
Objective high-throughput calssification of leaf disc images form inoculation experiments.
If you use this repository or derivatives of it please cite:
High-throughput phenotyping of leaf discs infected with grapevine downy mildew using shallow convolutional neural networks
Zendler D., Malagol N., Schwandner A., Töpfer, R., Hausmann L., Zyprian E. Agronomy 2021, 11, 1768. https://doi.org/10.3390/agronomy11091768
Original article on bioRxiv: https://doi.org/10.1101/2021.08.19.456931
Leaf disc scoring pipeline by Daniel Zendler is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.

The general pipeline
What it needs
How to install all the dependencies
Running the pipeline
Create custom SCNNs
The SCNNs were trained with images with a resolution of 2752 × 2208 pixels. Using other resolutions than this has not been tested with the supplied model files and therefore no garuntee for success is given when using different resolutions.
The whole pipeline is written in python and R. The two scripts are wrapped in a bash script for consecutive execution. The pipeline can therefore be run on any given UNIX system with all the depencies installed. It was tested and worked on:
- MacOS Mojave, Big Sur
- Ubuntu 18 LTS, 20 LTS.
The leaf disc scoring pipeline first slices the supplied leaf disc image into 506 sub images using image_slicer. The scoring pipeline itself then consists of two trained SCNNs with binary output:
- CNN1: Group slices into background and leaf disc itself
- CNN2: Group classified leaf disc slices into infected and not infected
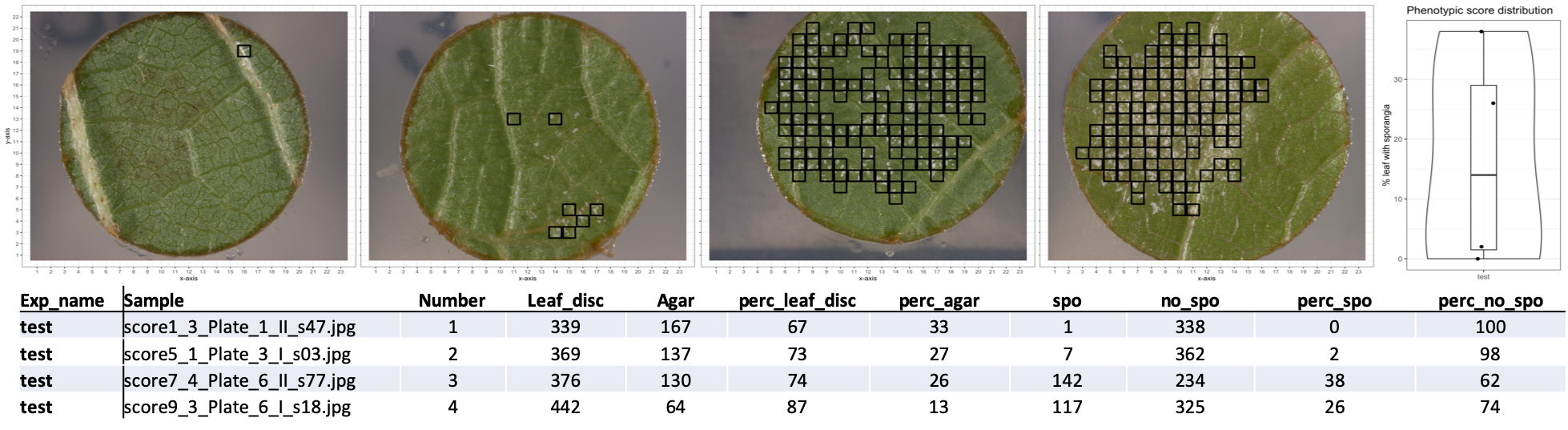
The resulting number of leaf disc slices infected and not infected are expressed as percentage and are included in the final result. The pipeline will iterate over all images in a given folder. The pipeline outputs the raw results as a tab delimited text file that can be further used with R. Further the pipeline produces plots of the original RGB image overlaid with the slcies classified as infected with downy mildew and a boxplot showing the overall phenotypic distribution in the given dataset.

- Python > 3.6
- Tensorflow == 2.4.0
- Keras == 2.4.3
- R > 3.6, Rscript
- ggplot2
- R.utils
- readr
- stringr
- jpeg
- data.table
Quick way of installing all dependencies:
(base)$ git clone https://github.com/Daniel-Ze/Leaf-disc-scoring.git
(base)$ cd Leaf-disc-scoring
# **Optional**: you can checkout the **test branch** of the repository for new plotting features and improved error handling. The **main branch** will not be changed.
(base)~/Leaf-disc-scoring $ git checkout test
# If you checkout the **test branch** follow the **test branch README.md**!
(base)~/Leaf-disc-scoring $ mamba env create --file environment.yml- Make the bash script executable
(base)~/Leaf-disc-scoring/$ chmod a+x run_classification- If you want to have the programm accessible from everywhere (! make sure to adjust the path !)
# MacOS:
$ echo 'export PATH=~/Leaf-disc-scoring:$PATH' >>~/.bash_profile
# Linux
$ echo 'export PATH=~/Leaf-disc-scoring:$PATH' >>~/.bashrc- Restart the terminal and you're all set If you decide to save the repository to another location than your base home folder make sure to adjust the ./bash_profile or ./bashrc entries accordingly.
Recommended installation:
- Clone repository
- Install miniconda3 (https://docs.conda.io/projects/conda/en/latest/user-guide/install/index.html) and install mamba (conda install mamba)
- Make a conda environment called Keras with python 3.6 installed
(base)$ git clone https://github.com/Daniel-Ze/Leaf-disc-scoring.git
(base)$ mamba create -n keras python=3.6
(base)$ conda activate keras
(keras)$ _- Next upgrade pip and setuptools
(keras)$ pip install --upgrade pip setuptools- Install python requirements
(keras)$ cd ~/Leaf-disc-scoring/
(keras)~/Leaf-disc-scoring/$ pip install -r requirements.txt- Install R
(keras)$ mamba install R- Install all libraries for R
(keras)$ R
> install.packages(c("ggplot2","R.utils","readr","stringr","jpeg","data.table"))
> q()
Save workspace image? [y/n/c]: n- Make the bash script executable
(keras)$ cd ~/Leaf-disc-scoring
(keras)~/Leaf-disc-scoring/$ chmod a+x run_classification- If you want to have the programm accessible from everywhere (! make sure to adjust the path !)
# MacOS:
$ echo 'export PATH=~/Leaf-disc-scoring:$PATH' >>~/.bash_profile
# Linux
$ echo 'export PATH=~/Leaf-disc-scoring:$PATH' >>~/.bashrc- Restart the terminal and you're all set If you decide to save the repository to another location than your base home folder make sure to adjust the ./bash_profile or ./bashrc entries accordingly.
To test the install run the pipeline without any arguments:
(keras)$ run_classification
/home/user/miniconda3/etc/profile.d/conda.sh exists.
[info] Running from /home/user/Leaf-disc-scoring/.
[warning] No conda environment name given. Defaulting to: keras
[info] Running Keras in version: 2.4.3
Usage: run_classification -f path/to/leaf/disc/dir/ -e Inoculation1 -l model_l_vs_b.h5 -s model_s_vs_no-s.h5 -k keras
-f Path to leaf disc containing folder. Don't forget the / at the end
-e Give your experiment a name
-l Path to custom Keras model: leaf vs background (if not supplied standard model will be used)
-s Path to custom Keras model: sporangia vs no-sporangia (if notsupplied standard model will be used)
-k name of the conda environment with Leaf-disc-scoring dependencies installed (default: keras)If you intend to use the classification for images of the size 2752 × 2208 pixels and you want to use the pre-trained models for the classification the flags -l and -s can be ignored. The program will then use the models supplied in the programs folder.
To Check if the program runs properly a set of test images is supplied. In total four leaf discs with different degrees of infection severity are supplied.
Running the test:
# 1. Change into the Leaf-disc-scoring repository
(base)$ cd ~/Leaf-disc-scoring
# 2. Run the bash script "run_classification" with the example images
(base)~/Leaf-disc-scoring$ run_classification -f example/ -e my_test -k keras
# 3. Watch the output being created
/Users/daniel/miniconda3/etc/profile.d/conda.sh exists.
[info] Running from /home/user/Leaf-disc-scoring/.
[warning] No conda environment name given. Defaulting to: keras
[info] Running Keras in version: 2.4.3
[info] Leaf disc folder exists.
[info] Experiment name : test_git
[info] No -l option. Using standard model: CNN1_model.h5
[info] No -S option. Using standard model: CNN2_model.h5
[info] Running classify_leaf_disc.py. This might take some time.
[info] # leaf discs: 4
[info] Folder: test/
[info] Model 1: /home/user/Leaf-disc-scoring/CNN1_model.h5
[info] Model 2: /home/user/Leaf-disc-scoring/CNN2_model.h5
[info] Progress: |██████████████████████████████████████████████████| 100.0% Complete
[info] Elapsed time: 2 min
[info] Running plot_coords.R
[info] Plotting score1_3_Plate_1_II_s47.jpg
[info] Plotting score5_1_Plate_3_I_s03.jpg
[info] Plotting score7_4_Plate_6_II_s77.jpg
[info] Plotting score9_3_Plate_6_I_s18.jpg
# 4. Go to the example folder in Leaf-disc-scoring and compare the output to "test_git"Running the program should yield the following results:
- The program generates a plot indicating the leaf disc slices which were classified as infected in a folder called results.
- In the same folder a plot should be present showing the percentage leaf disc covered with sporangiophore distribution of the analyzed leaf disc images.
- The raw results can be found in a tab delimited text file in the main folder called classify_results.txt
"Oh no my images are not in the right resolution" , "My samples are not infected with downy mildew and I don't work with grapevine" or simply "I want to train my own models"
With the main pipeline a folder with additional scripts is supplied. The python scripts should help you to set your stuff up with another pathogen or if you just want to train your models on image data from yoour experiments. So please go to scripts and read the README.