Reinforcement Learning Agents
Implemented for Tensorflow 2.0+
- DDPG with prioritized replay
- Primal-Dual DDPG for CMDP
- Install dependancies imported (my tf2 conda env as reference)
- Each file contains example code that runs training on CartPole env
- Training:
python3 TF2_DDPG_LSTM.py
- Tensorboard:
tensorboard --logdir=DDPG/logs
Agents tested using CartPole env.
| Name |
On/off policy |
Model |
Action space support |
| DQN |
off-policy |
Dense, LSTM |
discrete |
| DDPG |
off-policy |
Dense, LSTM |
discrete, continuous |
| AE-DDPG |
off-policy |
Dense |
discrete, continuous |
| SAC:bug: |
off-policy |
Dense |
continuous |
| PPO |
on-policy |
Dense |
discrete, continuous |
| Name |
On/off policy |
Model |
Action space support |
| Primal-Dual DDPG |
off-policy |
Dense |
discrete, continuous |
Models used to generate the demos are included in the repo, you can also find q value, reward and/or loss graphs
| DQN Basic, time step = 4, 500 reward |
DQN LSTM, time step = 4, 500 reward |
 |
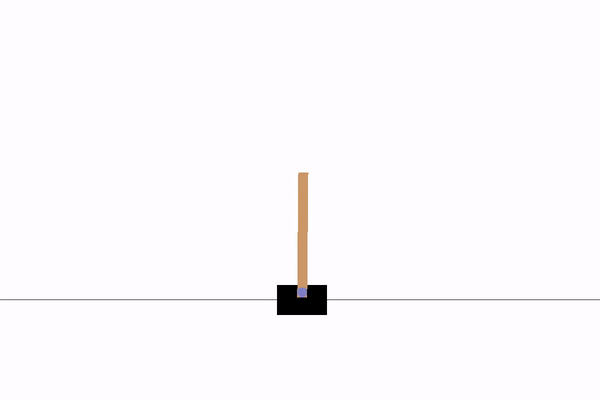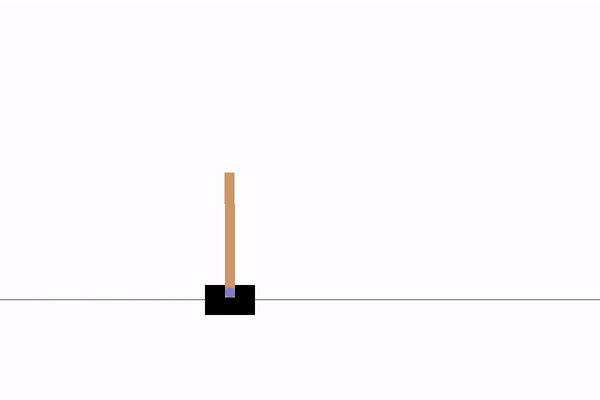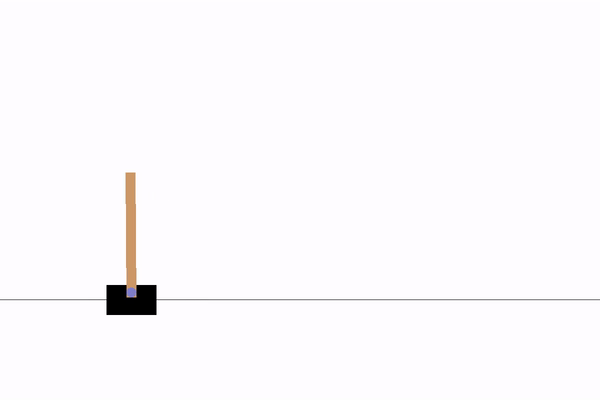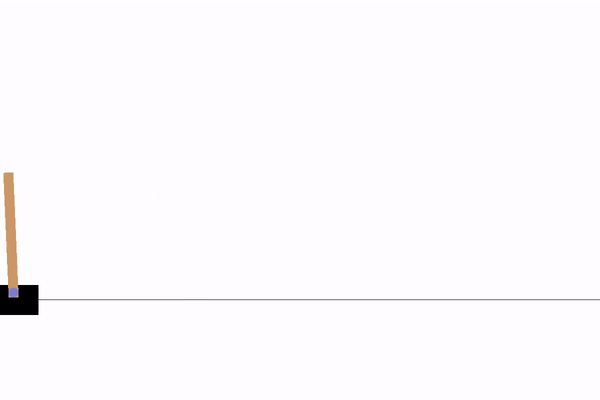 |
| DDPG Basic, 500 reward |
DDPG LSTM, time step = 5, 500 reward |
 |
 |
| AE-DDPG Basic, 500 reward |
PPO Basic, 500 reward |
 |
 |





