Fenix's BookStore后端:以Kubernetes微服务实现
![]()





如果你此时并不曾了解过什么是“The Fenix Project”,建议先阅读这部分内容。
2017年,笔者曾在文章中描述其为“后微服务时代”的开端,这年是容器生态发展历史中具有里程碑意义的一年。在这一年,长期作为Docker竞争对手的RKT容器一派的领导者CoreOS宣布放弃自己的容器管理系统Fleet,未来将会把所有容器管理的功能移至Kubernetes之上去实现。在这一年,容器管理领域的独角兽Rancher Labs宣布放弃其内置了数年的容器管理系统Cattle,提出了“All-in-Kubernetes”战略,从2.0版本开始把1.x版本能够支持多种容器管理工具的Rancher,“反向升级”为只支持Kubernetes一种容器管理系统。在这一年,Kubernetes的主要竞争者Apache Mesos在9月正式宣布了“Kubernetes on Mesos”集成计划,由竞争关系转为对Kubernetes提供支持,使其能够与Mesos的其他一级框架(如HDFS、Spark 和Chronos,等等)进行集群资源动态共享、分配与隔离。在这一年,Kubernetes的最大竞争者Docker Swarm的母公司Docker,终于在10月被迫宣布Docker要同时支持Swarm与Kubernetes两套容器管理系统,事实上承认了Kubernetes的**地位。这场已经持续了三、四年时间,以Docker Swarm、Apache Mesos与Kubernetes为主要竞争者的“容器战争”终于有了明确的结果,Kubernetes登基加冕是容器发展中一个时代的终章,也将是软件架构发展下一个纪元的开端。
需求场景
当引入了基于Spring Cloud的微服务架构后,小书店Fenix's Bookstore初步解决了扩容缩容、独立部署、运维和管理等问题,满足了产品经理不断提出的日益复杂的业务需求。可是,对于团队的开发人员、设计人员、架构人员来说,并没有感觉到工作变得轻松,微服务中的各种新技术名词,如配置中心、服务发现、网关、熔断、负载均衡等等,就够一名新手学习好长一段时间;从产品角度来看,各种Spring Cloud的技术套件,如Config、Eureka、Zuul、Hystrix、Ribbon、Feign等,也占据了产品的大部分编译后的代码容量。之所以微服务架构里,我们选择在应用层面而不是基础设施层面去解决这些分布式问题,完全是因为由硬件构成的基础设施,跟不上由软件构成的应用服务的灵活性的无奈之举。当Kubernetes统一了容器编排管理系统之后,这些纯技术性的底层问题,便开始有了被广泛认可和采纳的基础设施层面的解决方案。为此,Fenix's Bookstore也迎来了它在“后微服务时代”中的下一次架构演进,这次升级的目标主要有如下两点:
- 目标一:尽可能缩减非业务功能代码的比例。
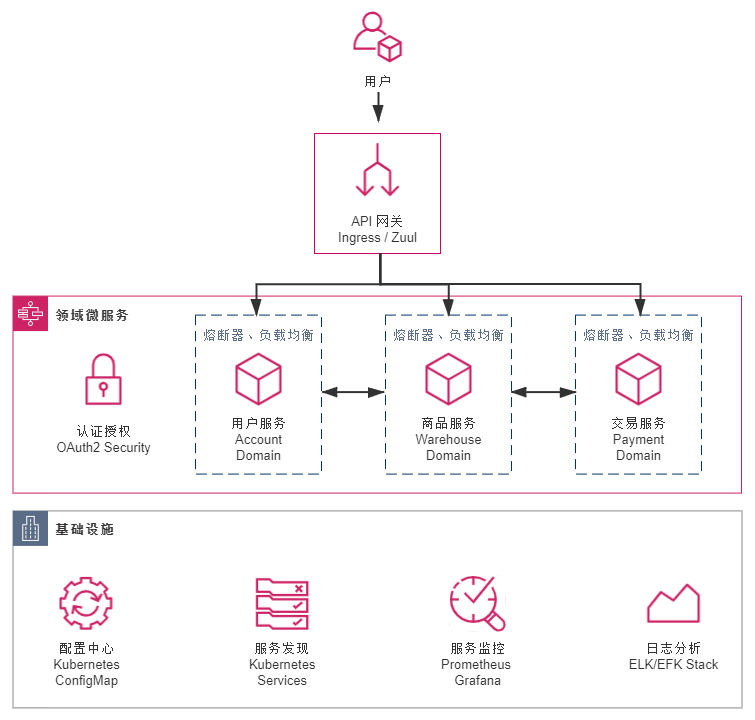
在Fenix's Bookstore中,用户服务(Account)、商品服务(Warehouse)、交易服务(Payment)三个工程是真正承载业务逻辑的,认证授权服务(Security)可以认为是同时涉及到了技术与业务,而配置中心(Configuration)、网关(Gateway)和服务注册中心(Registry)则是纯技术性。我们希望尽量消除这些纯技术的工程,以及那些依附在其他业务工程上的纯技术组件。 - 目标二:尽可能在不影响原有的代码的前提下完成迁移。
得益于Spring Framework 4中的Conditional Bean等声明式特性的出现,对于近年来新发布的Java技术组件,声明式编程(Declarative Programming)已经逐步取代命令式编程(Imperative Programming)成为主流的选择。在声明式编程的支持下,我们可以从目的而不是过程的角度去描述编码意图,使得代码几乎不会与具体技术实现产生耦合,若要更换一种技术实现,只需要调整配置中的声明便可做到。
从升级结果来看,如果仅以Java代码的角度来衡量,本工程与此前基于Spring Cloud的实现没有丝毫差异,两者的每一行Java代码都是一模一样的;真正的区别在Kubernetes的实现版本中直接删除了配置中心、服务注册中心的工程,在其他工程的pom.xml中也删除了如Eureka、Ribbon、Config等组件的依赖。取而代之的是新增了若干以YAML配置文件为载体的Skaffold和Kubernetes的资源描述,这些资源描述文件,将会动态构建出DNS服务器、服务负载均衡器等一系列虚拟化的基础设施,去代替原有的应用层面的技术组件。升级改造之后的应用架构如下图所示:
运行程序
在已经部署Kubernetes集群的前提下,通过以下几种途径,可以运行程序,浏览最终的效果:
-
直接在Kubernetes集群环境上运行:
工程在编译时已通过Kustomize产生出集成式的资源描述文件,可通过该文件直接在Kubernetes集群中运行程序:# 资源描述文件 $ kubectl apply -f https://raw.githubusercontent.com/fenixsoft/microservice_arch_kubernetes/master/bookstore.yml命令执行过程一共需要下载几百MB的镜像,尤其是Docker中没有各层基础镜像缓存时,请根据自己的网速保持一定的耐心。未来GraalVM对Spring Cloud的支持更成熟一些后,可以考虑采用GraalVM来改善这一点。当所有的Pod都处于正常工作状态后,在浏览器访问:http://localhost:30080,系统预置了一个用户(
user:icyfenix,pw:123456),也可以注册新用户来测试。 -
通过Skaffold在命令行或IDE中以调试方式运行:
一般开发基于Kubernetes的微服务应用,是在本地针对单个服务编码、调试完成后,通过CI/CD流水线部署到Kubernetes中进行集成的。如果只是针对集成测试,这并没有什么问题,但同样的做法应用在开发阶段就相当不便了,我们不希望每做一处修改都要经过一次CI/CD流程,这将非常耗时且难以调试。
Skaffold是Google在2018年开源的一款加速应用在本地或远程Kubernetes集群中构建、推送、部署和调试的自动化命令行工具,对于Java应用来说,它可以帮助我们做到监视代码变动,自动打包出镜像,将镜像打上动态标签并更新部署到Kubernetes集群,为Java程序注入开放JDWP调试的参数,并根据Kubernetes的服务端口自动在本地生成端口转发。以上都是根据skaffold.yml中的配置来进行的,开发时skaffold通过dev指令来执行这些配置,具体的操作过程如下所示:# 克隆获取源码 $ git clone https://github.com/fenixsoft/microservice_arch_kubernetes.git && cd microservice_arch_kubernetes # 编译打包 $ ./mvnw package # 启动Skaffold # 此时将会自动打包Docker镜像,并部署到Kubernetes中 $ skaffold dev
服务全部启动后,在浏览器访问:http://localhost:30080,系统预置了一个用户(
user:icyfenix,pw:123456),也可以注册新用户来测试由于面向的是开发环境,基于效率原因,笔者并没有像传统CI工程那样直接使用Maven的Docker镜像来打包Java源码,这决定了构建Dockerfile时,要监视的变动目标将是Jar文件而不是Java源码,Skaffold的执行是由Jar包的编译结果来驱动的,只在进行Maven编译、输出了新的Jar包后才会更新镜像。这样做一方面是考虑到在Maven镜像中打包不便于利用本地的仓库缓存,尤其在国内网络中,速度实在难以忍受;另外一方面,是笔者其实并不希望每保存一次源码时,都自动构建和更新一次镜像,毕竟比起传统的HotSwap或者Spring Devtool Reload来说,更新镜像重启Pod是一个更加重负载的操作。未来CNCF的Buildpack成熟之后,应该可以绕过笨重的Dockerfile,对打包和容器热更新做更加精细化的控制。
另外,对于有IDE调试需求的同学,推荐采用Google Cloud Code(Cloud Code同时提供了VS Code和IntelliJ Idea的插件)来配合Skaffold使用,毕竟是同一个公司出品的产品,搭配起来能获得几乎与本地开发单体应用一致的编码和调试体验。
技术组件
Fenix's Bookstore采用基于Kubernetes的微服务架构,并采用Spring Cloud Kubernetes做了适配,其中主要的技术组件包括:
- 环境感知:Spring Cloud Kubernetes本身引入了Fabric8的Kubernetes Client作为容器环境感知,不过引用的版本相当陈旧,如Spring Cloud Kubernetes 1.1.2中采用的是Fabric8 Kubernetes Client 4.4.1,Fabric8提供的兼容性列表中该版本只支持到Kubernetes 1.14,实测在1.16上也能用,但是在1.18上无法识别到最新的Api-Server,因此Maven引入依赖时需要手工处理,排除旧版本,引入新版本(本工程采用的是4.10.1)。
- 配置中心:采用Kubernetes的ConfigMap来管理,通过Spring Cloud Kubernetes Config自动将ConfigMap的内容注入到Spring配置文件中,并实现动态更新。
- 服务发现:采用Kubernetes的Service来管理,通过Spring Cloud Kubernetes Discovery自动将HTTP访问中的服务转换为FQDN。
- 负载均衡:采用Kubernetes Service本身的负载均衡能力实现(就是DNS负载均衡),可以不再需要Ribbon这样的客户端负载均衡了。Spring Cloud Kubernetes从1.1.2开始也已经移除了对Ribbon的适配支持,也(暂时)没有对其代替品Spring Cloud LoadBalancer提供适配。
- 服务网关:网关部分仍然保留了Zuul,未采用Ingress代替。这里有两点考虑,一是Ingress Controller不算是Kubernetes的自带组件,它可以有不同的选择(KONG、Nginx、Haproxy,等等),同时也需要独立安装,作为演示工程,出于环境复杂度最小化考虑未使用Ingress;二是Fenix's Bookstore的前端工程是存放在网关中的,移除了Zuul之后也仍然要维持一个前端工程的存在,不能进一步缩减工程数量,也就削弱了移除Zuul的动力。
- 服务熔断:仍然采用Hystrix,Kubernetes本身无法做到精细化的服务治理,包括熔断、流控、监视,等等,我们将在基于Istio的服务网格架构中解决这个问题。
- 认证授权:仍然采用Spring Security OAuth 2,Kubernetes的RBAC授权可以解决服务层面的访问控制问题,但Security是跨越了业务和技术的边界的,认证授权模块本身仍承担着对前端用户的认证、授权职责,这部分是与业务相关的。
协议
-
本文档代码部分采用Apache 2.0协议进行许可。遵循许可的前提下,你可以自由地对代码进行修改,再发布,可以将代码用作商业用途。但要求你:
- 署名:在原有代码和衍生代码中,保留原作者署名及代码来源信息。
- 保留许可证:在原有代码和衍生代码中,保留Apache 2.0协议文件。
-
本作品文档部分采用知识共享署名 4.0 国际许可协议进行许可。 遵循许可的前提下,你可以自由地共享,包括在任何媒介上以任何形式复制、发行本作品,亦可以自由地演绎、修改、转换或以本作品为基础进行二次创作。但要求你:
- 署名:应在使用本文档的全部或部分内容时候,注明原作者及来源信息。
- 非商业性使用:不得用于商业出版或其他任何带有商业性质的行为。如需商业使用,请联系作者。
- 相同方式共享的条件:在本文档基础上演绎、修改的作品,应当继续以知识共享署名 4.0国际许可协议进行许可。