This is my Google Summer of Code 2018 Project with the Red Hen Lab.
The aim of this project is to develop a working Speech-to-Text module for the Red Hen Lab’s Chinese Pipeline, resulting in a working application. The initial goal is to establish a Tensorflow implementation for Chinese speech recognition based on Mozilla's DeepSpeech. During the GSoC coding period, we've found a better option for Chinese ASR: an open source program named DeepSpeech2 on PaddlePaddle based on DeepSpeech2 Paper, which better suit Chinese Pipeline rather than Mozilla’s DeepSpeech. Until the end of in GSoC, I have progressed to the point of being able to run DeepSpeech2 on PaddlePaddle inside Singularity on CWRU HPC and already had a perfect model developed by Baidu with its abundant Chinese materials. I also established an ASR system based on PaddlePaddle and Kaldi. Different from direct prediction of word distribution using deep learning end-to-end model in DeepSpeech, the example in this blog is closer to the traditional ASR process. I tried to use phoneme as the modeling unit, focusing on the training of the acoustic model in ASR,using Kaldi to extract the features of the audio data and the label alignment, and integrate the decoder of the Kaldi to complete the decoding.
- Getting Started
- Data-Preprocessing for Training
- Training
- Inference and Evaluation
- Running Code at CWRU HPC
- Some Training Results
- ASR system based on PaddlePaddle and Kaldi
- Acknowledgments
- Python 2.7 only supported
- Singularity
- Download Singularity Image
$ singularity pull shub://RedHenLab/singularity_containers:DeepSpeech2_shuwei
- Cloning the repository
$ git clone https://github.com/CynthiaSuwi/ASR-for-Chinese-Pipeline.git
- Download 70GB language model
$ cd models/lm
$ wget -O zhidao_giga.klm http://cloud.dlnel.org/filepub/?uuid=245d02bb-cd01-4ebe-b079-b97be864ec37
ASR for Chinese Pipeline on PaddlePaddle accepts a textual manifest file as its data set interface. A manifest file summarizes a set of speech data, with each line containing some meta data (e.g. filepath, transcription, duration) of one audio clip, in JSON format, such as:
{"audio_filepath": "/mnt/rds/redhen/gallina/Singularity/DeepSpeech2/DeepSpeech/.cache/paddle/dataset/speech/Aishell/data_aishell/wav/dev/S0724/BAC009S0724W0123.wav", "duration": 3.241, "text": "相比于其他一线城市"}
{"audio_filepath": "/mnt/rds/redhen/gallina/Singularity/DeepSpeech2/DeepSpeech/.cache/paddle/dataset/speech/Aishell/data_aishell/wav/dev/S0724/BAC009S0724W0466.wav", "duration": 4.910875, "text": "故宫博物院官网发布公告称"}
{"audio_filepath": "/mnt/rds/redhen/gallina/Singularity/DeepSpeech2/DeepSpeech/.cache/paddle/dataset/speech/Aishell/data_aishell/wav/dev/S0724/BAC009S0724W0310.wav", "duration": 10.9819375, "text": "还应该主动融入**制造二万一千零二十五规划中的新产业"}
{"audio_filepath": "/mnt/rds/redhen/gallina/Singularity/DeepSpeech2/DeepSpeech/.cache/paddle/dataset/speech/Aishell/data_aishell/wav/dev/S0724/BAC009S0724W0189.wav", "duration": 4.913, "text": "若公诉罪名利用未公开信息交易罪成立"}
{"audio_filepath": "/mnt/rds/redhen/gallina/Singularity/DeepSpeech2/DeepSpeech/.cache/paddle/dataset/speech/Aishell/data_aishell/wav/dev/S0724/BAC009S0724W0158.wav", "duration": 5.216, "text": "对单价三万元的二手房承接力不断反升"}
To use your custom data, you only need to generate such manifest files to summarize the dataset. Given such summarized manifests, training, inference and all other modules can be aware of where to access the audio files, as well as their meta data including the transcription labels.
For how to generate such manifest files, please refer to data/aishell/aishell.py, which will download data and generate manifest files for Aishell dataset.
To perform z-score normalization (zero-mean, unit stddev) upon audio features, we have to estimate in advance the mean and standard deviation of the features, with some training samples:
python tools/compute_mean_std.py \
--manifest_path='data/aishell/manifest.train' \
--num_samples=2000 \
--specgram_type='linear' \
--output_path='data/aishell/mean_std.npz'It will compute the mean and standard deviation of power spectrum feature with 2000 random sampled audio clips listed in data/aishell/manifest.train and save the results to data/aishell/mean_std.npz for further usage.
A vocabulary of possible characters is required to convert the transcription into a list of token indices for training, and in decoding, to convert from a list of indices back to text again. Such a character-based vocabulary can be built with tools/build_vocab.py.
python tools/build_vocab.py \
--count_threshold=0 \
--vocab_path='data/aishell/vocab.txt' \
--manifest_paths 'data/aishell/manifest.train' 'data/aishell/manifest.dev'It will write a vocabuary file data/aishell/vocab.txt with all transcription text in data/aishell/manifest.train, without vocabulary truncation (--count_threshold 0).
For more help on arguments:
python data/aishell/aishell.py --help
python tools/compute_mean_std.py --help
python tools/build_vocab.py --help| Language Model | Training Data | Token-based | Size | Descriptions |
|---|---|---|---|---|
| Mandarin LM Small | Baidu Internal Corpus | Char-based | 2.8 GB | Pruned with 0 1 2 4 4; About 0.13 billion n-grams; 'probing' binary with default settings |
| Mandarin LM Large | Baidu Internal Corpus | Char-based | 70.4 GB | No Pruning; About 3.7 billion n-grams; 'probing' binary with default settings |
In this project, we download the 70.4 GB model using:
wget -O zhidao_giga.klm http://cloud.dlnel.org/filepub/?uuid=245d02bb-cd01-4ebe-b079-b97be864ec37
Different from the English language model, Mandarin language model is character-based where each token is a Chinese character. We use internal corpus to train the released Mandarin language models. The corpus contain billions of tokens. Please notice that the released language models only contain Chinese simplified characters. After preprocessing done we can begin to train the language model. The key training arguments for small LM is '-o 5 --prune 0 1 2 4 4' and '-o 5' for large LM. Please refer above section for the meaning of each argument. We also convert the arpa file to binary file using default settings.
| Language | Model Name | Training Data | Hours of Speech |
|---|---|---|---|
| Mandarin | Aishell Model | Aishell Dataset | 151 h |
| Mandarin | BaiduCN1.2k Model | Baidu Internal Mandarin Dataset | 1204 h |
An inference module caller infer.py is provided to infer, decode and visualize speech-to-text results for several given audio clips. It might help to have an intuitive and qualitative evaluation of the ASR model's performance.
-
Inference with GPU:
CUDA_VISIBLE_DEVICES=0 python infer.py --trainer_count 1
-
Inference with CPUs:
python infer.py --use_gpu False --trainer_count 12
We provide two types of CTC decoders: CTC greedy decoder and CTC beam search decoder. The CTC greedy decoder is an implementation of the simple best-path decoding algorithm, selecting at each timestep the most likely token, thus being greedy and locally optimal. The CTC beam search decoder otherwise utilizes a heuristic breadth-first graph search for reaching a near global optimality; it also requires a pre-trained KenLM language model for better scoring and ranking. The decoder type can be set with argument --decoding_method.
For more help on arguments:
python infer.py --help
or refer to example/aishell/run_infer_golden.sh.
To evaluate a model's performance quantitatively, please run:
-
Evaluation with GPUs:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python test.py --trainer_count 8
-
Evaluation with CPUs:
python test.py --use_gpu False --trainer_count 12
The error rate (default: word error rate; can be set with --error_rate_type) will be printed.
For more help on arguments:
python test.py --helpor refer to example/aishell/run_test_golden.sh.
- Login and open screen
$ ssh sxx186@redhen1.case.edu
$ screen
$ ssh sxx186@rider.case.edu- Note: Screen establishes a terminal window on the server. So it doesn’t matter if your network connection is terrible or even drops.
- Require a computation node and load Singularity
$ ssh sxx186@rider.case.edu
$ srun -p gpu -C gpup100 --mem=180gb --gres=gpu:1 --pty bash
$ module load singularity/2.5.1- Note: Note: remember to require larger memory, otherwise it will occur the error “srun out of memory”.
- Get into the image
$ cd /mnt/rds/redhen/gallina/Singularity/DeepSpeech2/DeepSpeech/
$ singularity shell --nv -e -H `pwd` deepspeech2_suwi_singularity.simg- Note 1: remember to add “–nv”, otherwise it will show CUDA error.
- Note 2: there’s no need to UNSET HOME anymore, since I created a Singularity recipe to set environment.
- Run the code
$ cd examples/aishell/
$ sh run_data.sh
$ sh run_test_golden.sh
$ sh run_infer_golden.sh----------- Configuration Arguments -----------
alpha: 2.6
beam_size: 300
beta: 5.0
cutoff_prob: 0.99
cutoff_top_n: 40
decoding_method: ctc_beam_search
error_rate_type: cer
infer_manifest: data/aishell/manifest.test
lang_model_path: models/lm/zhidao_giga.klm
mean_std_path: models/aishell/mean_std.npz
model_path: models/aishell/params.tar.gz
num_conv_layers: 2
num_proc_bsearch: 2
num_rnn_layers: 3
num_samples: 10
rnn_layer_size: 1024
share_rnn_weights: 0
specgram_type: linear
trainer_count: 2
use_gpu: 1
use_gru: 1
vocab_path: models/aishell/vocab.txt
------------------------------------------------
I0713 04:53:39.325980 112135 Util.cpp:166] commandline: --use_gpu=1 --rnn_use_batch=True --trainer_count=2
[INFO 2018-07-13 04:53:41,068 layers.py:2606] output for __conv_0__: c = 32, h = 81, w = 54, size = 139968
[INFO 2018-07-13 04:53:41,069 layers.py:3133] output for __batch_norm_0__: c = 32, h = 81, w = 54, size = 139968
[INFO 2018-07-13 04:53:41,069 layers.py:7224] output for __scale_sub_region_0__: c = 32, h = 81, w = 54, size = 139968
[INFO 2018-07-13 04:53:41,070 layers.py:2606] output for __conv_1__: c = 32, h = 41, w = 54, size = 70848
[INFO 2018-07-13 04:53:41,070 layers.py:3133] output for __batch_norm_1__: c = 32, h = 41, w = 54, size = 70848
[INFO 2018-07-13 04:53:41,071 layers.py:7224] output for __scale_sub_region_1__: c = 32, h = 41, w = 54, size = 70848
[INFO 2018-07-13 04:53:45,501 model.py:243] begin to initialize the external scorer for decoding
[INFO 2018-07-13 04:53:49,109 model.py:253] language model: is_character_based = 1, max_order = 5, dict_size = 0
[INFO 2018-07-13 04:53:49,109 model.py:254] end initializing scorer
[INFO 2018-07-13 04:53:49,109 infer.py:104] start inference ...
I0713 04:53:49.117202 112135 MultiGradientMachine.cpp:99] numLogicalDevices=1 numThreads=2 numDevices=2
Target Transcription: 核武器并不能征服类似美国这样的国家
Output Transcription: 和武器并不能征服类似美国这样的国家
Current error rate [cer] = 0.058824
Target Transcription: 由于不可能从根本上改变供求关系
Output Transcription: 由于不可能从根本上改变供求关系
Current error rate [cer] = 0.000000
Target Transcription: 个人寄快递必须登记有效的身份证件
Output Transcription: 个人既快递必须登记有效的身份证件
Current error rate [cer] = 0.062500
Target Transcription: 在这场亚洲国家锁定胜局的申办博弈中
Output Transcription: 在这场亚洲国家所定胜局的申办博弈中
Current error rate [cer] = 0.058824
Target Transcription: 可以有效的抵消年龄所带来的速度劣势
Output Transcription: 可以有效地抵消年龄所带来的速度劣势
Current error rate [cer] = 0.058824
Target Transcription: 要加大保障性安居工程建设资计划落实力度
Output Transcription: 要加大保障性安居工程建设投资计划落实力度
Current error rate [cer] = 0.052632
Target Transcription: 财政能力和硬件设施的优势是我们最终取胜的关键原因
Output Transcription: 财政能力和硬件设施的优势是我们最终取胜的关键原因
Current error rate [cer] = 0.000000
Target Transcription: 因而痛斩情丝她除了拥有模特儿火辣身材
Output Transcription: 因而痛感清斯他除了拥有模特火辣身材
Current error rate [cer] = 0.277778
Target Transcription: 他们会拥有较快的速度
Output Transcription: 他们会拥有较快的速度
Current error rate [cer] = 0.000000
Target Transcription: 可以实现在敌国网络中的长期潜伏
Output Transcription: 可以实现在**网络中的长期潜伏
Current error rate [cer] = 0.066667
[INFO 2018-07-13 04:53:50,868 infer.py:125] finish inference
- Note 1: I modified the
run_infer_golden.shfile to change lm model as larger 70GB model. And skip the repeating download step to realize quicker execution. - Note 2: I modified the
infer.pyfile to make the target transcription support UTF-8 Chinese by adding .encode(utf-8). - Note 3: I modified the batch_size from 128 to 64 in
run_test_golden.shfile to meet the memory requirement of CWRU server.
- Kaldi
The decoder of the example depends on Kaldi, install it by flowing its intructions.Then set the environment variable
KALDI_ROOT:
$ export KALDI_ROOT=<Installation path of kaldi>- Decoder
$ git clone https://github.com/CynthiaSuwi/ASR-for-Chinese-Pipeline.git
$ cd kaldi/decoder
$ sh setup.shRefer to the data preparation process of Kaldi to complete the feature extraction and label alignment of audio data.
This section takes the Aishell dataset as an example to show how to complete data preprocessing and decoding output. To simplify the process, the preprocessed dataset has been provided for download:
$ cd kaldi/examples/aishell
$ sh prepare_data.shAfter the download is completed, the training process can be analyzed before starting training:
$ sh profile.shExecute the training:
$ sh train.shThe cost function and the trend of accuracy in the training process are shown below: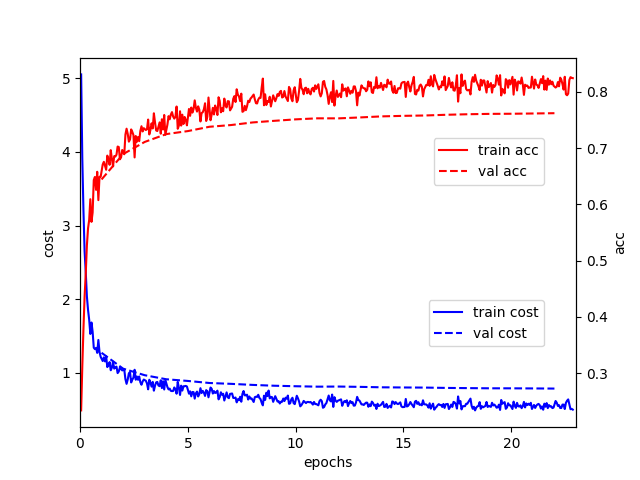
After completing the model training, the text in the prediction test set can be executed:
$ sh infer_by_ckpt.shIt includes two important processes: the prediction of acoustic model and the decoding output of the decoder. The following is a sample of the decoded output:
BAC009S0764W0239 十一 五 期间 我 国 累计 境外 投资 七千亿 美元
BAC009S0765W0140 在 了解 送 方 的 资产 情况 与 需求 之后
BAC009S0915W0291 这 对 苹果 来说 不 是 件 容易 的 事 儿
BAC009S0769W0159 今年 土地 收入 预计 近 四万亿 元
BAC009S0907W0451 由 浦东 商店 作为 掩护
BAC009S0768W0128 土地 交易 可能 随着 供应 淡季 的 到来 而 降温Each row corresponds to one output, beginning with the key word of the audio sample, followed by the decoding of the Chinese text separated by the word. Run script evaluation word error rate (CER) after decoding completion:
$ sh score_cer.shIts output is similar as below:
Error rate[cer] = 0.101971 (10683/104765),
total 7176 sentences in hyp, 0 not presented in ref.Using the acoustic model of 20 rounds of training, we can get about 10% CER for recognition results on the Aishell test set.