Salut tout le monde ! Je suis ravi de partager avec vous mon retour d'expérience en markdown après les six premiers mois de la formation SLAM portant sur les bases de données et les applications web ! (Vous y trouverez la base.)
Créateur du Projet : François Vivet | Projet : AFIL_2024_SIO1_GRP2
🔍 Explorez | 🧠 Apprenez | 🤝 Connectez-vous !
Projet : Centre de Formation Saint-Etienne (CFAI)
- Partie GIT : Cours
- Partie BDD : Cours
- Définitions
- Qu'est-ce qu'une Base de Donnée ?
- Qu'est-ce que Homebrew ?
- Que veut dire SGBDR ?
- Que veut dire Cloner son projet GIT ?
- Qu'est-ce qu'un commit ?
- Qu'est-ce qu'un push ?
- Qu'est-ce qu'un Schemas ?
- Qu'est-ce qu'une TABLE ?
- Qu'est-ce qu'un champ ?
- Qu'est-ce qu'une occurrence ?
- Qu'est-ce qu'une clé primaire ?
- Qu'est-ce qu'une clé étrangère ?
- A quoi sert le ALTER TABLE ?
- Installation de Homebrew
- Installation de PostgreSQL
- Gestion de base de données
- Définitions
-
Partie SQL avec DBeaver : TP1 (suite)
- Exercice 1 : Camions - NoImmatriculation
- Exercice 2 : Déchets - Libellé
- Exercice 3 : Types de déchets - Camion
- Exercice 4 : Liste des camions - Verre
- Exercice 5 : Liste des pesées - David
- Exercice 6 : Pesée - 2017
- Exercice 7 : Poids Max - 2017
- Exercice 8 : Camions < 19T
- Exercice 9 : Poids "Papiers-cartons" - SOLUTRI
- Exercice 10 : Syndicat - Verre (Ordre alphabétique)
- Exercice 11 : Poids déchets - syndicat/type de déchet
- Exercice 12 : Type déchets - Pas Pesée
Partie GIT : Cours
Git est un gestionnaire de source qui permet d'envoyer des fichiers de manière très rapidement en l'espace de quelques seconde sur un serveur (gain de temps). C'est tout bonnement du texte où l'on peut voir les modifications apportées.


Cliquez ici pour revenir au sommaire
-
Créez un référentiel (repository) Git : Si vous n'avez pas encore de référentiel Git pour votre projet, vous pouvez en créer un sur une plateforme comme GitHub, GitLab, HerokuGit, ou en local sur votre machine. Pour créer un référentiel localement, utilisez la commande
git initdans le répertoire de votre projet. -
Ajoutez et confirmez (commit) vos modifications : Avant de pousser quoi que ce soit, assurez-vous d'ajouter et de confirmer vos modifications dans le référentiel local. Utilisez les commandes suivantes pour cela :
git add . # Pour ajouter tous les fichiers modifiés git commit -m "Message de confirmation" # Pour confirmer les modifications git push # Envoyer votre projet (donc les edits) dans votre référentiel.
Exemple de référentiel :
Cliquez ici pour revenir au sommaire
Cliquez ici pour revenir au sommaire
Définition
New : // Permet d'instancier/charger un objetProcédure : Commencer à Coder en C#
Ex : Main(); → static + void + nom
Avant de commencer à coder en C#, vous devez disposer d'un environnement de développement intégré (IDE) pour faciliter le processus de développement. Visual Studio (Community Edition) est l'IDE le plus couramment utilisé pour la programmation C#. Vous pouvez le télécharger depuis le site Web de Microsoft.
Une fois que vous avez installé l'IDE, créez un nouveau projet. Choisissez le type de projet qui correspond à votre application, qu'il s'agisse d'une application de console, d'une application Windows Forms, d'une application Web, etc.
À l'intérieur de votre projet, vous pouvez commencer à écrire du code C#. Vous pouvez ajouter de nouvelles classes, des méthodes et des variables pour implémenter la logique de votre application.
using System; // pour inclure l'espace de noms System, qui contient des classes et des méthodes pour les entrées/sorties.
class Program // Il définit une classe appelée Program.
{
static void Main() // À l'intérieur de la classe Program, il définit une méthode statique appelée Main(). Cette méthode est le point d'entrée de l'application C#. C'est une branch.
{
Console.WriteLine("Hello, World!"); // À l'intérieur de la méthode Main(), il utilise Console.WriteLine pour afficher "Hello, World!" dans la console.
}
}Après avoir écrit du code, vous devez le compiler en cliquant sur le bouton de compilation de votre IDE (déboguer). Si aucune erreur de compilation n'est détectée, vous pouvez exécuter votre application pour voir comment elle fonctionne.
Les opérateurs en C#
Voici quelques-uns des opérateurs les plus couramment utilisés en C# :
- L'opérateur d'addition (
+) est utilisé pour ajouter deux valeurs. - L'opérateur d'assignation (
=) est utilisé pour affecter une valeur à une variable. - L'opérateur de comparaison supérieur ou égal (
>=) est utilisé pour comparer deux valeurs et renvoyer vrai si la première valeur est supérieure ou égale à la deuxième valeur. - L'opérateur de comparaison inférieur ou égal (
<=) est utilisé pour comparer deux valeurs et renvoyer vrai si la première valeur est inférieure ou égale à la deuxième valeur. - L'opérateur logique ET (
&&) est utilisé pour combiner deux expressions booléennes et renvoyer vrai si les deux expressions sont vraies. - L'opérateur logique OU (
||) est utilisé pour combiner deux expressions booléennes et renvoyer vrai si au moins une des expressions est vraie.
Instructions
"le temps que" (while)
L'instruction "le temps que" est une structure de contrôle qui permet d'exécuter un bloc de code tant qu'une condition spécifiée est vraie. Voici comment elle fonctionne :
while (condition)
{
// Code à exécuter tant que la condition est vraie
}L'instruction "pour" est une boucle de répétition qui permet d'exécuter un bloc de code un nombre spécifié de fois. Voici comment elle fonctionne :
for (initialisation; condition; itération)
{
// Code à exécuter à chaque itération
}- L'initialisation est utilisée pour définir une variable de contrôle et lui attribuer une valeur de départ.
- La condition spécifie quand la boucle doit continuer à s'exécuter.
- L'itération est utilisée pour modifier la variable de contrôle à chaque itération.
"répéter" (do-while)
L'instruction "répéter" est similaire à "le temps que", mais elle garantit qu'au moins une exécution du bloc de code aura lieu avant que la condition ne soit évaluée. Voici comment elle fonctionne :
do
{
// Code à exécuter au moins une fois
} while (condition);-
Le bloc de code est exécuté en premier, puis la condition est évaluée.
-
Si la condition est vraie, le bloc de code sera exécuté à nouveau, et cela se répétera tant que la condition reste vraie.
-
Ces trois types d'instructions répétitives sont essentiels pour créer des boucles et automatiser des tâches répétitives en programmation C#. Chacun d'eux a ses cas d'utilisation particuliers en fonction des besoins de votre programme.
Conditionnelles `if` avec `else`
Les instructions conditionnelles if avec else permettent de gérer deux cas distincts : l'un lorsque la condition est vraie (l'instruction if) et l'autre lorsque la condition est fausse (l'instruction else). Cette structure est couramment utilisée pour prendre des décisions binaires (0 et 1).
L'instruction if avec else a la structure suivante :
if (condition)
{
// Code à exécuter si la condition est vraie
}
else
{
// Code à exécuter si la condition est fausse
}Voici un exemple simple d'utilisation de l'instruction if avec else en C# :
int age = 15;
if (age >= 18)
{
Console.WriteLine("Vous êtes majeur.");
}
else
{
Console.WriteLine("Vous êtes mineur.");
}Explication : Dans cet exemple, si la variable age est supérieure ou égale à 18, le message "Vous êtes majeur." sera affiché. Sinon, si la condition est fausse, le message "Vous êtes mineur." sera affiché.
Les instructions if avec else sont utiles pour prendre des décisions simples en fonction de la valeur d'une condition. Cependant, elles peuvent également être combinées avec d'autres instructions else if pour gérer plusieurs conditions en cascade.
Un TimeStamp est un nombre de seconde ou de milliseconde écoulé depuis une date de référence.
Cliquez ici pour revenir au sommaire
Partie BDD : Cours
Cliquez ici pour revenir au sommaire
Définitions
-- Ajouter une colonne à une table
ALTER TABLE nom_table
ADD nom_colonne type_de_données;
-- Supprimer une colonne d'une table
ALTER TABLE nom_table
DROP COLUMN nom_colonne;
-- Modifier le type de données d'une colonne
ALTER TABLE nom_table
ALTER COLUMN nom_colonne nouveau_type_de_données;
-- Ajouter une contrainte de clé étrangère
ALTER TABLE table_1
ADD CONSTRAINT nom_contrainte
FOREIGN KEY (colonne_reference) REFERENCES table_2(colonne_reference);Installation de Homebrew
Si vous n'avez pas encore installé Homebrew, vous pouvez le faire en suivant ces étapes :
1 - Ouvrez Terminal :
- Lancez l'application Terminal depuis le dossier "Utilitaires" de votre dossier "Applications" ou recherchez-la avec Spotlight ( + Espace).
2 - Installation de Homebrew :
- Copiez-collez la commande suivante dans le Terminal et appuyez sur "Entrée" pour lancer l'installation de Homebrew :
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"3 - Faîtes cette commande pour être sur que HomeBrew est installé sur votre Mac :
brew doctorCliquez ici pour revenir au sommaire
Installation de PostgreSQL
Une fois Homebrew installé, suivez ces étapes pour installer PostgreSQL :
1 - Mise à jour de Homebrew :
- Avant d'installer PostgreSQL, assurez-vous que Homebrew est à jour en exécutant la commande suivante dans le Terminal :
brew update2 - Installation de PostgreSQL (v15):
- Exécutez la commande suivante pour installer PostgreSQL :
brew install postgresql@15
3 - Source de l'installation
Grâce à la commande, nous pouvons voir le répétoire du package Postgresql :
brew --prefix postgresqlCela nous affiche :
/usr/local/opt/postgresql@154 - Démarrage du service PostgreSQL :
- PostgreSQL démarrera automatiquement après l'installation. Pour démarrer le service, utilisez la commande suivante :
brew services start postgresql@155 - Vérification du services - started
sudo brew services listCliquez ici pour revenir au sommaire
Gestion de base de données
Installation PgAdmin
1 - Installation avec HomeBrew :

brew install --cask pgadmin42 - Démarrer PGAdmin : Une fois l'installation terminée, vous pouvez démarrer PGAdmin en utilisant le Launchpad ou en exécutant la commande suivante dans le terminal
2 - Source de l'installation
/usr/local/Caskroom/pgadmin4/open -a pgadmin4Cliquez ici pour revenir au sommaire
Installation de DBeaver
Après avoir installé PostgreSQL, vous pouvez installer DBeaver en utilisant la commande Homebrew :
1 - Installation de DBeaver :
- Exécutez la commande suivante pour installer DBeaver :
brew install --cask dbeaver-community2 - Source de l'installation
/usr/local/Caskroom/dbeaver-community
3 - Lancement de DBeaver :
- Vous pouvez lancer DBeaver à partir du Launchpad ou en exécutant dbeaver dans le Terminal.
Configuration PgAdmin
Pour configurer une connexion à une base de données PostgreSQL dans DBeaver sur macOS, suivez ces étapes :
-
Configuration initiale : Lorsque vous exécutez PGAdmin pour la première fois, il vous demandera de configurer un mot de passe principal. Suivez les étapes pour le configurer.
-
Ajouter un serveur PostgreSQL : Une fois que PGAdmin est configuré, vous pouvez ajouter un serveur PostgreSQL en cliquant sur l'icône "Add New Server" dans la barre d'outils de PGAdmin. Vous devrez spécifier les détails de connexion, tels que le nom d'hôte, le port, le nom d'utilisateur et le mot de passe.
-
Accéder à votre serveur PostgreSQL : Une fois que le serveur est ajouté, vous pouvez double-cliquer dessus pour accéder à votre base de données PostgreSQL et commencer à travailler avec vos bases de données et tables.
Configuration DBeaver
Pour configurer une connexion à une base de données PostgreSQL dans DBeaver sur macOS, suivez ces étapes :

-
Ouverture de l'onglet "Bases de données" :
- Dans la barre latérale de gauche, cliquez sur l'onglet "Bases de données" pour accéder à la vue des bases de données.
-
Ajout d'une nouvelle connexion :
- Dans la vue "Bases de données", faites un clic droit (ou Ctrl + clic) sur "Nouvelle connexion" et sélectionnez "Nouvelle connexion" dans le menu contextuel.
-
Choix du type de base de données :
- Dans la fenêtre de configuration de la connexion, sélectionnez "PostgreSQL" dans la liste des types de bases de données disponibles.
-
Configuration de la connexion :
- Remplissez les informations de connexion à votre base de données PostgreSQL :
- Nom de la connexion : Donnez un nom à votre connexion (par exemple, "Ma Base de Données PostgreSQL").
- Hôte : L'adresse IP ou le nom de domaine de votre serveur PostgreSQL (généralement "localhost" soit 127.0.0.1, si la base de données est sur votre Mac).
- Port : Le numéro de port de votre base de données PostgreSQL (généralement 5432).
- Nom de la base de données : Le nom de la base de données à laquelle vous souhaitez vous connecter.
- Nom d'utilisateur : Le nom d'utilisateur PostgreSQL.
- Mot de passe : Le mot de passe de l'utilisateur PostgreSQL.
- Remplissez les informations de connexion à votre base de données PostgreSQL :
-
Test de la connexion :
- Cliquez sur le bouton "Tester la connexion" pour vérifier que la configuration est correcte et que DBeaver peut se connecter à votre base de données.
-
Enregistrement de la connexion :
- Si le test de connexion réussit, cliquez sur "Terminer" pour enregistrer la configuration de la connexion.
-
Accès à la base de données :
- Vous pouvez maintenant accéder à votre base de données PostgreSQL en double-cliquant sur la connexion que vous avez créée. DBeaver affichera la structure de votre base de données et vous permettra d'exécuter des requêtes SQL, de gérer des tables, d'importer/exporter des données, etc.
C'est tout ! Vous avez configuré avec succès une connexion à une base de données PostgreSQL dans DBeaver sur votre Mac. Vous pouvez maintenant commencer à travailler avec votre base de données via DBeaver.
Cliquez ici pour revenir au sommaire
Partie Web : Cours

Cliquez ici pour revenir au sommaire
Définitions
Quel est la différente entre le front-end et le back-end ?
Front-end (côté client) :
-
Qu'est-ce que c'est ?
Le front-end est la partie visible d'une application web avec laquelle l'utilisateur interagit directement. Cela englobe l'interface utilisateur, la conception graphique, les animations et tout ce que l'utilisateur voit et avec quoi il interagit dans le navigateur.
-
Technologies impliquées :
HTML (structure de la page), CSS (styles et mises en forme), JavaScript (interactivité et comportement dynamique). Des bibliothèques et des frameworks comme React, Angular, ou Vue.js sont souvent utilisés pour simplifier le développement front-end
Back-end (côté serveur) :
-
Qu'est-ce que c'est ?
Le back-end est la partie invisible d'une application web qui gère les fonctionnalités en coulisses. Cela inclut la gestion des bases de données, la logique métier, l'authentification des utilisateurs, et la gestion des requêtes provenant du front-end.
-
Technologies impliquées :
Plusieurs langages de programmation peuvent être utilisés, tels que Node.js, Python (avec Django ou Flask), Ruby (avec Ruby on Rails), PHP, Java, etc. Des bases de données comme MySQL, PostgreSQL, MongoDB sont également souvent utilisées pour stocker et récupérer des données.
Cliquez ici pour revenir au sommaire
Gestion d'une application web
Installation de MAMP
Pour installer MAMP sur votre Mac, vous devrez suivre ces étapes :
1 - Ouvrez votre navigateur :
- Cliquer sur cette url juste ici
2 - Télécharger la version :
- Pour ma part, je téléchargerai la version Mac (intel).
3 - Ouverture du .pkg :
- Suivre les instructions comme une installation classique.
4 - Installation
/Applications/MAMP/bin/mamp4 - Les répétoires important de MAMP
-
Les répertoires importants de MAMP sont au nombre de six :
-
/bin : répertoire contenant les exécutables d'Apache, PHP4, PHP5, MySQL5 et SQLite.
-
/conf : répertoire contenant les fichiers de configuration d'Apache (httpd.conf), PHP (php.ini) et SQLiteManager (config.db).
-
/tmp : répertoire contenant les fichiers temporaires créés par les exécutables. Le répertoire /tmp/php contient notamment les fichiers temporaires des sessions PHP.
-
/db : répertoire contenant les bases de données SQLite et MySQL5.
-
/logs : répertoire contenant les fichiers de logs d'erreurs de PHP, Apache et MySQL.
-
/htdocs : répertoire contenant les différents projets de sites Web. Ce dernier nous intéresse tout particulièrement car c'est dans celui-ci que nous déposerons nos sites Internet.
Cliquez ici pour revenir au sommaire
Configuration de MAMP

1 - Importer son projet
- Document root: Cliquez sur "Open In" puis "Finder" et ensuite importer votre projet dans ce répétoire.
2 - Lancer le serveur
- Cliquez sur "Start" en haut à droite et cliquez sur "WebStart" et voilà !
Cliquez ici pour revenir au sommaire
Configuration de PhpMyAdmin
PhpMyAdmin est un outil de gestion de base de données MySQL largement utilisé. Pour assurer son bon fonctionnement, une configuration appropriée est essentielle. Suivez ces étapes pour configurer PhpMyAdmin selon vos besoins.

Grâce à MAMP, PhpMyAdmin est automatiquement installé, vous pouvez y aller en allant sur cette url : localhost:8888/phpMyAdmin5/
/Applications/MAMP/bin/phpMyAdmin5Une fois que vous êtes sur l'interface de PhpMyAdmin, vous avez accès à une gamme d'outils pour gérer votre base de données MySQL. Voici quelques actions courantes que vous pouvez effectuer :
- Sélectionner une base de données : À gauche, vous verrez la liste des bases de données. Cliquez sur le nom de la base de données que vous souhaitez utiliser.
- Gérer les tables : Une fois dans une base de données, vous verrez la liste des tables. Vous pouvez effectuer des actions telles que la création, la modification ou la suppression de tables.
- Exécuter des requêtes SQL : Utilisez l'onglet "SQL" pour exécuter des requêtes SQL directement. C'est utile pour effectuer des opérations complexes ou spécifiques.
- Importer/Exporter des données : Vous pouvez importer ou exporter des bases de données ou des tables complètes. Cela peut être fait via les onglets "Importer" et "Exporter".
- Gérer les utilisateurs : L'onglet "Utilisateurs" vous permet de gérer les utilisateurs MySQL, leurs privilèges et leurs mots de passe.
- Optimiser et réparer les tables : Vous pouvez optimiser et réparer les tables pour améliorer les performances de la base de données. Cela se fait via l'onglet "Opérations".
- Afficher les statistiques : L'onglet "Statistiques" fournit des informations sur l'utilisation de la base de données, la taille des tables, etc.
- Configurer les paramètres : Dans l'onglet "Paramètres", vous pouvez configurer certaines options de PhpMyAdmin.
- Déconnexion : N'oubliez pas de vous déconnecter une fois que vous avez terminé vos opérations, surtout si vous travaillez sur un serveur partagé. Conseils supplémentaires : Documentation : N'hésitez pas à consulter la documentation officielle de PhpMyAdmin pour des informations plus détaillées et des tutoriels. Prudence avec les opérations : Faites preuve de prudence lors de l'exécution de commandes SQL, surtout si elles modifient ou suppriment des données. Sauvegardes : Avant d'apporter des modifications importantes, assurez-vous d'avoir des sauvegardes de vos bases de données. Cela devrait vous donner un bon point de départ pour explorer et utiliser PhpMyAdmin.
Cliquez ici pour revenir au sommaire
Partie SQL avec DBeaver : TP1
Veuillez répondre aux questions suivantes dans un fichier Word et rendre une copie de ce fichier avec votre TP.
-
Donnez un exemple d’ordre SQL de création de table.
-- Création d'une table "Employees" avec plusieurs colonnes CREATE TABLE Employees ( EmployeeID int, -- Identifiant de l'employé (entier) LastName varchar(255), -- Nom de famille de l'employé (chaîne de caractères, 255 caractères max) FirstName varchar(255), -- Prénom de l'employé (chaîne de caractères, 255 caractères max) Address varchar(255), -- Adresse de l'employé (chaîne de caractères, 255 caractères max) City varchar(255) -- Ville de l'employé (chaîne de caractères, 255 caractères max) );
-
Donner un exemple d’ordre SQL de type INSERT, DELETE, UPDATE.
-- Exemple d'INSERT : Ajout d'un nouvel employé INSERT INTO Employees (EmployeeID, LastName, FirstName, Address, City) VALUES (1, 'Doe', 'John', '123 Main St', 'Anytown'); -- Exemple de DELETE : Suppression de l'employé avec l'ID 1 DELETE FROM Employees WHERE EmployeeID = 1; -- Exemple d'UPDATE : Modification de la ville de l'employé avec l'ID 1 UPDATE Employees SET City = 'Newtown' WHERE EmployeeID = 1;
-
Donnez un exemple d’ordre SQL de création table qui contient également l’ordre de création d’une clé étrangère.
-- Création de la table "Orders" avec une clé étrangère liée à la table "Persons" CREATE TABLE Orders ( OrderID int, -- Identifiant de la commande (entier) OrderNumber int, -- Numéro de commande (entier) PersonID int, -- Identifiant de la personne liée à la commande (entier) PRIMARY KEY (OrderID), -- Définition de la clé primaire sur OrderID FOREIGN KEY (PersonID) REFERENCES Persons(PersonID) -- Définition de la clé étrangère liée à Persons(PersonID) );
-
Donner un exemple de suppression d’une colonne d’une table à l’aide d’un ordre SQL de type ALTER TABLE.
-- Suppression de la colonne "Address" de la table "Employees" ALTER TABLE Employees DROP COLUMN Address;
-
Donner un exemple d’ajout d’une colonne d’une table à l’aide d’un ordre SQL de type ALTER TABLE.
-- Ajout de la colonne "ZipCode" à la table "Employees" ALTER TABLE Employees ADD COLUMN ZipCode varchar(10);
-
Donner un exemple de destruction de clé étrangère à l’aide d’un ordre SQL de type ALTER TABLE.
-- Suppression de la clé étrangère liée à "PersonID" dans la table "Orders" ALTER TABLE Orders DROP FOREIGN KEY PersonID;
-
Donner un exemple de création de clé étrangère à l’aide d’un ordre SQL de type ALTER TABLE.
-- Création d'une nouvelle clé étrangère liée à "PersonID" dans la table "Orders" ALTER TABLE Orders ADD FOREIGN KEY (PersonID) REFERENCES Persons(PersonID);
Cliquez ici pour revenir au sommaire
Partie SQL avec DBeaver : TP1 (suite)
Veuillez répondre aux questions suivantes dans un fichier Word et rendre une copie de ce fichier avec votre TP. Les réponses sont basées sur la database du TP1.
Objectifs : Tester différents types d’ordre SQL
-
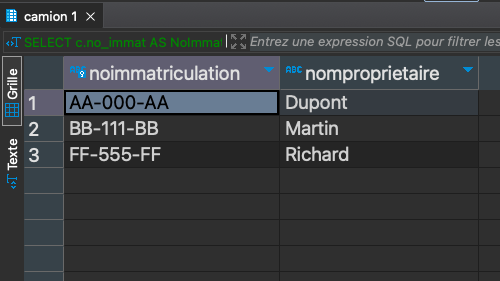
Liste des camions triés par NoImmatriculation
-- Création d'une table "Employees" avec plusieurs colonnes SELECT "nom_propriétaire", no_immat FROM public.camion ORDER BY no_immat;
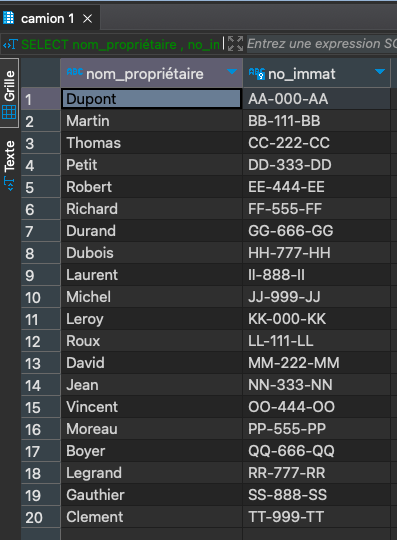
-
Liste des types de déchets triés par libellé
SELECT code_type, libelle_type FROM public.type_dechets ORDER BY libelle_type;
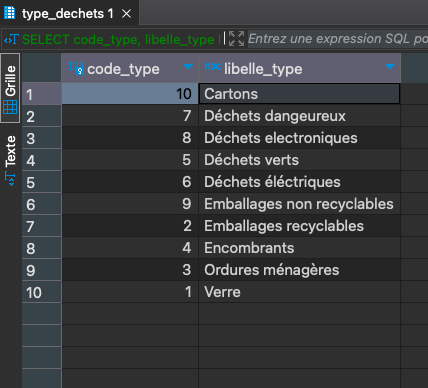
-
Liste des types de déchets transportables par camion (NoImmatriculation, NomPropriétaire, LibelléType)
SELECT c.no_immat, c."nom_propriétaire", td.libelle_type FROM public.camion c JOIN public.limitation l ON c.no_immat = l.no_immat JOIN public.type_dechets td ON l.code_type = td.code_type;
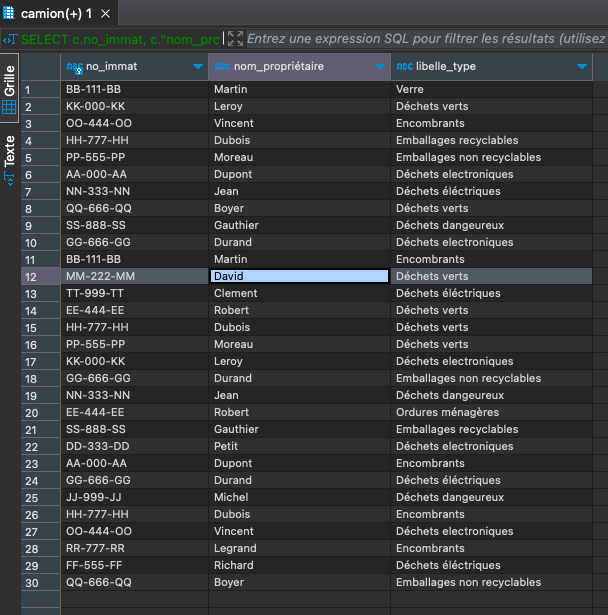
-
Liste des camions (NoImmatriculation, NomPropriétaire) qui peuvent transporter du verre
SELECT c.no_immat, c."nom_propriétaire" FROM public.camion c JOIN public.limitation l ON c.no_immat = l.no_immat JOIN public.type_dechets td ON l.code_type = td.code_type WHERE td.libelle_type = 'Verre';
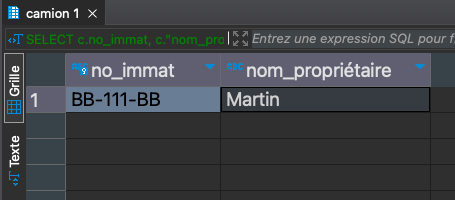
-
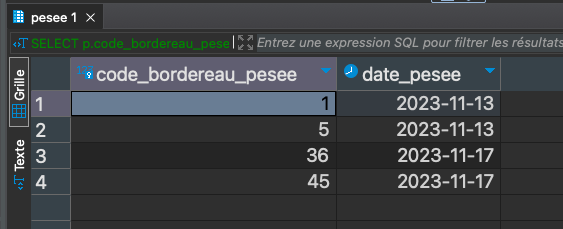
Liste des pesées (CodeBordereauPesée, DatePesée) pour le propriétaire qui a pour nom David
SELECT p.code_bordereau_pesee, p.date_pesee FROM public.pesee p JOIN public.camion c ON p.no_immat = c.no_immat WHERE c.nom_proprietaire = 'David';
-
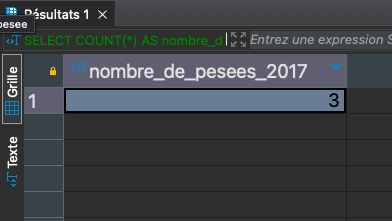
Le nombre de pesées au cours de l’année 2017
SELECT COUNT(*) AS nombre_de_pesees_2017 FROM public.pesee WHERE EXTRACT(YEAR FROM date_pesee) = 2017;
-
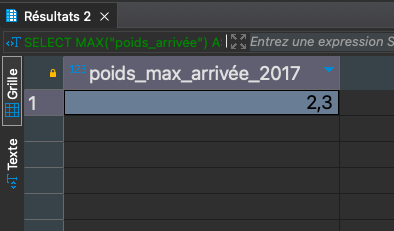
Le poids d’arrivée maximum au cours de l’année 2017
SELECT MAX("poids_arrivée") AS poids_max_arrivée FROM public.pesee WHERE EXTRACT(YEAR FROM date_pesee) = 2017;
-
Liste des camions (NoImmatriculation, NomPropriétaire) dont le poids d’arrivée était supérieur à 19T
SELECT c.no_immat AS NoImmatriculation, c.nom_propriétaire AS NomProprietaire FROM public.camion c JOIN public.pesee p ON c.no_immat = p.no_immat WHERE P.poids_arrivée > 19;
-
Poids total de 'Papiers-cartons' déposé par le syndicat SOLUTRI
SELECT SUM(p.poids_arrivée) AS Poids_Total_Papiers_Cartons FROM public.pesee p JOIN public.type_dechets td ON p.code_type = td.code_type JOIN public.syndicat s ON p.code_syndicat = s.code_syndicat WHERE td.libelle_type = 'Cartons' AND s.nom_syndicat = 'Syndicat5';
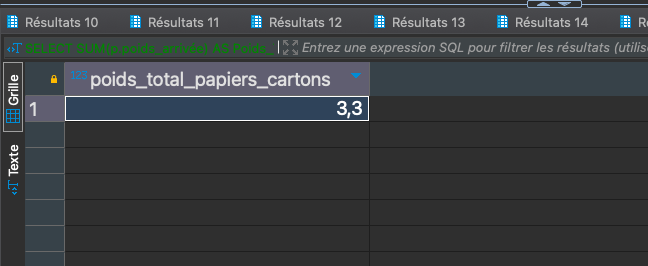
-
Différents syndicats (nom et adresse) qui ont déposé du verre, triés par ordre alphabétique sur le nom de syndicat
SELECT DISTINCT s.nom_syndicat, s.adresse_syndicat FROM public.pesee p JOIN public.syndicat s ON p.code_syndicat = s.code_syndicat JOIN public.type_dechets td ON p.code_type = td.code_type WHERE td.libelle_type = 'Verre' ORDER BY s.nom_syndicat;
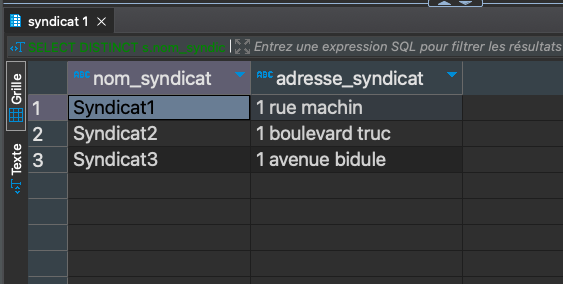
-
Poids total de déchets déposé par syndicat et par type de déchet
SELECT s.nom_syndicat, td.libelle_type, SUM("poids_arrivée") AS poids_total FROM public.pesee p JOIN public.syndicat s ON p.code_syndicat = s.code_syndicat JOIN public.type_dechets td ON p.code_type = td.code_type GROUP BY s.nom_syndicat, td.libelle_type ORDER BY s.nom_syndicat, td.libelle_type;
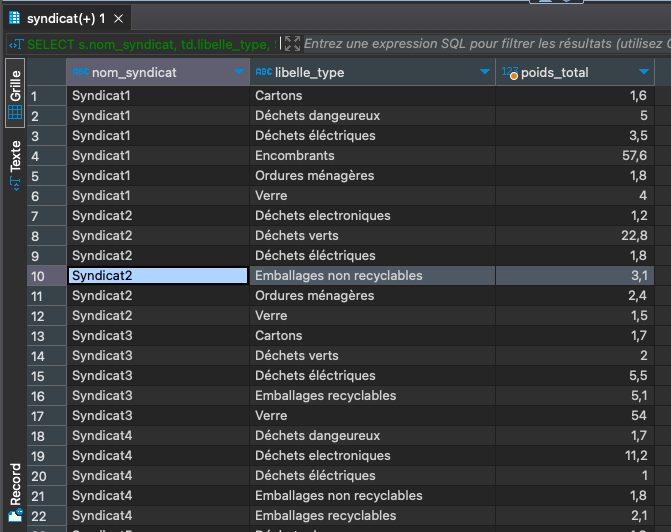
-
Liste des types de déchets (LibelléType) qui n’ont jamais été pesés
SELECT libelle_type FROM public.type_dechets WHERE code_type NOT IN (SELECT code_type FROM public.pesee);
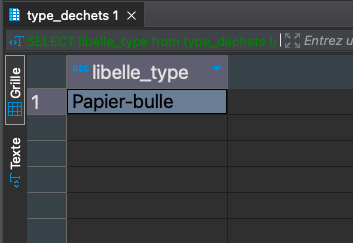












Cliquez ici pour revenir au sommaire
Créé avec ❤️ par Dimitri Chassignol - 2024