pdfdir —— PDF 导航书签添加工具

根据已有的目录文本为你的 PDF 自动生成导航书签。
此项目实现逻辑深受 https://github.com/ifnoelse/pdf-bookmark 项目影响。
自己画的软件界面太不友好,期待有懂设计的大佬帮忙设计界面,有意可直接联系 chroming@live.com , 不胜感激。
软件功能
根据网上或 PDF 中已有的目录内容自动将导航书签插入 PDF 文件中。
适用于以下场景:
- 扫描版电子书籍无导航书签;
- 文字版电子文档无导航书签但 PDF 中有目录。
下载
Windows/macOS/Ubuntu:
其他平台:
请使用源码方式运行或自行打包。
基本用法
使用
-
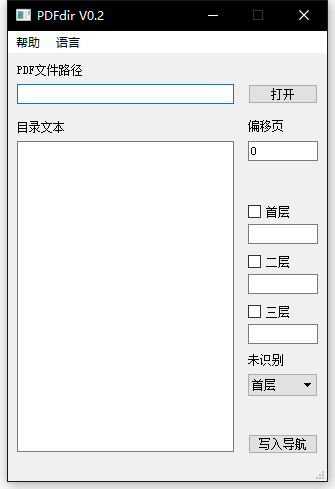
选择文件(必填):在 "PDF 文件路径" 文本框中填入 pdf 文件路径(如 D:/统计思维.pdf)或点击 "打开" 按钮通过文件管理器选择所需的 pdf 文件。
-
目录文本(必填):将目录文本粘贴到“目录文本”框中。如何获取目录文本。
-
偏移页(默认 0):指实际页数与文档内容下标页码的差值,如:第一章实际在 pdf 的第 5 页,但此页的下标页码为第 1 页,则偏移页为 4 。
-
子目录区域(非必填区域):
若此区域留空则所有目录均作为首层写入。
- 首层:用于匹配最外层目录标题的正则表达式,勾选启用。点击"..."可插入常用正则。
- 二层:用于匹配首层子目录标题的正则表达式。
- 三层:用于匹配二层子目录标题的正则表达式。
- 未识别:前三层表达式都未匹配到的标题当作第几层。默认当作首层。
-
写入导航:前三个均填好之后就可以点击 "写入导航" 自动将目录写入 pdf 的新拷贝中,拷贝文件自动命名为 "原文件名_new.pdf"。
获取目录文本
目录文本是类似以下形式的文本内容:
中译版序言
致**读者
作者来信
前言
第1章社会心理学导论2
第一编社会思维
第2章社会中的自我32
.....................
结语605
参考文献606
即:标题+页数形式。文本内容一般来源于网上书店(如亚马逊)或图书介绍网站(如豆瓣读书)。图书的介绍中一般会列出该书的目录文本,如亚马逊的在 商品描述--目录 下。注意:自动生成的目录完全依赖于目录文本,如果此文本有问题则生成的目录也会有问题。
英文支持
下载源码中的 language/en.qm 放到程序同目录下 language/en.qm , 之后点击程序菜单栏中的 "语言 -- English" 即可切换为英文界面。
已知问题
- 一般图书非正文部分(如序言,目录等)没有标页码或使用另一套页码标记,本程序将这些目录默认链接到第一页,如需修正这些链接可手动修改。
- 有些正文中的目录没有标页码,程序会将该条目录链接到上一个有页码的标题页。
TODO
- 增加预览导航的界面,界面中可直接拖动来修改层级
其他
通过源码运行
暂时无法使用此方式正常运行。
运行源码所需环境:
- Python2/3 均可,推荐 Python3
- PyQt5
- PyPDF2
- six
注意:Python2 与 Python3 不兼容,某些系统(如 macOS)系统自带 Python2,使用python命令调用,若自行安装 Python3 则可能需要通过python3来调用 Python3,pip 同理。本文不区分 python/python3, pip/pip3,请用户按当前系统所安装版本使用对应命令。
获取代码
git clone https://github.com/chroming/pdfdir
安装运行环境
安装 Python:
https://www.python.org/downloads/
安装依赖包:
进入项目目录,执行:
pip install -r requirements.txt
pip install -r PyQt5
若提示No matching distribution found for pyqt5 可参照PyQt 官方文档进行安装。
环境装好之后进入源码目录,运行以下命令:
python run_gui.py
如果不需要 GUI 界面:
python run.py
打包源码
如果你想在本机打包此程序:
安装 Pyinstaller
pip install pyinstaller
打包程序
pyinstaller.py -F run_gui.py -n "PDFdir.exe" --noconsole
目录文本格式
目前通过以下格式处理目录文本:
标题+页数+换行符
所有在一行的都被认为是一条目录。页数通过正则(\d*$)匹配(匹配文本结尾处的所有数字),如果匹配不到则默认为第一页或上一条目录的页数。
正则表达式简要说明
正则表达式是编程中常用的一种工具。如果你没有使用过,可以把他当成类似于 office 中通配符的东西。 本工具中可能会用到的正则:
- \d 表示单个数字,如 "第\d 章" 可以匹配 "第 1 章", "第 2 章"……等,但不能匹配"第 10 章", 因为 10 是两个数字;
- \w 表示单个字符,包括单个数字。如 "第\w 章" 可以匹配"第 1 章", "第一章"……等;
- . 表示任意字符,包括\w 所能匹配的所有字符以及空格等特殊字符;
- * 表示表达式中的前一个符号可以匹配不到,或匹配任意多次,如 "第\d*章" 可以匹配 "第章", "第 1 章", "第 100 章";
- + 跟*类似,但是前一个符号不能匹配不到;
- {m, n} 匹配前一个字符 m 至 n 次。
注意:
- *, + 符号会匹配尽可能多的内容,比如如果用"第\w*章" 来匹配,"第一节如何阅读此章"这段内容也会被匹配到,更好的写法是确定要匹配内容的长度,写成"第\w{1,2}章"。
- 要匹配一个不是正则表达式中的正常字符直接写即可,如"第", "1", 甚至包括空格。但正则表达式中有定义用于匹配的一些特殊字符如果要作为普通字符匹配,则要在前面加一个"\",比如匹配"1.1"这种格式,可以写成"\d\.\d"。"\"符号本身也要如此。