注意:该项目已经不再维护,其重构版本 crane4j 已经发布正式版本。新版本更好,更快,更强大!欢迎围观:

基于 SpringBoot 的注解式字典项、关联表与枚举值处理框架。

简介
在我们日常开发中,常常会遇到一些烦人的数据关联和转换问题,比如典型的:
- 对象属性中存有字典 id,需要获取对应字典值并填充到对象中;
- 对象属性中存有外键,需要关联查询对应的数据库表实体,并获取其中的指定属性填充到对象中;
- 对象属性中存有枚举,需要将枚举中的指定属性填充到对象中;
实际场景中这种联查的需求远远不止这些,这些相关代码有时并不方便提取,因此我们不得不重复的写一些的样板代码去完成这些关联数据的查询填充,或字段转换的操作。crane 便是为了解决这种烦恼而生。它允许根据配置,从各种数据源中将数据在处理后自动“转移”到指定对象的自定字段中。
crane 本身不产生数据,它只会像吊车一样“搬运”各种数据,这也正是其名字的由来。
特性
- 多样的数据源支持。支持从枚举,普通键值对缓存,类中的指定方法中获取数据源,或通过简单的自定义扩展兼容更多类型的数据源;
- 更强大的字段映射。默认可选 JDK 原生反射或更快的字节码调用,提供不同类型字段之间映射自动转换以及各种集合元素间的字段映射。此外,还支持处理 JsonNode;
- 丰富的扩展功能。提供了类似 spring 的各类 XXXTemplate 的操作模板,基于切面对方法返回值自动填充,SpEL 表达式数据预处理,分组填充,预置字段映射模板,多线程填充等更多扩展功能。
- 支持多种配置方式。提供手动构建与类及属性注解两种配置方式,其中注解还支持用户基于 spring 的元注解机制自由扩展;
- 高度的可扩展性。所有主要组件都基于接口实现,并由 spring 提供了自动装配与依赖管理,用户可以便利的扩展或替换原有组件。
更多功能、配置与使用说明,请见仓库的 Wiki。
功能的基本使用,可运行的实例,请参考项目的 测试用例。
一些新的点子、意见、建议或者吐槽可以反馈在 这里。
crane 的核心功能就是字段填充。而当我们说“字段填充”,实际上指的就是根据待处理对象中的一个 key 值,获取一个对应的——可能是来自于数据源对象、集合或者其中的一个字段——数据源,然后塞到目标对象的指定字段中。
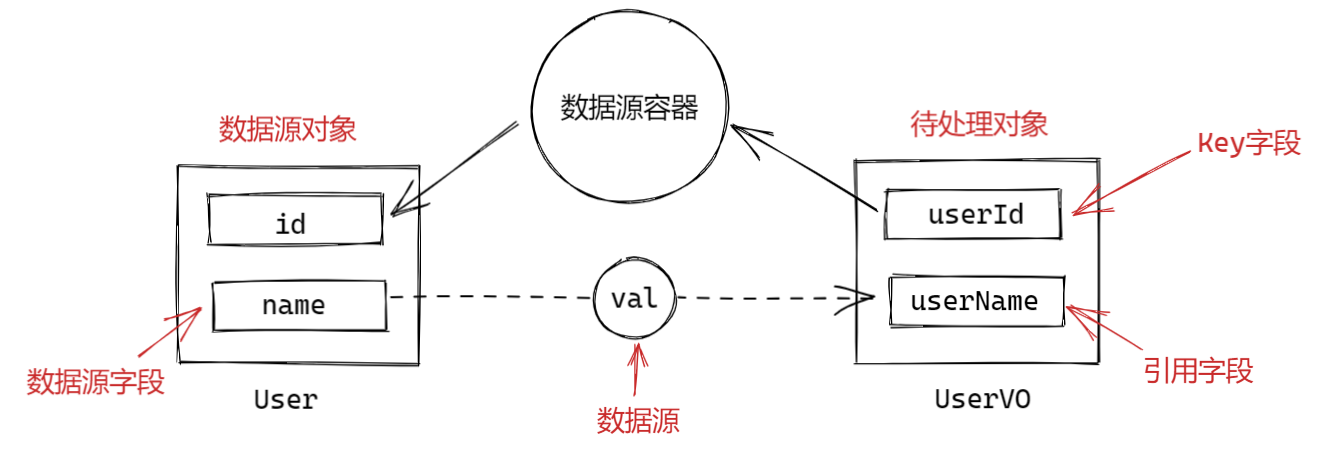
比如上图,就描述了一个根据 userId 从数据容器(这里可以简单理解为一个getById的方法)中获取到其对应的 User 对象,然后将 User.name 字段值填充到 UserVO.userName上的填充过程。
在 crane 中,完成上述操作对应如下配置:
public class UserVO {
@Assemble( // 声明一次操作
container = UserContainer.class, // 根据userId在该容器获得对应的数据源对象User
props = { @Prop(src = "name", ref = "userName") } // 将user的name映射为UserVO的userName
)
private Integer userId; // 外键是userId
private String userName;
}实际业务场景中,数据源可能是各式缓存或者数据库,甚至可能是配置文件,而需要处理的对象有不同的数据结构,要求填充的方式或字段也可能五花八门,而 crane 的核心功能就是对该流程的模拟和增强。
crane 提供了非常丰富的功能,这里挑出几个核心功能做出简单示例。
crane 支持基于注解在实体类上简单的完成一些功能的配置:
// 1.将数据源对象中的name映射到当前对象的userName字段,此处填充支持一定程度的类型自动转换
@Assemble(props = { @Prop(src = "name", ref = "userName") })
private Integer userId;
private String userName;
// 2.将数据源对象直接映射到当前对象的user字段
@Assemble(props = { @Prop(ref = "user") })
private Integer userId;
private User user;
// 3.将数据源对象的actualId字段映射到当前对象的userId字段
@Assemble(props = { @Prop(src = "actualId") })
private Integer userId;
// 4.若数据源对象是User集合,则依次将数据源对象中的name字段取出,并装到当前对象的userNames字段
@Assemble(props = { @Prop(src = "name", ref = "userNames") })
private Integer userId;
private List<String> userNames;
// 5.分组填充,userRole只有指定操作组为InnerGroup时才会被填充
@Assemble(props = { @Prop(src = "name", ref = "userName") }, groups = DefaultGroup.class)
@Assemble(props = { @Prop(src = "role", ref = "userRole") }, groups = InnerGroup.class)
private Integer userId;
private String userRole;
private String userName;
// 6.表达式预处理,获取数据源对象的name后,在前面拼接“亲爱的用户”,然后再填到当前对象的userName字段上
@Assemble(props = { @Prop(src = "name", ref = "userName", exp = "'亲爱的用户' + #source") })
private Integer userId;
private String userName;
// 6.嵌套填充,若Person也配置了字段映射,则将会把persons中的对象取出并进行处理
@Disassemble(Person.class)
private List<Person> persons;crane 支持通过各种容器兼容填充时所使用的各种各样的数据源,在容器注册到 spring 中后,可以通过 @Assemble#container 来引用它,容器将根据配置上的 namespace 和 key 值获取对应的数据源:
// 使用KeyValueContainer容器,根据键值对缓存中namespace的命名空间里,根据sex获得对应的值,然后填到当前对象的sexName字段
@Assemble(
namespace = "sex",
container = KeyValueContainer.class,
props = { @Prop(ref = "sexName") }
)
private Integer sex;
private String sexName;下述是 crane 默认支持的数据源:
- 键值对缓存:对应容器
KeyValueContainer,允许根据 namesapce 和 key 注册和获取任何数据; - 枚举:对应容器
EnumDictContainer,允许向容器中注册枚举类,然后通过指定的 namesapce 和 key 获得对应的枚举实例; - 实例方法:对应容器
MethodContainer,允许通过注解简单配置,将任意对象实例的方法作为数据源,通过 namespace 和 key 直接调用方法获取填充数据。适用于任何基于接口或本地方法的返回值进行填充的场景; - 内省容器:对应容器
BeanIntrospectContainer和KeyIntrospectContainer,允许直接将当前填充的对象作为数据源。适用于一些字段同步的场景;
此外,也提供了 BaseKeyContainer 和 BaseNamingContainer 抽象类,用户可以基于此快速定制数据源容器,然后注册到 spring 中即可使用。
crane 允许自由的在任何地方去触发填充行为的执行。
当方法返回值时调用
该功能基于 springAOP 实现。在方法上添加 @ProcessResult 注解,即可在调用方法时自动对返回值进行处理。
该功能支持处理单个对象、对象的数组或 Collection 集合,并且支持根据 SpEL 表达式动态确定是否对结果进行填充。
@ProcessResult(targetClass= Classroom.class, condition = "!#result.isEmpty && !#isHandle")
public List<Classroom> getClassroom(Boolean isHandler) {
// return something.......
}在代码中调用
crane 也支持通过 OperateTemplate 直接在代码中触发操作:
List<Foo> foos = Arrays.asList(new Foo(), new Foo(), new Foo(), new Foo());
operateTemplate.process(foos); // 通过spring容器获取在JSON序列化时调用
crane 提供了 DynamicJsonNodeModule 模块,将其注册到 ObjectMapper 实例中后,crane 将在 ObjectMapper 序列化时根据配置动态填充 JsonNode,并且能够一定程度上的新增或者替换原有字段:
List<Foo> foos = Arrays.asList(new Foo(), new Foo(), new Foo(), new Foo());
JsonNode foosJsonNode = objectMapper.valueToTree(foos);当该实例被用于在 @RestController 注解的 Controller 中使用时,则会自动对 Controller 的返回的 Json 数据进行处理。
下面将演示如何最快的搭建并启用一个 crane 项目。
下面将演示如何最简单的启动一个示例项目。
引入依赖
引入 SpringBoot 父工程:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>${version}</scope>
<relativePath/>
</parent>引入crane-spring-boot-starter、spring-boot-starter、spring-boot-starter-web、spring-boot-starter-test,lombok依赖:
<dependency>
<groupId>io.github.createsequence</groupId>
<artifactId>crane-spring-boot-starter</artifactId>
<version>${last-version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
- 若无法从 maven 仓库引入 crane 依赖,则可以把代码拉到本地,然后执行
mvn clean install命令安装到本地后即可引用;- 由于 Crane 尚未有正式的发行版,因此最好每次引入的依赖都为最新的;
引入配置
在启动类添加 @EnableScane 注解引入默认配置:
@EnableCrane
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}编码
编写实体类Person,并在sex字段上添加注解,根据字典项获取字典值,并替换字段值:
@Data // 使用Lombok简化getter和setter方法
@Accessors(chain = true)
public class Person {
@Assemble(namespace = "sex", props = @Prop(ref = "sexName"))
Integer sex;
String sexName;
}创建测试类,并在启动测试用例前向KeyValueContainer实例配置字典项sex:
@SpringBootTest
class CraneApplicationTests {
@Autowired
KeyValueContainer keyValueContainer;
@Autowired
OperateTemplate operateTemplate;
@BeforeEach
void initDate() {
// 配置字典项sex
Map<String, Object> gender = new HashMap<>();
gender.put("0", "女");
gender.put("1", "男");
keyValueContainer.register("sex", gender);
}
@Test
void testProcess() {
Person person = new Person().setSex(0);
System.out.println("after: " + person); // 处理前
operateTemplate.process(person);
System.out.println("before: " + person); // 处理后
}
}启动测用例,控制台输出:
after: Person(sex=0, sexName=null) // 处理前
before: Person(sex=0, sexName=女) // 处理后至此,即完成了 crane 的最基本功能的使用。
如果在使用中遇到了问题、发现了 bug ,又或者是有什么好点子,欢迎在 issues 或者加入 QQ 群:540919540 反馈!
-
更简洁与高效的执行器排序算法;
-
允许以类似 jackson 的方式对属性中的各个被注解方法的返回值进行拦截处理;
-
支持 Json 格式的入参填充,比如:
前端请求入参:
{"id": 12}后端接口得到参数:
{"id": 12, "name": "小明", "sex": 1} -
提供支持同时对装配与拆卸操作排序的执行器;
-
增加一些全局配置项,目前暂定以下几项:
- 如果已有字段非空,是否使用填充值覆盖已有字段值;
- 当某次填充发生异常时,是否终止本次填充操作;
- 是否需要输出填充过程中的一些日志;
- 预加载类操作配置到配置缓存;
- 枚举容器根据指定包路径批量扫描并注册枚举;
- 自定义使用反射还是字节码调用实现对象读写;
-
装卸配置允许处理动态类型的字段;
-
反射调用set方法时,若入参与参数类型不一致,尝试自动转换;
-
提供粒度更细的,更完善的测试用例;
-
提供支持缓存的类注解配置解析器;
-
提供支持多线程处理的执行器;
-
为容器提供一个带有基本方法的抽象类或工具类,简化自定义容器的实现,并且提供如缓存等相关功能扩展;
-
为实现模块提供更多扩展功能,如基于通用 mapper 或 rpc 接口的填充默认容器实现;
-
改造为多模块项目,分离注解模块、核心模块与 Json 和普通 JavaBean 等功能实现模块;
-
操作者中的具体字段处理支持自定义或者通过类似 MessageConverter 的责任链或策略机制进行集中配置;
-
字段配置支持 SpEL 表达式,比如:
@Assemble( container = DBContainer.class, props = @Prop(src = "sex", ref = "name", exp = "#source == '男' ? #target.name + '先生' : #target.name + '小姐'") ) private Integer userId;
并且基于此提供根据特殊条件判断是否执行本次操作等相关功能;
-
多重嵌套的集合类型字段支持,比如:
private List<List<Foo>> nestedProperty;
-
支持集合的元素的批量处理,比如:
{"userIds": [1, 2, 3]}变成:
{ "userIds": [ { "id": 1, "name": "小明" }, { "id": 2, "name": "小红" }, { "id": 3, "name": "小刚" } ] } -
使用字节码类库优化原生反射的性能;
-
引入类似 validation 的 group 的概念,用于将需要处理的字段分组,从而允许指定并仅使用特定分组的操作配置;
-
允许通过多个 key 字段获取数据源; -
允许通过专门的配置类或配置文件配置字段映射模板; -
允许通过专门的配置类或配置文件配置操作;