
- We provide training scripts for new styles, offering an automatic training for new style LoRas as well as the corresponding style prompts, along with the one click call in Infinite Style Portrait generation tab! (July 3rd, 2024 UTC)
- 🚀🚀🚀 We are launching [FACT] into the main branch, offering a 10-second impressive speed and seamless integration with standard ready-to-use LoRas and ControlNets, along with improved instruction-following capabilities ! The original train-based FaceChain is moved to (https://github.com/modelscope/facechain/tree/v3.0.0 ). (May 28th, 2024 UTC)
- Our work FaceChain-ImagineID and FaceChain-SuDe got accepted to CVPR 2024 ! (February 27th, 2024 UTC)
如果您熟悉中文,可以阅读中文版本的README。
FaceChain is a novel framework for generating identity-preserved human portraits. In the newest FaceChain FACT (Face Adapter with deCoupled Training) version, with only 1 photo and 10 seconds, you can generate personal portraits in different settings (multiple styles now supported!). FaceChain has both high controllability and authenticity in portrait generation, including text-to-image and inpainting based pipelines, and is seamlessly compatible with ControlNet and LoRAs. You may generate portraits via FaceChain's Python scripts, or via the familiar Gradio interface, or via sd webui. FaceChain is powered by ModelScope.
ModelScope Studio 🤖 |API 🔥 | SD WebUI | HuggingFace Space 🤗


- We provide training scripts for new styles, offering an automatic training for new style LoRas as well as the corresponding style prompts, along with the one click call in Infinite Style Portrait generation tab! (July 3rd, 2024 UTC)
- 🚀🚀🚀 We are launching [FACT], offering a 10-second impressive speed and seamless integration with standard ready-to-use LoRas and ControlNets, along with improved instruction-following capabilities ! (May 28th, 2024 UTC)
- Our work FaceChain-ImagineID and FaceChain-SuDe got accepted to CVPR 2024 ! (February 27th, 2024 UTC)
- 🏆🏆🏆Alibaba Annual Outstanding Open Source Project, Alibaba Annual Open Source Pioneer (Yang Liu, Baigui Sun). (January 20th, 2024 UTC)
- Our work InfoBatch co-authored with NUS team got accepted to ICLR 2024(Oral)! (January 16th, 2024 UTC)
- 🏆OpenAtom's 2023 Rapidly Growing Open Source Projects Award. (December 20th, 2023 UTC)
- Add SDXL pipeline🔥🔥🔥, image detail is improved obviously. (November 22th, 2023 UTC)
- Support super resolution🔥🔥🔥, provide multiple resolution choice (512512, 768768, 10241024, 20482048). (November 13th, 2023 UTC)
- 🏆FaceChain has been selected in the BenchCouncil Open100 (2022-2023) annual ranking. (November 8th, 2023 UTC)
- Add virtual try-on module. (October 27th, 2023 UTC)
- Add wanx version online free app. (October 26th, 2023 UTC)
- 🏆1024 Programmer's Day AIGC Application Tool Most Valuable Business Award. (2023-10-24, 2023 UTC)
- Support FaceChain in stable-diffusion-webui🔥🔥🔥. (October 13th, 2023 UTC)
- High performance inpainting for single & double person, Simplify User Interface. (September 09th, 2023 UTC)
- More Technology Details can be seen in Paper. (August 30th, 2023 UTC)
- Add validate & ensemble for Lora training, and InpaintTab(hide in gradio for now). (August 28th, 2023 UTC)
- Add pose control module. (August 27th, 2023 UTC)
- Add robust face lora training module, enhance the performance of one pic training & style-lora blending. (August 27th, 2023 UTC)
- HuggingFace Space is available now! You can experience FaceChain directly with 🤗 (August 25th, 2023 UTC)
- Add awesome prompts! Refer to: awesome-prompts-facechain (August 18th, 2023 UTC)
- Support a series of new style models in a plug-and-play fashion. (August 16th, 2023 UTC)
- Support customizable prompts. (August 16th, 2023 UTC)
- Colab notebook is available now! You can experience FaceChain directly with
. (August 15th, 2023 UTC)
- Develop RLHF methods, make its quality more higher.
- Support more beauty-retouch effects.
- Provide more funny apps.
Please cite FaceChain in your publications if it helps your research
@article{liu2023facechain,
title={FaceChain: A Playground for Identity-Preserving Portrait Generation},
author={Liu, Yang and Yu, Cheng and Shang, Lei and Wu, Ziheng and
Wang, Xingjun and Zhao, Yuze and Zhu, Lin and Cheng, Chen and
Chen, Weitao and Xu, Chao and Xie, Haoyu and Yao, Yuan and
Zhou, Wenmeng and Chen Yingda and Xie, Xuansong and Sun, Baigui},
journal={arXiv preprint arXiv:2308.14256},
year={2023}
}
We have verified e2e execution on the following environment:
- python: py3.8, py3.10
- pytorch: torch2.0.0, torch2.0.1
- CUDA: 11.7
- CUDNN: 8+
- OS: Ubuntu 20.04, CentOS 7.9
- GPU: Nvidia-A10 24G
Jemalloc are recommanded to install for optimizing the memory from above 30G to below 20G. Here is an example for installing Jemalloc in Modelscope notebook.
apt-get install -y libjemalloc-dev
export LD_PRELOAD=/lib/x86_64-linux-gnu/libjemalloc.soThe following installation methods are supported:
The ModelScope Notebook offers a free-tier that allows ModelScope user to run the FaceChain application with minimum setup, refer to ModelScope Notebook
# Step1: 我的notebook -> PAI-DSW -> GPU环境
# Note: Please use: ubuntu20.04-py38-torch2.0.1-tf1.15.5-modelscope1.8.1
# Step2: Entry the Notebook cell,clone FaceChain from github:
!GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git --depth 1
# Step3: Change the working directory to facechain, and install the dependencies:
import os
os.chdir('/mnt/workspace/facechain') # You may change to your own path
print(os.getcwd())
!pip3 install gradio==3.47.1
!pip3 install controlnet_aux==0.0.6
!pip3 install python-slugify
!pip3 install diffusers==0.29.0
!pip3 install peft==0.11.1
# Step4: Start the app service, click "public URL" or "local URL", upload your images to
# train your own model and then generate your digital twin.
!python3 app.py
Alternatively, you may also purchase a PAI-DSW instance (using A10 resource), with the option of ModelScope image to run FaceChain following similar steps.
If you are familiar with using docker, we recommend to use this way:
# Step1: Prepare the environment with GPU on local or cloud, we recommend to use Alibaba Cloud ECS, refer to: https://www.aliyun.com/product/ecs
# Step2: Download the docker image (for installing docker engine, refer to https://docs.docker.com/engine/install/)
# For China Mainland users:
docker pull registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.7.1-py38-torch2.0.1-tf1.15.5-1.8.1
# For users outside China Mainland:
docker pull registry.us-west-1.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.7.1-py38-torch2.0.1-tf1.15.5-1.8.1
# Step3: run the docker container
docker run -it --name facechain -p 7860:7860 --gpus all registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.7.1-py38-torch2.0.1-tf1.15.5-1.8.1 /bin/bash
# Note: you may need to install the nvidia-container-runtime, follow the instructions:
# 1. Install nvidia-container-runtime:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
# 2. sudo systemctl restart docker
# Step4: Install the gradio in the docker container:
pip3 install gradio==3.47.1
pip3 install controlnet_aux==0.0.6
pip3 install python-slugify
pip3 install diffusers==0.29.0
pip3 install peft==0.11.1
# Step5 clone facechain from github
GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git --depth 1
cd facechain
python3 app.py
# Note: FaceChain currently assume single-GPU, if your environment has multiple GPU, please use the following instead:
# CUDA_VISIBLE_DEVICES=0 python3 app.py
# Step6
Run the app server: click "public URL" --> in the form of: https://xxx.gradio.live-
Select the
Extensions Tab, then chooseInstall From URL(official plugin integration is intergrated, please install from URL currently).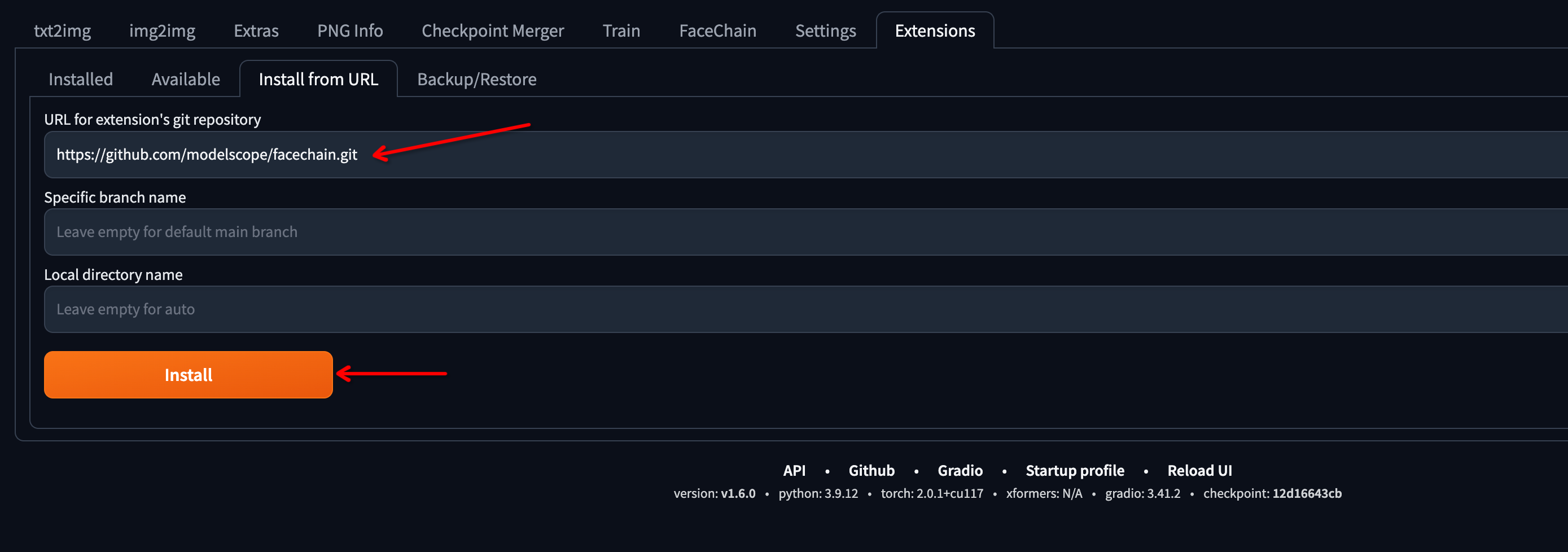
-
Switch to
Installed, check the FaceChain plugin, then clickApply and restart UI. It may take a while for installing the dependencies and downloading the models. Make sure that the "CUDA Toolkit" is installed correctly, otherwise the "mmcv" package cannot be successfully installed.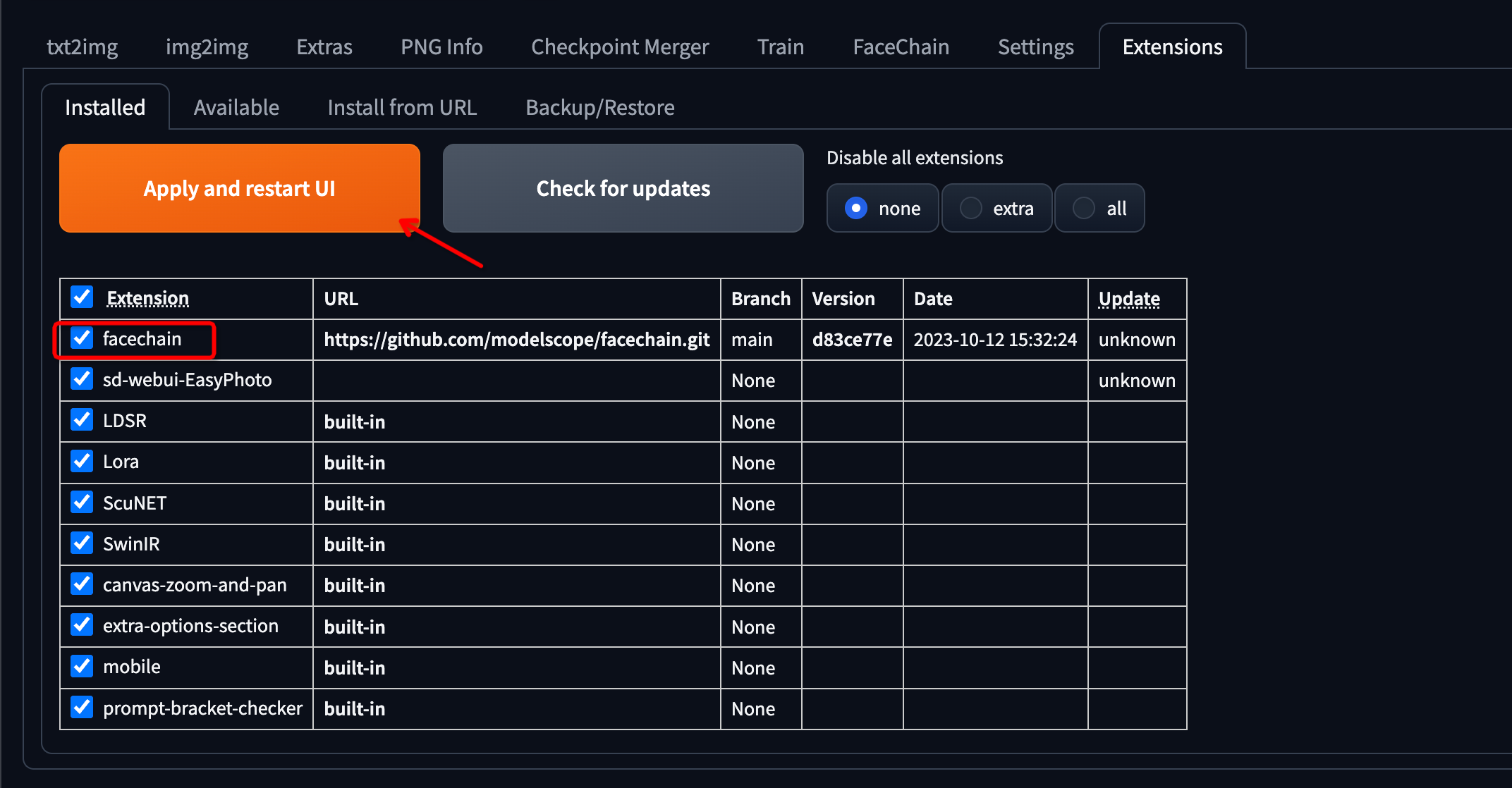
-
After the page refreshes, the appearance of the
FaceChainTab indicates a successful installation.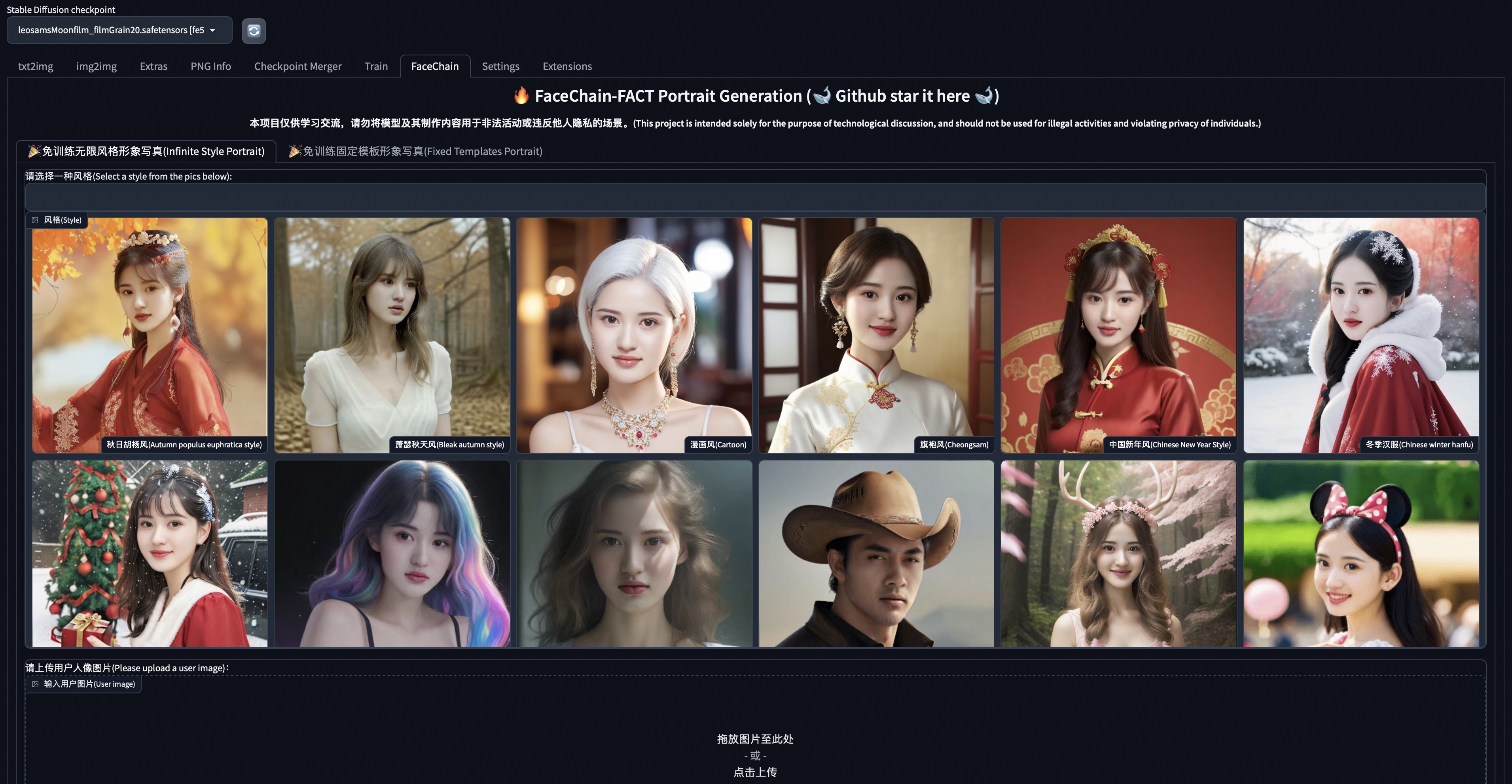



FaceChain supports direct inference in the python environment. When inferring for Infinite Style Portrait generation, please edit the code in run_inference.py:
# Use pose control, default False
use_pose_model = False
# The path of the input image containing ID information for portrait generation
input_img_path = 'poses/man/pose2.png'
# The path of the image for pose control, only effective when using pose control
pose_image = 'poses/man/pose1.png'
# The number of images to generate in inference
num_generate = 5
# The weight for the style model, see styles for detail
multiplier_style = 0.25
# Specify a folder to save the generated images, this parameter can be modified as needed
output_dir = './generated'
# The index of the chosen base model, see facechain/constants.py for detail
base_model_idx = 0
# The index of the style model, see styles for detail
style_idx = 0Then execute:
python run_inference.pyYou can find the generated personal digital image photos in the output_dir.
When inferring for Fixed Templates Portrait generation, please edit the code in run_inference_inpaint.py.
# Number of faces for the template image
num_faces = 1
# Index of face for inpainting, counting from left to right
selected_face = 1
# The strength for inpainting, you do not need to change the parameter
strength = 0.6
# The path of the template image
inpaint_img = 'poses/man/pose1.png'
# The path of the input image containing ID information for portrait generation
input_img_path = 'poses/man/pose2.png'
# The number of images to generate in inference
num_generate = 1
# Specify a folder to save the generated images, this parameter can be modified as needed
output_dir = './generated_inpaint'Then execute:
python run_inference_inpaint.pyYou can find the generated personal digital image photos in the output_dir.
The capability of AI portraits generation comes from the large generative models like Stable Diffusion and its fine-tuning techniques. Due to the strong generalization capability of large models, it is possible to perform downstream tasks by fine-tuning on specific types of data and tasks, while preserving the model's overall ability of text following and image generation. The technical foundation of train-based and train-free AI portraits generation comes from applying different fine-tuning tasks to generative models. Currently, most existing AI portraits tools adopt a two-stage “train then generate” pipeline, where the fine-tuning task is “to generate portrait photos of a fixed character ID”, and the corresponding training data are multiple images of the fixed character ID. The effectiveness of such train-based pipeline depends on the scale of the training data, thus requiring certain image data support and training time, which also increases the cost for users.
Different from train-based pipeline, train-free pipeline adjusts the fine-tuning task to “generate portrait photos of a specified character ID”, meaning that the character ID image (face photo) is used as an additional input, and the output is a portrait photo preserving the input ID. Such a pipeline completely separates offline training from online inference, allowing users to generate portraits directly based on the fine-tuned model with only one photo in just 10 seconds, avoiding the cost for extensive data and training time. The fine-tuning task of train-free AI portraits generation is based on the adapter module. Face photos are processed through an image encoder with fixed weights and a parameter-efficient feature projection layer to obtain aligned features, and are then fed into the U-Net model of Stable Diffusion through attention mechanism similar as text conditions. At this point, face information as an independent branch condition is fed into the model alongside text information for inference, thereby enabling the generated images to maintain ID fidelity.
The basic algorithm based on face adapter is capable of achieving train-free AI portraits, but still requires certain adjustments to further improve its effectiveness. Existing train-free portrait tools generally suffer from the following issues: poor image quality of portraits, inadequate text following and style retention abilities in portraits, poor controllability and richness of portrait faces, and poor compatibility with extensions like ControlNet and style Lora. To address these issues, FaceChain attribute them to the fact that the fine-tuning tasks for existing train-free AI portrait tools have coupled with too much information beyond character IDs, and propose FaceChain Face Adapter with Decoupled Training (FaceChain FACT) to solve these problems. By fine-tuning the Stable Diffusion model on millions of portrait data, FaceChain FACT can achieve high-quality portrait image generation for specified character IDs. The entire framework of FaceChain FACT is shown in the figure below.

The decoupled training of FaceChain FACT consists of two parts: decoupling face from image, and decoupling ID from face. Existing methods often treat denoising portrait images as the fine-tuning task, which makes the model hard to accurately focus on the face area, thereby affecting the text-to-image ability of the base Stable Diffusion model. FaceChain FACT draws on the sequential processing and regional control advantages of face-swapping algorithms and implements the fine-tuning method for decoupling faces from images from both structural and training strategy aspects. Structurally, unlike existing methods that use a parallel cross-attention mechanism to process face and text information, FaceChain FACT adopts a sequential processing approach as an independent adapter layer inserted into the original Stable Diffusion's blocks. This way, face adaptation acts as an independent step similar to face-swapping during the denoising process, avoiding interference between face and text conditions. In terms of training strategy, besides the original MSE loss function, FaceChain FACT introduces the Face Adapting Incremental Regularization (FAIR) loss function, which controls the feature increment of the face adaptation step in the adapter layer to focus on the face region. During inference, users can flexibly adjust the generated effects by modifying the weight of the face adapter, balancing fidelity and generalization of the face while maintaining the text-to-image ability of Stable Diffusion. The FAIR loss function is formulated as follows:

Furthermore, addressing the issue of poor controllability and richness of generated faces, FaceChain FACT proposes a training method for decoupling ID from face, so that the portrait process only preserves the character ID rather than the entire face. Firstly, to better extract the ID information from the face while maintaining certain key facial details, and to better adapt to the structure of Stable Diffusion, FaceChain FACT employs a face feature extractor based on the Transformer architecture, which is pre-trained on a large-scale face dataset. All tokens from the penultimate layer are subsequently fed into a simple attention query model for feature projection, thereby ensuring that the extracted ID features meet the aforementioned requirements. Additionally, during the training process, FaceChain FACT uses the Classifier Free Guidance (CFG) method to perform random shuffle and drop for different portrait images of the same ID, thus ensuring that the input face images and the target images used for denoising may have different faces with the same ID, thus further preventing the model from overfitting to non-ID information of the face. As such, FaceChain FACT possesses high compatibility with the massive exquisite styles of FaceChain, which is shown as follows.

The models used in FaceChain:
[1] Face recognition model TransFace:https://www.modelscope.cn/models/iic/cv_vit_face-recognition
[2] Face detection model DamoFD:https://modelscope.cn/models/damo/cv_ddsar_face-detection_iclr23-damofd
[3] Human parsing model M2FP:https://modelscope.cn/models/damo/cv_resnet101_image-multiple-human-parsing
[4] Skin retouching model ABPN:https://www.modelscope.cn/models/damo/cv_unet_skin_retouching_torch
[5] Face fusion model:https://www.modelscope.cn/models/damo/cv_unet_face_fusion_torch
[6] FaceChain FACT model: https://www.modelscope.cn/models/yucheng1996/FaceChain-FACT
[7] Face attribute recognition model FairFace: https://modelscope.cn/models/damo/cv_resnet34_face-attribute-recognition_fairface
ModelScope Library provides the foundation for building the model-ecosystem of ModelScope, including the interface and implementation to integrate various models into ModelScope.
This project is licensed under the Apache License (Version 2.0).