gavin66/zhihu_crawler 使用知乎移动端 APP 的 API 爬取数据。 目前项目已实现知乎的自动登录,并可爬取用户资料数据(还未有学历等详细资料,之后会添加),需要数据进行分析的或者感兴趣的可以给个 star⭐,谢谢。
你必须安装有 mongoDB
安装依赖
pip install -r requirements.tx爬取用户信息保存进 mongodb 中
python zhihu_crawler/spider/profile.py文件 config.py 进行项目运行配置
# mongodb 连接配置
MONGO_URI = 'mongodb://%s:%s@%s:%s/admin' % ('username', 'password', 'ip', 'port')
# 以下两个文件路径可随意换成你指定的
# token 默认保存地址
TOKEN_PATH = os.environ['HOME'] + '/zhihu_crawler/zhihu.token'
# 日志文件
LOG_PATH = os.environ['HOME'] + '/zhihu_crawler/zhihu.log'from zhihu.client import Client
# 所有程序的入口
client = Client()
# 直接使用用户名和密码登录
client.login(username='+8615555555555', password='password')
# 不使用参数,根据命令行输入
# client.login()
# 自己 model
myself = client.myself()
# 自己的信息
myself.info()
# 他人 model
people = client.people()
# 某人关注列表
people.followees()
# 某人被关注列表
people.followers()
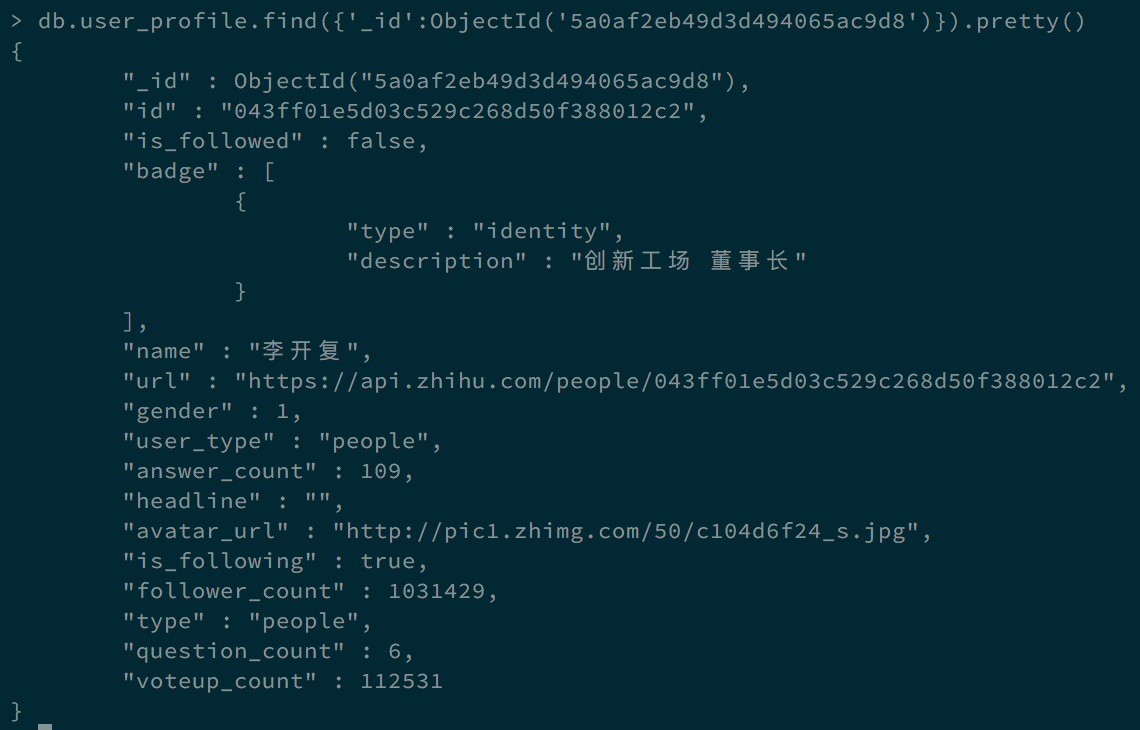
爬取数据的格式
- 登录部分的实现在本人博客有说明 - 爬取知乎数据 - 模拟登录