https://chinavis.org/2021/challenge.html
系统提供了对2013年到2018年空气污染数据的多种可视化方式,用户可从时间、空间、时空结合等角度对历史污染数据进行分析;同时对不同城市年污染物数据进行聚类降维,显示在地图上,可分析不同地区污染物变化模式,可对污染物的治理起到辅助分析作用;并利用模型对特定城市每小时的污染状况进行预测。

注:这里只提供了可视化界面的相关代码,为了方便下载data中数据的存放在网盘中,链接:https://pan.baidu.com/s/1GZCnlJN9_00HXdloY83Z1Q?pwd=v6ns 提取码:v6ns
data中的数据是基于ChinaVis2021数据可视化竞赛官方提供的小时数据集:http://naq.cicidata.top:10443/chinavis/opendata
经过分析处理后得到的便于可视化的json数据格式,数据处理与使用的算法模型简介如下:
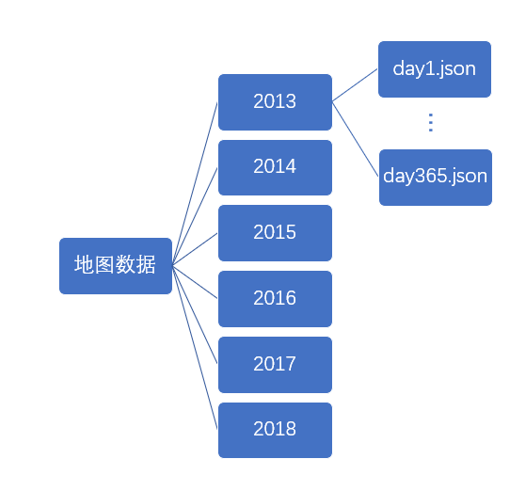
在将城市数据转换为python对象保存后,进一步将其转换为json数据便于后续可视化。以地图中显示每日各个城市污染物为例,需要根据选择日期读取对应天的污染物数据,数据格式如下图所示。
同时由于各种污染物单位不同,需要转换成AQI统一比较,转换规则如下图:

通过对每一年不同城市同种污染物数据进行降维与聚类,以便分析不同城市不同污染物之间的分布模式。通过t-SNE将数据降至二维,并且采用分层聚类算法对降 维结果进行聚类,得到不同的分布模式组合,并结合地理特征、产业特征对结果进行分析。
以单个城市单一污染物为例,对其进行预测。有研究表明,空气污染与一些气象因素,如风力、湿度有关,这些潜在的关系为预测提供了可能。以北京市PM2.5为例,构建预测模型。污染物的来源不仅有本地,还可能来自于周边的污染扩散,因此我们在输入数据中加入了周边城市的天气情况。预测算法采用LSTM(Long short-term memory), 是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。相比普通的RNN,LSTM能够在更长的序列中有更好的表现,其结构如下图所示。


在本地导入项目和data数据后
使用vscode open with live server
使用python在附录下搭建本地任意目录http.server服务器(默认8000端口)
python -m http.server