

A relay for carbon streams, in go. Like carbon-relay from the graphite project, except it:
- performs better: should be able to do about 100k ~ 1M million metrics per second depending on configuration and CPU speed.
- you can adjust the routing table at runtime, in real time using the web or telnet interface (though they may have some rough edges)
- has aggregator functionality built-in for cross-series, cross-time and cross-time-and-series aggregations.
- supports plaintext and pickle graphite routes (output) and metrics2.0/grafana.net, as well as kafka and Google PubSub.
- graphite routes supports a per-route spooling policy. (i.e. in case of an endpoint outage, we can temporarily queue the data up to disk and resume later)
- performs validation on all incoming metrics (see below)
- supported inputs: plaintext, pickle and AMQP (rabbitmq)
This makes it easy to fanout to other tools that feed in on the metrics. Or balance/split load, or provide redundancy, or partition the data, etc. This pattern allows alerting and event processing systems to act on the data as it is received (which is much better than repeated reading from your storage)
- regex rewriter rules do not support limiting number of replacements, max must be set to -1
- the web UI is not always reliable to make changes. the config file and tcp interface are safer and more complete anyway.
- internal metrics must be routed somewhere (e.g. into the relay itself) otherwise it'll leak memory. this is a silly bug but I haven't had time yet to fix it.
see https://github.com/graphite-ng/carbon-relay-ng/releases
- Extensive performance variables are available in json at http://localhost:8081/debug/vars2 (update port if you change it in config)
- You can also send metrics to graphite (or feed back into the relay), see config.
- Comes with a grafana dashboard which you can also download from the grafana dashboards site
You can install packages from the raintank packagecloud repository We automatically build packages for Ubuntu 14.04 (trusty), 16.04 (xenial), debian 8, 9, 10 (jessie, stretch and buster/testing), Centos6 and Centos7 when builds in CircleCI succeed. Instructions for enabling the repository
You can also just build a binary (see below) and run the binary with a config file like so:
carbon-relay-ng [-cpuprofile cpuprofile-file] config-file
Requires Go 1.7 or higher. We use https://github.com/kardianos/govendor to manage vendoring 3rd party libraries
export GOPATH=/some/path/
export PATH="$PATH:$GOPATH/bin"
go get -d github.com/graphite-ng/carbon-relay-ng
go get github.com/jteeuwen/go-bindata/...
cd "$GOPATH/src/github.com/graphite-ng/carbon-relay-ng"
# optional: check out an older version: git checkout v0.5
make
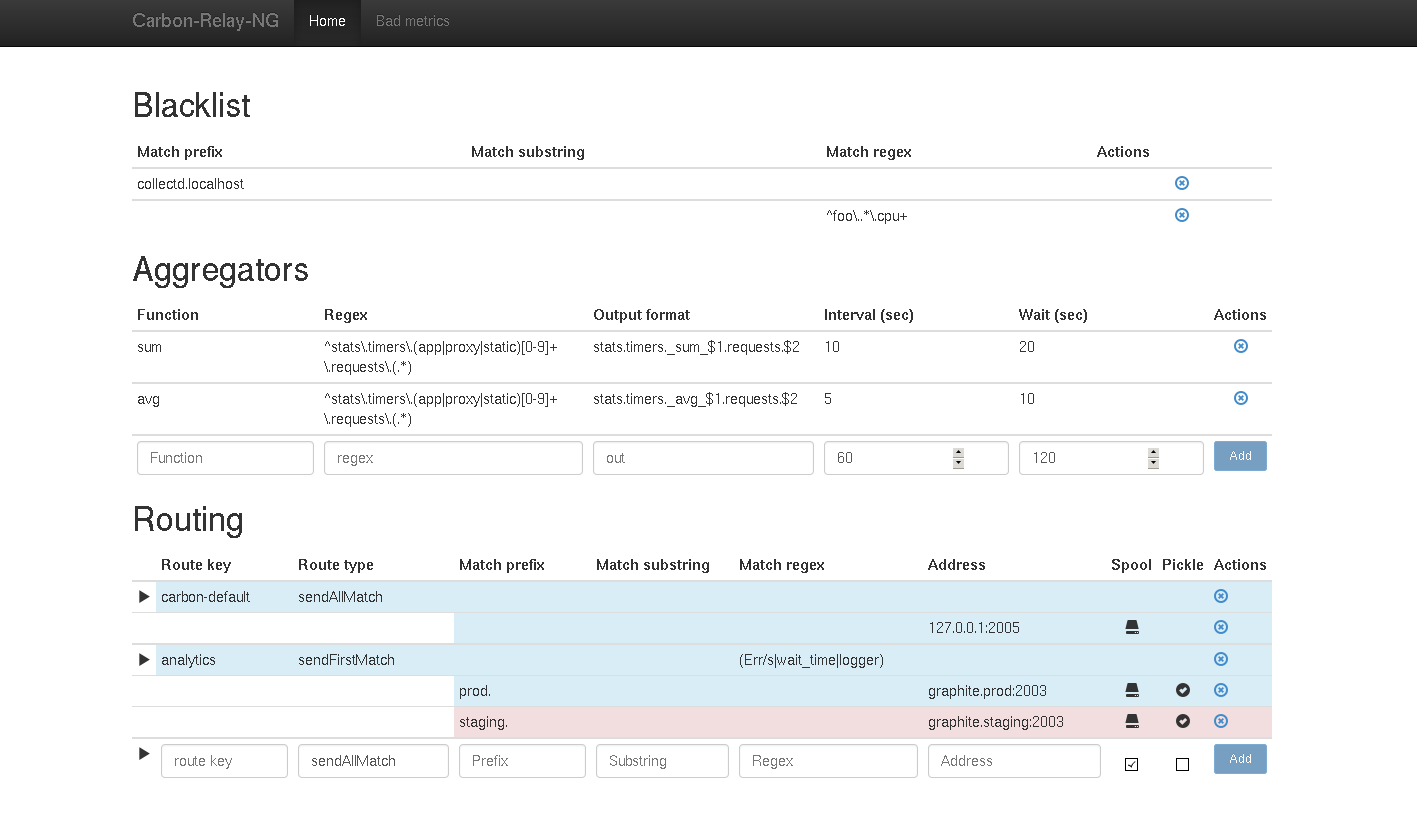
You have 1 master routing table. This table contains 0-N routes. Each carbon route can contain 0-M destinations (tcp endpoints)
First: "matching": you can match metrics on one or more of: prefix, substring, or regex. All 3 default to "" (empty string, i.e. allow all). The conditions are AND-ed. Regexes are more resource intensive and hence should - and often can be - avoided.
-
All incoming metrics are validated and go into the table when valid.
-
The table will then check metrics against the blacklist and discard when appropriate.
-
Then metrics pass through the rewriters and are modified if applicable. Rewrite rules wrapped with forward slashes are interpreted as regular expressions.
-
The table sends the metric to:
- the aggregators, who match the metrics against their rules, compute aggregations and feed results back into the table. see Aggregation section below for details.
- any routes that matches
-
The route can have different behaviors, based on its type:
- for grafanaNet / kafkaMdm / Google PubSub routes, there is only a single endpoint so that's where the data goes. For standard/carbon routes you can control how data gets routed into destinations:
- sendAllMatch: send all metrics to all the defined endpoints (possibly, and commonly only 1 endpoint).
- sendFirstMatch: send the metrics to the first endpoint that matches it.
- consistentHashing: the algorithm is the same as Carbon's consistent hashing.
- round robin: the route is a RR pool (not implemented)
carbon-relay-ng (for now) focuses on staying up and not consuming much resources.
For carbon routes: if connection is up but slow, we drop the data if connection is down and spooling enabled. we try to spool but if it's slow we drop the data if connection is down and spooling disabled -> drop the data
kafka, Google PubSub, and grafanaNet have an in-memory buffer and can be configured to blocking or non-blocking mode when the buffer runs full.
As with the Python implementation of carbon-relay, metrics can be pushed to carbon-relay-ng via TCP
(plain text or pickle) or by using an AMQP broker such as RabbitMQ. To send metrics via AMQP, create
a topic exchange (named "metrics" in the example carbon-relay-ng.ini) and publish messages to it in
the usual metric format: <metric path> <metric value> <metric timestamp>. An exclusive, ephemeral
queue will automatically be created and bound to the exchange, which carbon-relay-ng will consume from.
All incoming metrics undergo some basic sanity checks before the metrics go into the routing table. We always check the following:
- the value parses to an int or float
- the timestamp is a unix timestamp
By default, we also apply the following checks to the metric name:
- has 3 fields
- the key has no characters beside
a-z A-Z _ - . =(fairly strict but graphite causes problems with various other characters) - has no empty node (like field1.field2..field4)
However, for legacy metrics, the legacy_metric_validation configuration parameter can be used to loosen the metric name checks. This can be useful when needing to forward metrics whose names you do not control.
The following are valid values for the legacy_metric_validation field:
strict-- All checks described above are in force. This is the default.medium-- We validate that the metric name has only ASCII characters and no embedded NULLs.none-- No metric name checks are performed.
If we detect the metric is in metrics2.0 format we also check proper formatting, and unit and mtype are set.
Invalid metrics are dropped and can be seen at /badMetrics/timespec.json where timespec is something like 30s, 10m, 24h, etc. (the counters are also exported. See instrumentation section)
You can also validate that for each series, each point is older than the previous. using the validate_order option. This is helpful for some backends like grafana.net
As discussed in concepts above, we can combine, at each point in time, the points of multiple series into a new series. Note:
- The interval parameter let's you quantize ("fix") timestamps, for example with an interval of 60 seconds, if you have incoming metrics for times that differ from each other, but all fall within the same minute, they will be counted together.
- The wait parameter allows up to the specified amount of seconds to wait for values, With a wait of 120, metrics can come 2 minutes late and still be included in the aggregation results.
- The fmt parameter dictates what the metric key of the aggregated metric will be. use $1, $2, etc to refer to groups in the regex Multi-value aggregators (currently only percentiles) add .pxx at the end of the various metrics they emit. Single-value aggregators (currently all others) don't, allowing you to specify keywords like avg, sum, etc wherever into the fmt string you want.
- Note that we direct incoming values to an aggregation bucket based on the interval the timestamp is in, and the output key it generates.
This means that you can have 3 aggregation cases, based on how you set your regex, interval and fmt string.
- aggregation of points with different metric keys, but with the same, or similar timestamps) into one outgoing value (~ carbon-aggregator). if you set the interval to the period between each incoming packet of a given key, and the fmt yields the same key for different input metric keys
- aggregation of individual metrics, i.e. packets for the same key, with different timestamps. For example if you receive values for the same key every second, you can aggregate into minutely buckets by setting interval to 60, and have the fmt yield a unique key for every input metric key. (~ graphite rollups)
- the combination: compute aggregates from values seen with different keys, and at multiple points in time.
- functions currently available: avg, delta, derive, last, max, min, stdev, sum, percentiles
- aggregation output is routed via the routing table just like all other metrics. Note that aggregation output will never go back into aggregators (to prevent loops) and also bypasses the validation and blacklist and rewriters.
- see the included ini for examples
- each aggregator can be configured to cache regex matches or not. there is no cache size limit because a limited size, under a typical workload where we see each metric key sequentially, in perpetual cycles, would just result in cache thrashing and wasting memory. If enabled, all matches are cached for at least 100 times the wait parameter. By default, the cache is enabled for aggregators set up via commands (init commands in the config) but disabled for aggregators configured via config sections (due to a limitation in our config library). Basically enabling the cache means you trade in RAM for cpu.
- each aggregator may have a prefix and/or substring specified, these are used to reduce overhead by pre-filtering the metrics before they are matched against the regex (if not specified the prefix will be derived from the regex where possible).
Series names can be rewritten as they pass through the system by Rewriter rules, which are processed in series.
Basic rules use simple old/new text replacement, and support a Max parameter to specify the maximum number of matched items to be replaced.
Rewriter rules also support regexp syntax, which is enabled by wrapping the "old" parameter with forward slashes and setting "max" to -1.
Regexp rules support golang's standard regular expression syntax, and the "new" value can include submatch identifiers in the format ${1}.
Examples (using init commands. you can also specify them in the config directly. see the included config):
# basic rewriter rule to replace first occurrence of "foo" with "bar"
addRewriter foo bar 1
# regexp rewriter rule to add a prefix of "prefix." to all series
addRewriter /^/ prefix. -1
# regexp rewriter rule to replace "server.X" with "servers.X.collectd"
addRewriter /server\.([^.]+)/ servers.${1}.collectd -1
Take a look at the included carbon-relay-ng.ini, which includes comments describing the available options.
The major config sections are the blacklist array, and the [[aggregation]], [[rewriter]] and [[route]] entries.
Overview of all routes/destinations config options and tuning options
You can also create routes, populate the blacklist, etc via the init config array using the same commands as the telnet interface, detailed below.
commands:
help show this menu
view view full current routing table
addBlack <prefix|sub|regex> <substring> blacklist (drops matching metrics as soon as they are received)
addRewriter <old> <new> <max> add rewriter that will rewrite all old to new, max times
use /old/ to specify a regular expression match, with support for ${1} style identifiers in new
addAgg <func> <match> <fmt> <interval> <wait> [cache=true/false] add a new aggregation rule.
<func>: aggregation function to use
avg
delta
derive
last
max
min
stdev
sum
<match>
regex=<str> mandatory. regex to match incoming metrics. supports groups (numbered, see fmt)
sub=<str> substring to match incoming metrics before matching regex (can save you CPU)
prefix=<str> prefix to match incoming metrics before matching regex (can save you CPU). If not specified, will try to automatically determine from regex.
<fmt> format of output metric. you can use $1, $2, etc to refer to numbered groups
<interval> align odd timestamps of metrics into buckets by this interval in seconds.
<wait> amount of seconds to wait for "late" metric messages before computing and flushing final result.
addRoute <type> <key> [opts] <dest> [<dest>[...]] add a new route. note 2 spaces to separate destinations
<type>:
sendAllMatch send metrics in the route to all destinations
sendFirstMatch send metrics in the route to the first one that matches it
consistentHashing distribute metrics between destinations using a hash algorithm
<opts>:
prefix=<str> only take in metrics that have this prefix
sub=<str> only take in metrics that match this substring
regex=<regex> only take in metrics that match this regex (expensive!)
<dest>: <addr> <opts>
<addr> a tcp endpoint. i.e. ip:port or hostname:port
for consistentHashing routes, an instance identifier can also be present:
hostname:port:instance
The instance is used to disambiguate multiple endpoints on the same host, as the Carbon-compatible consistent hashing algorithm does not take the port into account.
<opts>:
prefix=<str> only take in metrics that have this prefix
sub=<str> only take in metrics that match this substring
regex=<regex> only take in metrics that match this regex (expensive!)
flush=<int> flush interval in ms
reconn=<int> reconnection interval in ms
pickle={true,false} pickle output format instead of the default text protocol
spool={true,false} enable spooling for this endpoint
connbuf=<int> connection buffer (how many metrics can be queued, not written into network conn). default 30k
iobuf=<int> buffered io connection buffer in bytes. default: 2M
spoolbuf=<int> num of metrics to buffer across disk-write stalls. practically, tune this to number of metrics in a second. default: 10000
spoolmaxbytesperfile=<int> max filesize for spool files. default: 200MiB (200 * 1024 * 1024)
spoolsyncevery=<int> sync spool to disk every this many metrics. default: 10000
spoolsyncperiod=<int> sync spool to disk every this many milliseconds. default 1000
spoolsleep=<int> sleep this many microseconds(!) in between ingests from bulkdata/redo buffers into spool. default 500
unspoolsleep=<int> sleep this many microseconds(!) in between reads from the spool, when replaying spooled data. default 10
addDest <routeKey> <dest> not implemented yet
modDest <routeKey> <dest> <opts>: modify dest by updating one or more space separated option strings
addr=<addr> new tcp address
prefix=<str> new matcher prefix
sub=<str> new matcher substring
regex=<regex> new matcher regex
modRoute <routeKey> <opts>: modify route by updating one or more space separated option strings
prefix=<str> new matcher prefix
sub=<str> new matcher substring
regex=<regex> new matcher regex
delRoute <routeKey> delete given route