Support for other languages
yaguangtang opened this issue · 106 comments
Available languages
Chinese (Mandarin): #811
German: #571*
Swedish: #257*
* Requires Tensorflow 1.x (harder to set up).
Requested languages (not available yet)
Arabic: #871
Czech: #655
English: #388 (UK accent), #429 (Indian accent)
French: #854
Hindi: #525
Italian: #697
Polish: #815
Portuguese: #531
Russian: #707
Spanish: #789
Turkish: #761
Ukrainian: #492
You'll need to retrain with your own datasets to get another language running (and it's a lot of work). The speaker encoder is somewhat able to work on a few other languages than English because VoxCeleb is not purely English, but since the synthesizer/vocoder have been trained purely on English data, any voice that is not in English - and even, that does not have a proper English accent - will be cloned very poorly.
Thanks for explaintation, I have big interest of adding other languages support, and would like to contribute.
You'll need a good dataset (at least ~300 hours, high quality and transcripts) in the language of your choice, do you have that?
I wanna train another language. How many speakers do I need in the Encoder? or can I use the English speaker embeddings to my language?
From here:
A particularity of the SV2TTS framework is that all models can be trained
separately and on distinct datasets. For the encoder, one seeks to have a model
that is robust to noise and able to capture the many characteristics of the human
voice. Therefore, a large corpus of many different speakers would be preferable to
train the encoder, without any strong requirement on the noise level of the audios.
Additionally, the encoder is trained with the GE2E loss which requires no labels other
than the speaker identity. (...) For the datasets of the synthesizer and the vocoder,
transcripts are required and the quality of the generated audio can only be as good
as that of the data. Higher quality and annotated datasets are thus required, which
often means they are smaller in size.
You'll need two datasets:

The first one should be a large dataset of untranscribed audio that can be noisy. Think thousands of speakers and thousands of hours. You can get away with a smaller one if you finetune the pretrained speaker encoder. Put maybe 1e-5 as learning rate. I'd recommend 500 speakers at the very least for finetuning. A good source for datasets of other languages is M-AILABS.
The second one needs audio transcripts and high quality audio. Here, finetuning won't be as effective as for the encoder, but you can get away with less data (300-500 hours). You will likely not have the alignments for that dataset, so you'll have to adapt the preprocessing procedure of the synthesizer to not split audio on silences. See the code and you'll understand what I mean.
Don't start training the encoder if you don't have a dataset for the synthesizer/vocoder, you won't be able to do anything then.
You'll need a good dataset (at least ~300 hours, high quality and transcripts) in the language of your choice, do you have that?
Maybe it can be hacked by using audio book and they pdf2text version. The difficult come i guess from the level of expression on data sources. Maybe with some movies but sometimes subtitles are really poor. Firefox work on dataset to if i remember well
You'll need a good dataset (at least ~300 hours, high quality and transcripts) in the language of your choice, do you have that?
Maybe it can be hacked by using audio book and they pdf2text version. The difficult come i guess from the level of expression on data sources. Maybe with some movies but sometimes subtitles are really poor. Firefox work on dataset to if i remember well
This is something that I have been slowly piecing together. I have been gathering audiobooks and their text versions that are in the public domain (Project Gutenberg & LibriVox Recordings). My goal as of now is to develop a solid package that can gather an audiofile and corresponding book, performing necessary cleaning and such.
Currently this project lives on my C:, but if there's interest in collaboration I'd gladly throw it here on GitHub.
How many speakers are needed for synthesizer/vocoder training?
You'd want hundreds of speakers at least. In fact, LibriSpeech-clean makes for 460 speakers and it's still not enough.
There's an open 12-hour Chinese female voice set from databaker that I tried with tacotron https://github.com/boltomli/tacotron/blob/zh/TRAINING_DATA.md#data-baker-data. Hope that I can gather more Chinese speakers to have a try on voice cloning. I'll update if I have some progress.
That's not nearly enough to learn about the variations in speakers. Especially not on a hard language such as Chinese.
@boltomli Take a look at this dataset (1505 hours, 6408 speakers, recorded on smartphones):
https://www.datatang.com/webfront/opensource.html
Samples.zip
Not sure if the quality is good enough for encoder training.
You actually want the encoder dataset not to always be of good quality, because that makes the encoder robust. It's different for the synthesizer/vocoder, because the quality is the output you will have (at best)
You'd want hundreds of speakers at least. In fact, LibriSpeech-clean makes for 460 speakers and it's still not enough.
Can not be hack to by create new speakers with ai like it is done for picture ?
How about training the encoder/speaker_verification using English multi-speaker data-sets, but training the synthesizer using Chinese database, suppose both the data are enough for each individual model separately.
You can do that, but I would then add the synthesizer dataset in the speaker encoder dataset. In SV2TTS, they use disjoint datasets between the encoder and the synthesizer, but I think it's simply to demonstrate that the speaker encoder generalizes well (the paper is presented as a transfer learning paper over a voice cloning paper after all).
There's no guarantee the speaker encoder works well on different languages than it was trained on. Considering the difficulty of generating good Chinese speech, you might want to do your best at finding really good datasets rather than hack your way around everything.
@CorentinJ Thank you for your reply,may be I should find some Chinese data-sets for ASR to train the speaker verification model.
@Liujingxiu23 Have you trained a Chinese model?And could you share your model about the Chinese clone results?
@magneter I have not trained the Chinese model, I don't have enough data to train the speaker verification model, I am trying to collect suitable data now
You'd want hundreds of speakers at least. In fact, LibriSpeech-clean makes for 460 speakers and it's still not enough.
@CorentinJ Hello, ignoring speakers out of training dataset, if I only want to assure the quality and similarity of wav synthesized with speakers in the training dataset(librispeech-clean), how much time (at least) for one speaker do I need for training, maybe 20 minutes or less?
maybe 20 minutes or less?
Wouldn't that be wonderful. You'll still need a good week or so. A few hours if you use the pretrained model. Although at this point what you're doing is no longer voice cloning, so you're not really in the right repo for that.
This is something that I have been slowly piecing together. I have been gathering audiobooks and their text versions that are in the public domain (Project Gutenberg & LibriVox Recordings). My goal as of now is to develop a solid package that can gather an audiofile and corresponding book, performing necessary cleaning and such.
Currently this project lives on my C:, but if there's interest in collaboration I'd gladly throw it here on GitHub.
@zbloss I'm very interested. Would you be able to upload your entire dataset somewhere? Or if it's difficult to upload, is there some way I could acquire it from you directly?
Thanks!
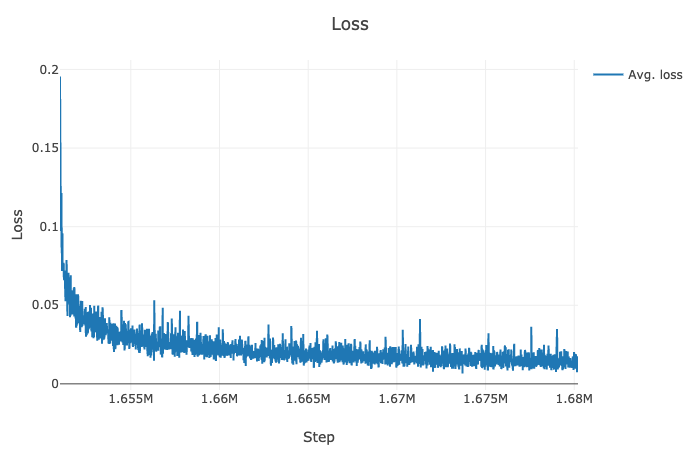
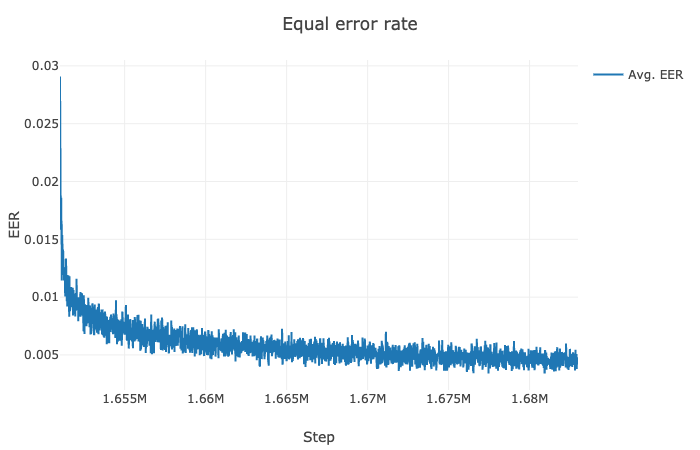
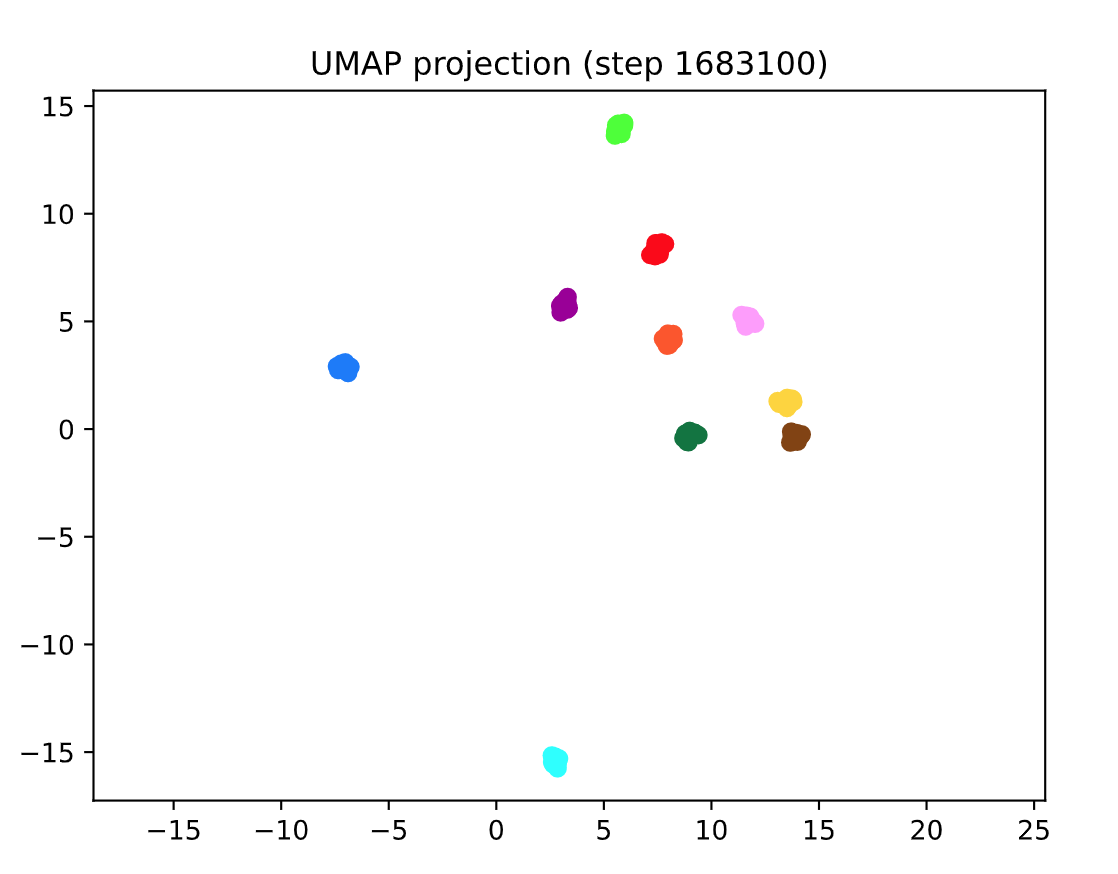
@CorentinJ @yaguangtang @tail95 @zbloss @HumanG33k I am finetuning the encoder model by Chhinese data of 3100 persons. I want to know how to judge whether the train of finetune is OK. In Figure0, The blue line is based on 2100 persons , the yellow line is based on 3100 persons which is trained now.
Figure0:

Figure1:(finetune 920k , from 1565k to 1610k steps, based on 2100 persons)

Figure2:(finetune 45k from 1565k to 1610k steps, based on 3100 persons)

I also what to know how mang steps is OK , in general. Because, I only know to train the synthesizer model and vocoder mode oneby one to judge the effect. But it will cost very long time. How about my EER or Loss ? Look forward your reply!
If your speakers are cleanly separated in the space (like they are in the pictures), you should be good to go! I'd be interested to compare with the same plots but before any training step was made, to see how the model does on Chinese data.
Hey guys, does anyone have pretrained models for Chinese. I need it for my collage project .
Will it work on Recoded Phone Calls ? If worked I can provide million of hours recordings in Bangali Language.
An interesting feat would be to be able to train it to, for instance, go through youtube playlists with hundreds of videos in a specified language, could grab the audio stream using something like the youtube-dl project to a temp folder, use it for training and repeat with each video, will try to see if that is possible, amazing work!
Can I continue training in Chinese corpus using the pre-training model you provided? @CorentinJ
For the encoder yes, for the synthesizer I wouldn't recommend it. For the vocoder, probably.
Got it. Thanks a lot~
得到它了。非常感谢〜
Because of my aphasia
I'm interested in this cloned voice.
I've had this thing for a day, but it's too hard for me.
May I ask for your help?
The tone of Baidu translation hopes not to be misunderstood.
Got it. Thanks a lot~
Because of my aphasia
I'm interested in this cloned voice.
I've had this thing for a day, but it's too hard for me.
May I ask for your help?
The tone of Baidu translation hopes not to be misunderstood.
I read the pre-processing alignment of other languages you talked about before.。。。I want to train this synthesizer Chinese model, I saw that it needs to be aligned and arranged in the format of the LibriSpeech folder. That's too much trouble. Can you tell me how to skip synthesizer_preprocess_audio.py, directly perform my synthesizer_preprocess_embeds.py operation on my .txt and .wav files, and then train?Thanks Very much.
You'll need a good dataset (at least ~300 hours, high quality and transcripts) in the language of your choice, do you have that?
So these 2 - language and voice - are different and I do not need only from one person ~>300h to synthezise the voice, correct?
Steps would be:
- Train a certain language with (>300h audio + transcripts)
- Create the voice with it
What GPU(s) are you guys using?
@UESTCgan have you tried to train the tacotron model using the embedding created by the encoder model? Is the result good? I trained the encoder part using Magic data(Chinese, 1017 speakers, 57w utterances, 755 hours), the loss like yours as showed in the picture before. Then I tried to train the tacotron model, using the same Magic data, cause I don't have 300+ hours TTS dataset, but the result is really bad.
Can't you just use youtube?
I would be very interested for a french version; is there any dataset including french that is compatible with RTVC?
6408
@boltomli Take a look at this dataset (1505 hours, 6408 speakers, recorded on smartphones):
https://www.datatang.com/webfront/opensource.html
Samples.zip
Not sure if the quality is good enough for encoder training.
404
The same as:
(http://www.openslr.org/resources/62/aidatatang_200zh.tgz)
??
6408
@boltomli Take a look at this dataset (1505 hours, 6408 speakers, recorded on smartphones):
https://www.datatang.com/webfront/opensource.html
Samples.zip
Not sure if the quality is good enough for encoder training.
maybe you can try other free chinese datasets: AISHELL-1 178h http://www.openslr.org/33/ ST-CMDS 500h http://www.openslr.org/38/ MAGICDATA Mandarin Chinese Read Speech Corpus 755h http://www.openslr.org/68/ | | george_cql | | george_cql@163.com | 签名由网易邮箱大师定制 On 11/21/2019 14:44,Lu Zhihenotifications@github.com wrote: 6408 @boltomli Take a look at this dataset (1505 hours, 6408 speakers, recorded on smartphones): https://www.datatang.com/webfront/opensource.html Samples.zip Not sure if the quality is good enough for encoder training. 404 The same as: ?? — You are receiving this because you commented. Reply to this email directly, view it on GitHub, or unsubscribe.
Thx, I will try.
Anyone have implemented a chinese demo ?
Maybe this repo can help ?
https://github.com/JasonWei512/Tacotron-2-Chinese
@CorentinJ @yaguangtang @ tail95 @zbloss @ HumanG33k我正在根据3100人的中文数据对编码器模型进行微调。我想知道如何判断微调是否还可以。在图0中,蓝线基于2100人,黄线基于3100人,现在已对其进行培训。
图0:
图1 :(微调920k,从1565k到1610k步,基于2100人)
图2 :(从3565人开始,以1565k到1610k的步幅微调45k)
总的来说,我也知道如何进行步进操作。因为,我只知道一个接一个地训练合成器模型和声码器模式来判断效果。但这将花费很长时间。我的EER或损失如何?期待您的回复!
Hey brother, how do you get the time of the word in the audio?
Can you give me a contact?
Hello,
I don't understand,. how I training the model?
What I need to the program speak my voice or famous People?
My language is Portuguese
Thx
Currently this project lives on my C:
I enjoy metaphors like that.
I'm interested on spanish training
How do I start?
Could Mozilla's Common Voice be used for this? https://voice.mozilla.org
@boltomli Take a look at this dataset (1505 hours, 6408 speakers, recorded on smartphones):
https://www.datatang.com/webfront/opensource.html
Samples.zip
Not sure if the quality is good enough for encoder training.
你好,您给的链接好像失效了
Cantonese training anyone?
Does someone have it in Portuguese Brazil??
Does someone have it in Portuguese Brazil??
I need too
I fork this repo and add encoder preprocess scripts for Chinese datasets (aishell1,magicdata,aidatatang,thchs30,mozilla,primewords,stcmds) total 3865 speakers and release pretrained encoder model with Chinese datasets
https://github.com/iwater/Real-Time-Voice-Cloning-Chinese
@iwater what datasets are those? Also are there any cantonese datasets?
all Mandarin datasets from openslr.org, except https://voice.mozilla.org/zh-CN/datasets @DonaldTsang
@iwater 我想请教一下,您只提供了一个模型文件,其它的模型文件在中文下都通用么
@zhilangtaosha 其他的模型文件需要依次训练,我之前训练了400人的3个模型,最新的其他模型正在依次训练中,训练好,我会继续放上去
The other model files need to be trained in sequence, I trained 3 models of 400 people earlier, the latest others are being trained in sequence, trained well, I'll keep putting them up
@iwater thank you very much
I upload the latest pretained model on steps 183W



@iwater Is it possible to upload a Tacotron model on your GitHub ,thanks
@zhilangtaosha that need more time, @CorentinJ pretrained that use 1 week with 4 GPUs, I only have one
@iwater Look forward to your work can be completed as soon as possible
我弄了一个中文版本的Synthesizer,对中文支持良好,提供Demo模型,可以参考一下。
https://github.com/KuangDD/zhrtvc
另外,
语音预处理可用:aukit
https://github.com/KuangDD/aukit
中文的音素方案可用:phkit
https://github.com/KuangDD/phkit
可用这两个工具处理模型外的事情,zhrtvc用aukit和phkit分别承担audio和text模块的工作。
Can't you generate datasets with TTS?
@Kreijstal that defeats the purpose, TTS already as a model built in, RTVC is for making the model.
@KuangDD Would you please upload the pretrained models for zhrtvc to another location? I would like to try it out but I am unable to download them from your Baidu links. It would be much appreciated if you can take the time to do this!
If anyone else has the zhrtvc pretrained models and can share them with me, that would work too.
@blue-fish
I made an upload to google drive from @KuangDD 's baidu links download.
Zhrtvc Sample data:
https://drive.google.com/file/d/1qjaS8TbRhUSToW1uSFgZfdqsFb0MYyz4/view?usp=sharing
Zhrtvc Sample models:
https://drive.google.com/file/d/1QU7LhehlMzFE8f-B6y9E7Hw8bd_AOl5H/view?usp=sharing
Thank you for sharing the zhrtvc pretrained models @windht ! It will not be as obvious in the future, so for anyone else who wants to try, the models work flawlessly with this commit: https://github.com/KuangDD/zhrtvc/tree/932d6e334c54513b949fea2923e577daf292b44e
What I like about zhrtvc:
- Display alignments for synthesized spectrograms
- Option to preprocess wavs for making the speaker embedding.
- Auto-save generated wavs (though I prefer our solution in #402)
Melgan is integrated but it doesn't work well with the default synthesizer model, so I ended up using Griffin-Lim most of the time for testing. WaveRNN quality is not that good either so it might be an issue on my end.
I'm trying to come up with ideas for this repo to support other languages without having to edit files.
I will be trying to do the same with spanish. Wish me luck. Any suggestions about compute power?
Couldn't we train other languages like german from the data of audiobooks?
@CorentinJ @yaguangtang @tail95 @zbloss @HumanG33k I am finetuning the encoder model by Chhinese data of 3100 persons. I want to know how to judge whether the train of finetune is OK. In Figure0, The blue line is based on 2100 persons , the yellow line is based on 3100 persons which is trained now.
Figure0:
Figure1:(finetune 920k , from 1565k to 1610k steps, based on 2100 persons)
Figure2:(finetune 45k from 1565k to 1610k steps, based on 3100 persons)
I also what to know how mang steps is OK , in general. Because, I only know to train the synthesizer model and vocoder mode oneby one to judge the effect. But it will cost very long time. How about my EER or Loss ? Look forward your reply!
@UESTCgan Hello, I would like to ask you if you do finetuning with Chinese dataset on the encoder trained with English dataset Librispeec? In addition, what Chinese datasets are you using?
I am trying to train encoder, synthesizer and vocoder in Arabic can i train synthesizer with single dataset not multi ?
@mennatallah644 It is possible to train a single-speaker model with this repository. You should only need to train a synthesizer. The existing encoder and vocoder should work.
Can someone please advise me (step by step) how to start synthesizer training? And what should be the structure of the csv file? I trained Tacotron2 here (https://github.com/NVIDIA/tacotron2) - is it possible to use such a pre-trained checkpoint.pt?
@Ctibor67 Step-by-step instructions: https://github.com/CorentinJ/Real-Time-Voice-Cloning/wiki/Training
Practice on LibriSpeech and then adapt the code to your dataset. No guide available but I provide some hints in #431 (comment)
Your checkpoint.pt from NVIDIA/tacotron2 is not compatible with this repo's tacotron, which uses tensorflow.
I will be trying to do the same with spanish. Wish me luck. Any suggestions about compute power?
Did you have any luck?
@CorentinJ @yaguangtang @tail95 @zbloss @HumanG33k I am finetuning the encoder model by Chhinese data of 3100 persons. I want to know how to judge whether the train of finetune is OK. In Figure0, The blue line is based on 2100 persons , the yellow line is based on 3100 persons which is trained now.
Figure0:
Figure1:(finetune 920k , from 1565k to 1610k steps, based on 2100 persons)
Figure2:(finetune 45k from 1565k to 1610k steps, based on 3100 persons)
I also what to know how mang steps is OK , in general. Because, I only know to train the synthesizer model and vocoder mode oneby one to judge the effect. But it will cost very long time. How about my EER or Loss ? Look forward your reply!
@UESTCgan Hi, I would like to ask you if you do finetuning with Chinese dataset on the encoder trained with English dataset Librispeec? In addition, what Chinese datasets are you using?And how about your final eer value with your training?
I will start fine tuning the encoder in Arabic Language, what should i do after gathering data ( the data i have is in the form of wav files ) how can i make it in the shape so that i can preprocess it with the script here and what changes should i make in the pre processing script?
I will be trying to do the same with spanish. Wish me luck. Any suggestions about compute power?
como te fue?
I will be trying to do the same with spanish. Wish me luck. Any suggestions about compute power?
como te fue?
Si hay equipo y alguien toma el liderazgo, yo me sumo para el esfuerzo en español.
Hi guys, does anybody has pretrained german or Brazilian Portuguese?
@floripaoliver Pretrained german: #571 (comment) . You will need an older version of the repo that uses the tensorflow synthesizer. Download commit 5425557. Tensorflow 1.x is rather difficult to install and we do not support it anymore as it is obsolete.
Thanks @blue-fish , I check it out on another system to not mess up my current installation which works like a charm. Did here ever anybody popup with Brazilian Portuguese or Australian English? Sorry for all the questions, I am pretty new to this but plan to get deeper into the subject and try to add here some useful content later on.
Any progress on Spanish dataset training?
Algún avance en la formación del conjunto de datos español?
Hey guys, is there anyone who used this for German male voices?
I will be trying to do the same with spanish. Wish me luck. Any suggestions about compute power?
did you get around to train the model. I found these datasets in spanish (and many other languages) https://commonvoice.mozilla.org/es/datasets
Any progress on Spanish dataset training?
Algún avance en la formación del conjunto de datos español?
Same here! let me know if any news or any help for Spanish
Any progress on Spanish dataset training?
Algún avance en la formación del conjunto de datos español?Same here! let me know if any news or any help for Spanish
Hey, I ended up using tacotron2 implementation by NVIDIA. If you train it in spanish, it speaks spanish; so I guess it will
work just as good in any language https://github.com/NVIDIA/tacotron2
Hello,
I tried to train the model for the italian languages but I still have some issues.
The steps I followed are:
- Preprocessing of the dataset http://www.openslr.org/94/
- Training of the synthetizer
- Using the synthetizer to generate the input data for the vocoder
- Train of the vocoder
After a long training (especially for the vocoder) the output generated by means of the toolbox is really poor (it can't "speak" italian).
Did I do something wrong or I missed some steps?
Thank you in advance
@andreafiandro Check the attention graphs from your synthesizer model training. You should get diagonal lines that look like this if attention has been learned. (This is required for inference to work) https://github.com/Rayhane-mamah/Tacotron-2/wiki/Spectrogram-Feature-prediction-network#tacotron-2-attention
If it does not look like that, you'll need additional training for the synthesizer, check the preprocessing for problems, and/or clean your dataset.
Hello,
I tried to train the model for the italian languages but I still have some issues.
The steps I followed are:
- Preprocessing of the dataset http://www.openslr.org/94/
- Training of the synthetizer
- Using the synthetizer to generate the input data for the vocoder
- Train of the vocoder
After a long training (especially for the vocoder) the output generated by means of the toolbox is really poor (it can't "speak" italian).
Did I do something wrong or I missed some steps?
Thank you in advance
@andreafiandro please, can you share your file trained for italian language? (pretrained.pt of synthetizer)
@andreafiandro Check the attention graphs from your synthesizer model training. You should get diagonal lines that look like this if attention has been learned. (This is required for inference to work) https://github.com/Rayhane-mamah/Tacotron-2/wiki/Spectrogram-Feature-prediction-network#tacotron-2-attention
If it does not look like that, you'll need additional training for the synthesizer, check the preprocessing for problems, and/or clean your dataset.
Thank you, I have something really different from expected diagonal line:

Probably I made some mistake in the data preprocessing or the dataset is too poor. I will try again, checking the results using the plots.
Do I need to edit some configuration file in order to the list of character of my language or I can follow the same training step described here?
@VitoCostanzo I can share the file if you want but it isn't working for the moment
Do I need to edit some configuration file in order to the list of character of my language or I can follow the same training step described here?
@andreafiandro - "Considerations - languages other than English" in #431 (comment)
Hello i am trying to train the system in spanish
The first thing i need is train the encoder ,what i need to change in the code or what are the step by step for make the training someone can help me ?
how to train for turkish ?
Thank you for sharing the zhrtvc pretrained models @windht ! It will not be as obvious in the future, so for anyone else who wants to try, the models work flawlessly with this commit: https://github.com/KuangDD/zhrtvc/tree/932d6e334c54513b949fea2923e577daf292b44e
What I like about zhrtvc:
- Display alignments for synthesized spectrograms
- Option to preprocess wavs for making the speaker embedding.
- Auto-save generated wavs (though I prefer our solution in Export and replay generated wav #402)
Melgan is integrated but it doesn't work well with the default synthesizer model, so I ended up using Griffin-Lim most of the time for testing. WaveRNN quality is not that good either so it might be an issue on my end.
I'm trying to come up with ideas for this repo to support other languages without having to edit files.
All links to KuangDD's projects now are no longer accessible. I'm currently working on latest fork of this repo to support mandarin and if anyone want to use as reference, please be free to folk and train: https://github.com/babysor/Realtime-Voice-Clone-Chinese
The original issue has been edited to provide visibility of community-developed voice cloning models in other languages. I'll also use it to keep track of requests.
From here:
A particularity of the SV2TTS framework is that all models can be trained
separately and on distinct datasets. For the encoder, one seeks to have a model
that is robust to noise and able to capture the many characteristics of the human
voice. Therefore, a large corpus of many different speakers would be preferable to
train the encoder, without any strong requirement on the noise level of the audios.
Additionally, the encoder is trained with the GE2E loss which requires no labels other
than the speaker identity. (...) For the datasets of the synthesizer and the vocoder,
transcripts are required and the quality of the generated audio can only be as good
as that of the data. Higher quality and annotated datasets are thus required, which
often means they are smaller in size.You'll need two datasets:
The first one should be a large dataset of untranscribed audio that can be noisy. Think thousands of speakers and thousands of hours. You can get away with a smaller one if you finetune the pretrained speaker encoder. Put maybe
1e-5as learning rate. I'd recommend 500 speakers at the very least for finetuning. A good source for datasets of other languages is M-AILABS.The second one needs audio transcripts and high quality audio. Here, finetuning won't be as effective as for the encoder, but you can get away with less data (300-500 hours). You will likely not have the alignments for that dataset, so you'll have to adapt the preprocessing procedure of the synthesizer to not split audio on silences. See the code and you'll understand what I mean.
Don't start training the encoder if you don't have a dataset for the synthesizer/vocoder, you won't be able to do anything then.
this can be done with some audiobooks?
when will french be done?
I've made a custom fork https://github.com/neonsecret/Real-Time-Voice-Cloning-Multilang
It now supports training a bilingual en+ru model, and it's easy to add new languages based on my fork
@CorentinJ I am planning to use your pre-trained modules to generate English audio but in my case I want my source audio to be Spanish so I should only worry about training the encoder right? And If I wanted to add emotions to the generated voice does the vocoder supports this?