Image segmentation is a technique to label each individual pixel in an image (or pic sections with geometry) using a deep neural network (DNN).
Segmentation techniques can be of use in object extraction from images in real life applications.
I.e. a DNN running on a car software using cameras can extract people, roads, road signs, bikes, etc. and later use that info for orientation.
An example segmentation image:
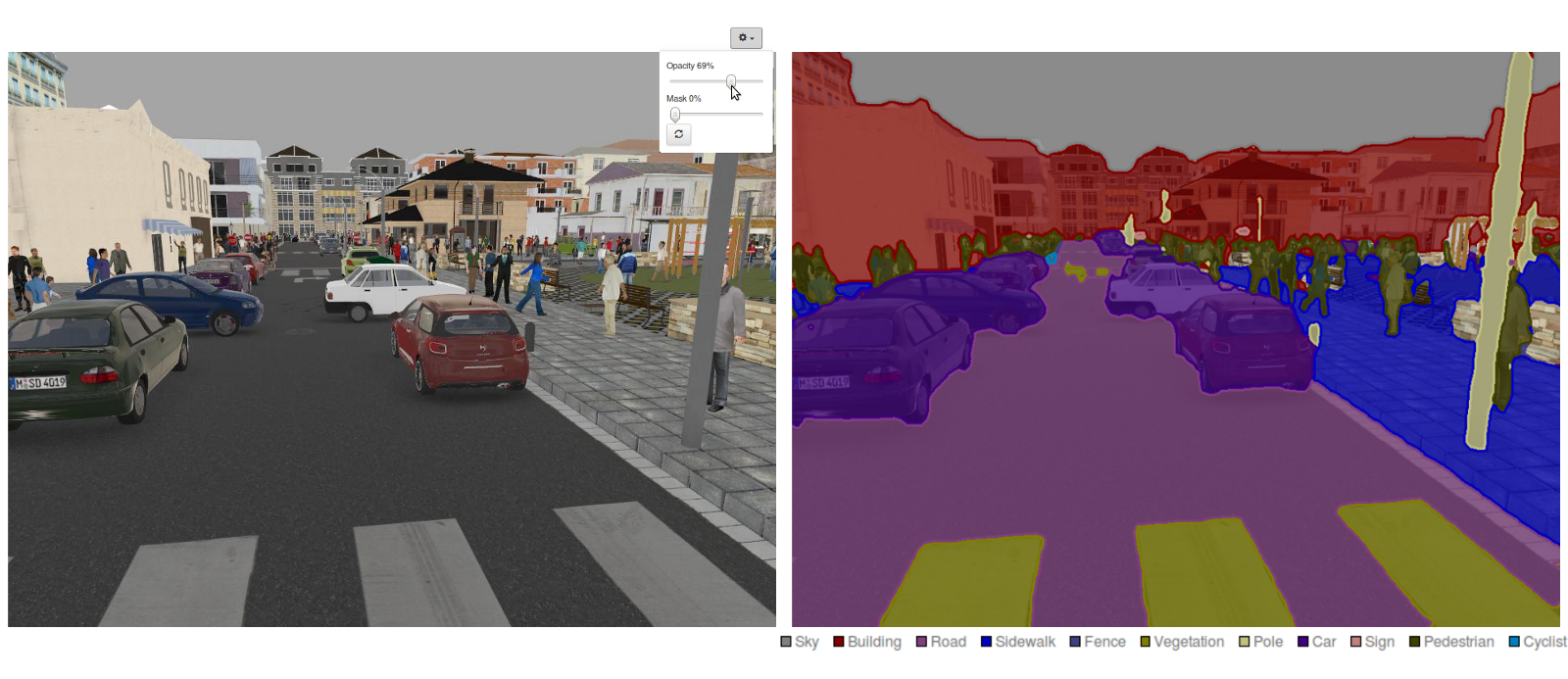
As in most cases the labeling must be done by a dedicated group of people. Needless to say, that labeling each pixel in a picture (essentially drawing over) is a hard and mind-numbing grunt work. But hey, what all those art degrees are doing anyways?? Jk, of course. But seriously, to mitigate the whole lot of boring work, we should try to automate it somehow. Why not to use a free game engine to build an environment, generate loads of precisely labeled data and try to train a network on that. Afterwards, if the virtual environment is realistic looking enough, we could try transfer learning to pip up the model on real photos, or even use it right away.
I mean, some video games nowadays look quite realistic, proving the capabilities of building capable environments:

I am by no means first to claim to propose this technique. I.e. my assumption is that Tesla must have done something similar to kickstart it's own networks in virtual environment. It just happened that I was learning DNNs and wanted to make something, while also using my other skills (Unity, in this case).
This project is an attempt to automate segmentation image labeling, by generating ready-made label-picture pairs automatically. It is thus made of three parts:
- Virtual environment setup and generator in Unity game engine;
- A prototype Jupyter notebook to train on the generated data;
- Fastapi server to serve the model and feed that data back to Unity and visualize predictions (almost) realtime.
- not a commercial product/tool. Use it at your own discretion.
- not a cure for all. Your project might require different approach. Please do not spam feature requests.
- Download UnityHub and install an appropriate version. Should work on 2021.1.5 or later. Will update this when we get a 2021 LTS release.
- Install python if your system does not have it. Python version used to develop this was 3.8.1
- Git pull this repo. Add it your Unity projects.
- Install python dependencies using requirements.txt file form this repo.
Within Unity you will find a scene. Load it if you have not yet done it. The scene will contain an example level ready to be used. If you hit "play" button in the editor, the level should load and setup the environment for you.
Then just input how many pictures you want to generate (i.e. 500) and click "Generate" button. You will find your dataset in /Assets/Data~ folder.
For more details about Unity part of this project see Unity Readme.
Run Jupyter server. If you do not know how to do it or even what it is, I recommend watching a few tutorials online, there's loads of them. Just google "Jupyter Notebooks".
The notebook itself is with quite detailed descriptions. It is a fastai based prototype by loading a unet resnet34 model (a convolutional neural network, or CNN in short).

For more details about training see Train Readme.
First start the fastapi server. Then in Unity Play mode move the camera around and enable "inference" mode to communicate to API by pressing "Space". See the overlayed results :)
** insert a screenshot of overlayed in unity **
- Move the camera using "W-A-S-D" keys. Aim with mouse.
- The API simply returns labels and overlays them via a shader. With buttons F1-F4 you can isolate label groups to see only a single group one at a time, i.e. furniture, building, animals.
- With "+" and "-" keys (num-pad) you can regulate label overlay opacity. Use it if you cannot see objects well enough.
- "Q" key to show/hide background, leaving only label layer.
- "E" to force show labels, or to clear them (if they are being shown). This works also in non-inference mode (as a single web request), but will return nothing if there are no models saved/running.
For more details about server and inference in general see Inference Readme.
If you are interested in the roadmap of this project, I wrote a short story discussing the problems encountered and summarizing possibilities. See Discussion Readme. You will find these chapters there:
- Roadmap story
- Usability discussion
- Ideas for improvements
- Summary
- Make a YT video walk-through.
- Dovydas Ceilutka for taking up the initiative to create a local AI learning community and mentoring this project.
- Jeremy Howard for great video material and library (with Rachel Thomas).
- Stasys Vysniauskas for the setup of the test level in Unity.
Licenced under the MIT Licence. Take it and use however you like :) Would be nice if you share the results, but it's not required.