作者:肖桐 (Tong Xiao) 朱靖波 (Jingbo Zhu)
单位:东北大学自然语言处理实验室 (NEUNLPLab) / 小牛翻译 (NiuTrans Research)
顾问:姚天顺 (Tianshun Yao) 王宝库 (Baoku Wang)
网站:https://opensource.niutrans.com/mtbook/index.html
GitHub:https://github.com/NiuTrans/MTBook
这是一个教程,目的是对机器翻译的统计建模和深度学习方法进行较为系统的介绍。其内容被编纂成书,可以供计算机相关专业高年级本科生及研究生学习之用,亦可作为自然语言处理,特别是机器翻译相关研究人员的参考资料。本书用tex编写,所有源代码均已开放。
本书共分为七个章节,章节的顺序参考了机器翻译技术发展的时间脉络,同时兼顾了机器翻译知识体系的内在逻辑。各章节的主要关系如下(如果无法显示图片可以稍后再试):
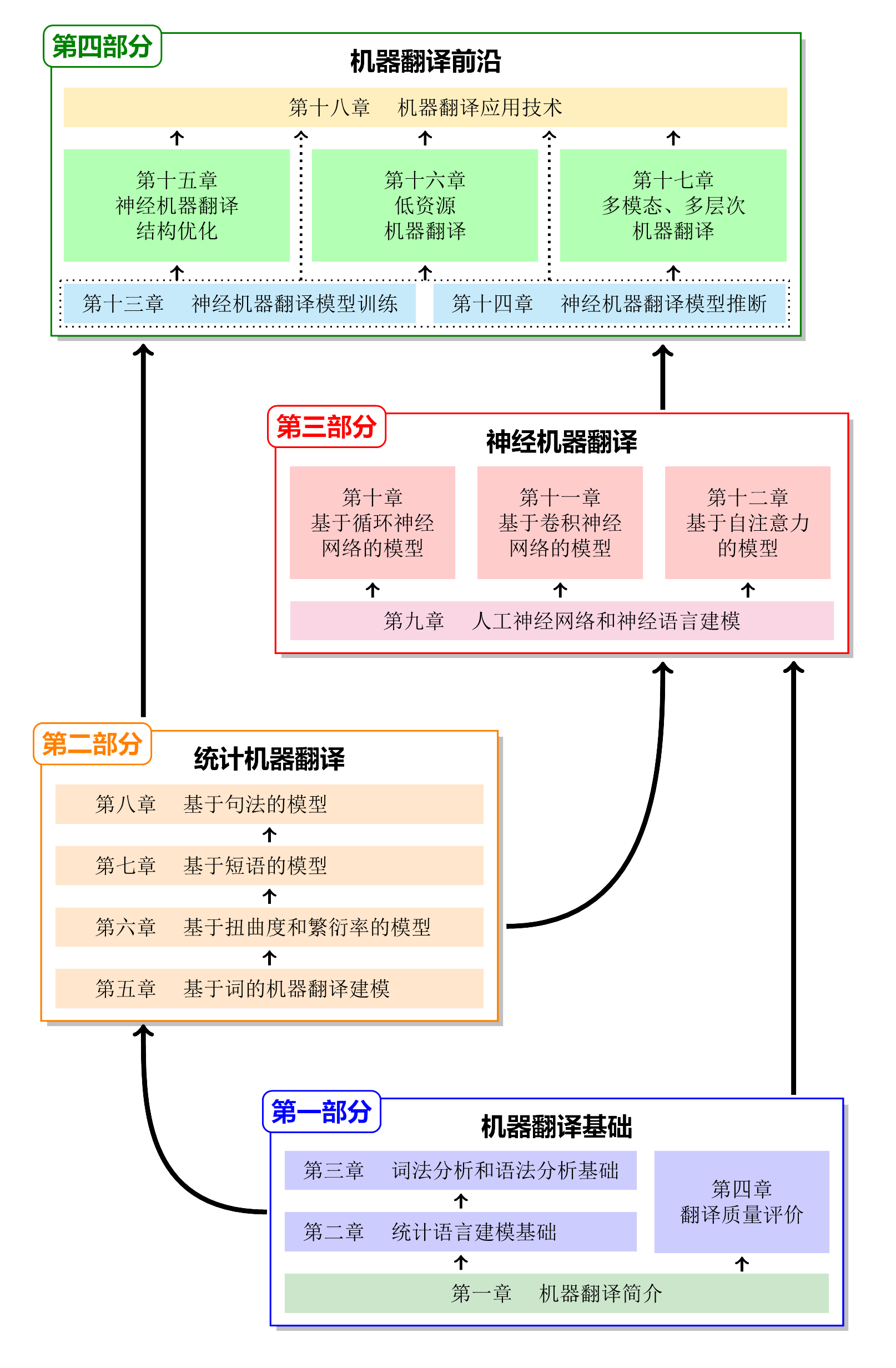
Part I 机器翻译基础
- 机器翻译简介
- 词法、语法及统计建模基础
Part II 统计机器翻译
- 基于词的机器翻译模型
- 3.1 什么是基于词的翻译模型
- 3.2 构建一个简单的机器翻译系统
- 3.3 基于词的翻译建模
- 3.4 IBM 模型 1-2
- 3.5 IBM 模型 3-5 及隐马尔可夫模型
- 3.6 问题分析
- 3.7 小结及深入阅读
- 基于短语和句法的机器翻译模型
Part III 神经机器翻译
- 人工神经网络和神经语言建模
- 神经机器翻译模型
- 神经机器翻译实战
Part IV 附录
注:本书的pdf版本可以从GitHub仓库获取https://github.com/NiuTrans/MTBook/blob/master/mt-book.pdf
本书的tex源代码地址为:https://github.com/NiuTrans/MTBook
编译前需要安装MikTeX,并在MikTeX Console中下载并更新编译所需宏包。之后,编译src目录下的mt-book-xelatex.tex即可得到pdf文件,编译指令如下:
xelatex mt-book-xelatex
biber mt-book-xelatex
makeindex mt-book-xelatex
xelatex mt-book-xelatex在编译中可能会遇到内存不足的问题,可以通过以下方式解决:
-
运行cmd打开命令行窗口,输入:
initexmf --edit-config-file=xelatex -
在弹出的文件中输入以下内容:
main_memory=5000000 extra_mem_bot=5000000 font_mem_size=5000000 pool_size=5000000 buf_size=5000000 -
在cmd窗口输入:
initexmf --dump=xelatex更新latex格式文件
-
打开texmf.cnf文件,更改其内容为:
main_memory=5000000 extra_mem_bot=5000000 font_mem_size=5000000 pool_size=5000000 buf_size=5000000 -
调用texhash更新latex格式文件
注:编译tex文件会依赖一些宏包。如果有任何编译错误,建议将宏包更新至最新版本。
本书的开源内容基于The Creative Commons Attribution-NonCommercial 4.0 Unported License(link)
感谢为本书做出贡献的小牛团队(部分)成员
曹润柘、曾信、孟霞、单韦乔、姜雨帆、王子扬、刘辉、许诺、李北、刘继强、张哲旸、周书含、周涛、张裕浩、李炎洋、林野、陈贺轩、刘晓倩、牛蕊、田丰宁、杜权、李垠桥、许晨、张裕浩、胡驰、冯凯、王泽洋、刘腾博、刘兴宇、徐萍、赵闯、高博、张春良、王会珍、张俐、杨木润、宁义明、李洋、秦浩、胡明涵
有任何问题请联系xiaotong [at] mail.neu.edu.cn (肖桐) 或 854581319 [at] qq.com(曹润柘)