新版特性、应用标签、评分等内容,并根据此内容建立索引。
-
- 检索排序 对上一步构建的索引库进行查询,对于给定的查询,给出检索结果。
-
- 图形界面 利用VUE vuetify框架搭建web界面
-search:相关度算法
-index:倒排索引表
-Spider:爬虫
-stopwords:停用词表
-web:vue前端
- scrapy
- requests
- jieba
- flask
- MySQL
- Navicat Premium 15 可视化工具(可选)
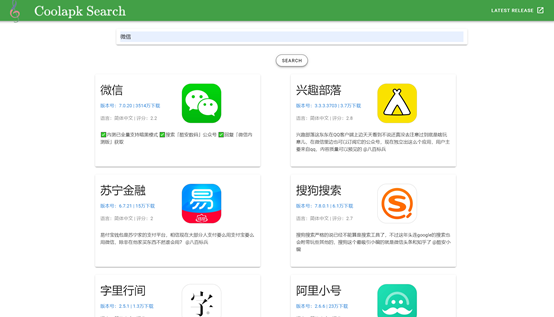
- 先对coolapk首页爬取,爬取了2375条apk的url;
- 对步骤一爬取的url进一步爬取,爬取了2344条数据;
- 分别对爬取的apk名字、点评、详情进行分词并建立倒排索引表;
- 利用倒排索引表计算相关度,apk名字、点评、详情权重分别为0.5、0.3、0.2;
- 利用flask建立后端api;
- 利用vue搭建前端界面;
- 计划中的热榜没有完成;
- 时间仓促,前端界面比较简陋,等考试周结束继续优化;
- 在第二步爬取的时候由于防注入,带有超链接的文本无法输入数据库,所以放弃数据;
- 相关度算法不够完善,计划回头有时间继续优化;
- 运行app.py文件启动后端api;
- 在web目录下命令行运行:npm run serve运行前端;