English | 简体中文








![]()
AutoDL Challenge@NeurIPS 冠军方案,竞赛细节参见 AutoDL Competition。
AutoDL聚焦于自动进行任意模态(图像、视频、语音、文本、表格数据)多标签分类的通用算法,可以用一套标准算法流解决现实世界的复杂分类问题,解决调数据、特征、模型、超参等烦恼,最短10秒就可以做出性能优异的分类器。本工程在不同领域的24个离线数据集、15个线上数据集都获得了极为优异的成绩。AutoDL拥有以下特性:
☕ 全自动:全自动深度学习/机器学习框架,全流程无需人工干预。数据、特征、模型的所有细节都已调节至最佳,统一解决了资源受限、数据倾斜、小数据、特征工程、模型选型、网络结构优化、超参搜索等问题。只需要准备数据,开始AutoDL,然后喝一杯咖啡。
🌌 通用性:支持任意模态,包括图像、视频、音频、文本和结构化表格数据,支持任意多标签分类问题,包括二分类、多分类、多标签分类。它在不同领域都获得了极其优异的成绩,如行人识别、行人动作识别、人脸识别、声纹识别、音乐分类、口音分类、语言分类、情感分类、邮件分类、新闻分类、广告优化、推荐系统、搜索引擎、精准营销等等。
👍 效果出色:AutoDL竞赛获得压倒性优势的冠军方案,包含对传统机器学习模型和最新深度学习模型支持。模型库包括从LR/SVM/LGB/CGB/XGB到ResNet*/MC3/DNN/ThinResnet*/TextCNN/RCNN/GRU/BERT等优选出的冠军模型。
⚡ 极速/实时:最快只需十秒即可获得极具竞争力的模型性能。结果实时刷新(秒级),无需等待即可获得模型实时效果反馈。
-
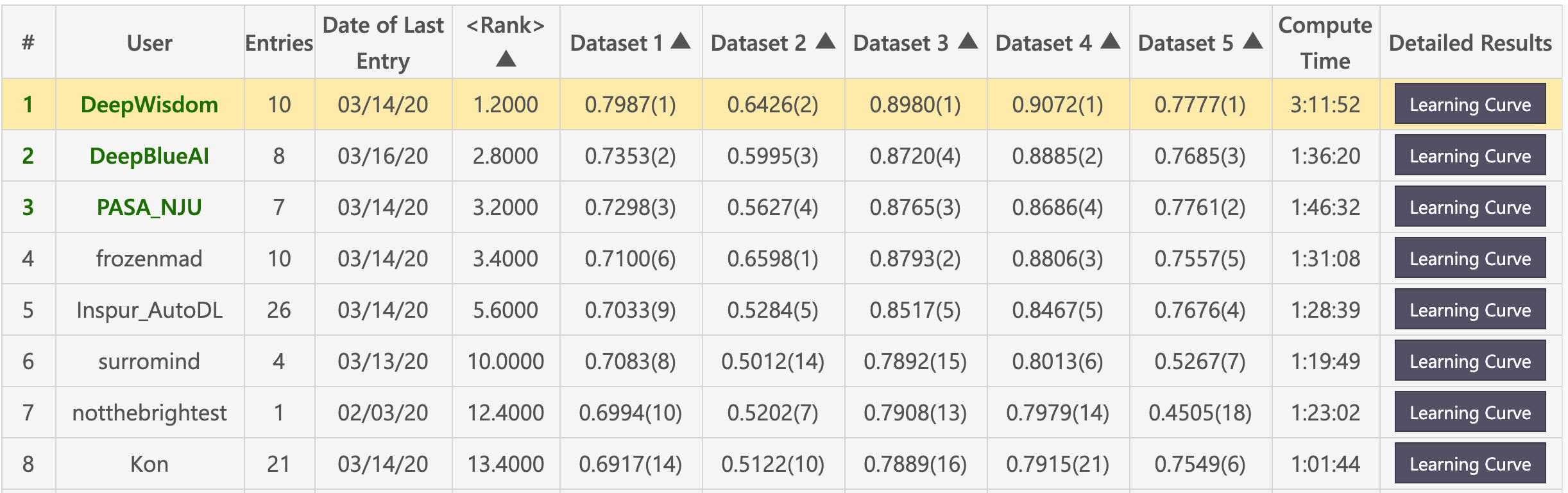
预赛榜单(DeepWisdom总分第一,平均排名1.2,在5个数据集中取得了4项第一)
-
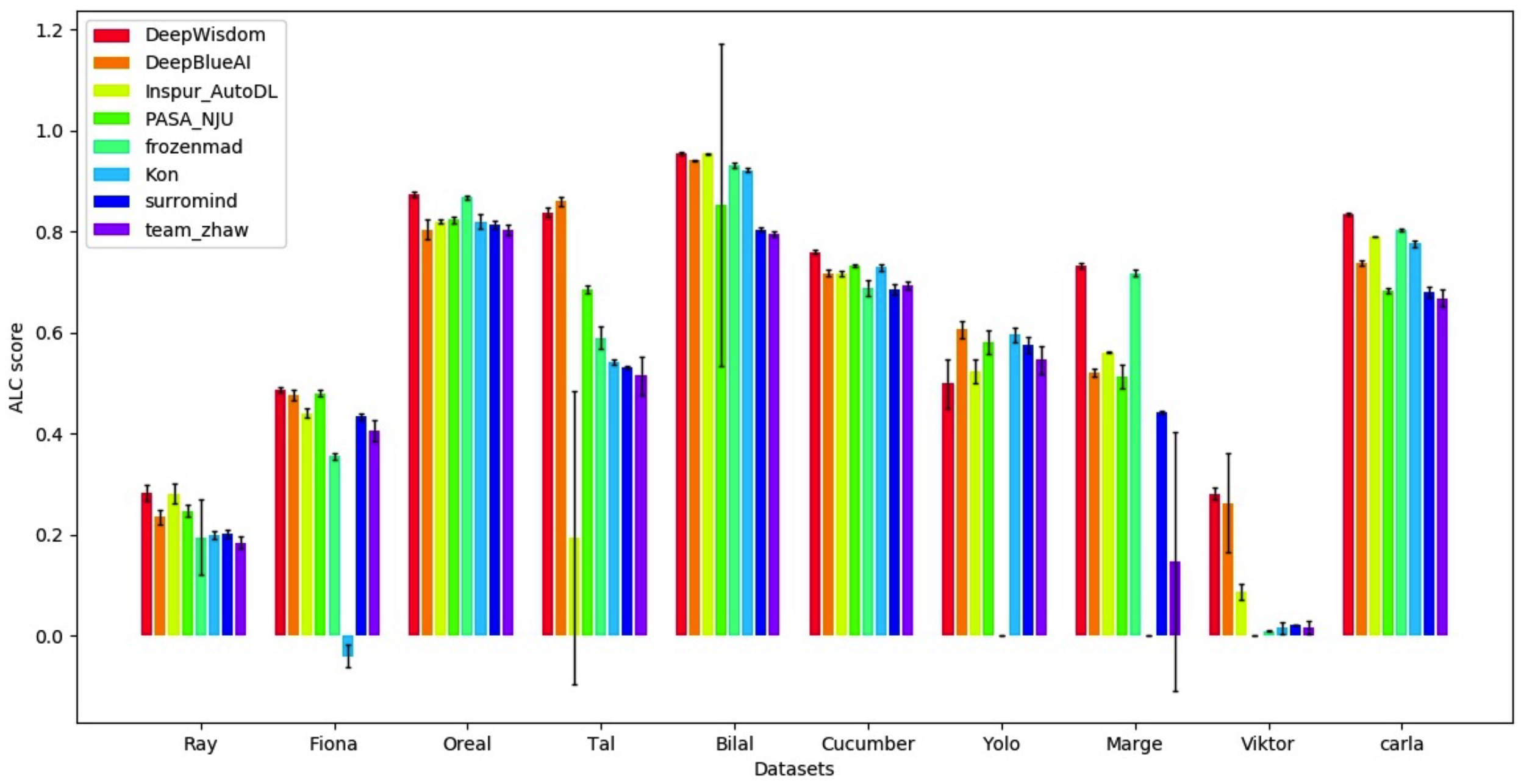
决赛榜单(DeepWisdom总分第一,平均排名1.8,在10个数据集中取得了7项第一)


-
基础环境
python>=3.5 CUDA 10 cuDNN 7.5 -
clone仓库
cd <path_to_your_directory> git clone https://github.com/DeepWisdom/AutoDL.git -
预训练模型准备 下载模型 speech_model.h5 放至
AutoDL_sample_code_submission/at_speech/pretrained_models/目录。 -
可选:使用与竞赛同步的docker环境
- CPU
cd path/to/autodl/ docker run -it -v "$(pwd):/app/codalab" -p 8888:8888 evariste/autodl:cpu-latest- GPU
nvidia-docker run -it -v "$(pwd):/app/codalab" -p 8888:8888 evariste/autodl:gpu-latest -
数据集准备:使用
AutoDL_sample_data中样例数据集,或批量下载竞赛公开数据集。 -
进行本地测试
python run_local_test.py
本地测试完整使用。
python run_local_test.py -dataset_dir='AutoDL_sample_data/miniciao' -code_dir='AutoDL_sample_code_submission'
您可在 AutoDL_scoring_output/ 目录中查看实时学习曲线反馈的HTML页面。
细节可参考 AutoDL Challenge official starting_kit.

可以看出,在五个不同模态的数据集下,AutoDL算法流都获得了极为出色的全时期效果,可以在极短的时间内达到极高的精度。
本仓库在 Python 3.6+, PyTorch 1.3.1 和 TensorFlow 1.15上测试.
你应该在虚拟环境 中安装autodl。 如果对虚拟环境不熟悉,请看 用户指导.
用合适的Python版本创建虚拟环境,然后激活它。
- CUDA 10.0下载
- cuDNN下载
- 百度云 提取码:xb9x
- Miniconda3-4.5.4-Windows-x86_64.exe
- 百度云 提取码:xb9x
- visualcppbuildtools_full.exe
- 百度云 提取码:xb9x
- 将其移动到安装的
Miniconda3同级目录下
cmd.exe "/K" .\Miniconda3\Scripts\activate.bat .\Miniconda3conda install pytorch==1.3.1
conda install torchvision -c pytorch
pip install autodl-gpupip install autodl-gpu指导参见 快速上手之AutoDL本地效果测试,样例代码参见 examples/run_local_test.py
参见 快速上手之图像分类,样例代码参见 examples/run_image_classification_example.py
指导参见 快速上手之视频分类,样例代码参见examples/run_video_classification_example.py
指导参见 快速上手之音频分类,样例代码参见examples/run_speech_classification_example.py
指导参见 快速上手之文本分类,样例代码参见examples/run_text_classification_example.py。
指导参见 快速上手之表格分类,样例代码参见examples/run_tabular_classification_example.py.
python download_public_datasets.py| # | Name | Type | Domain | Size | Source | Data (w/o test labels) | Test labels |
|---|---|---|---|---|---|---|---|
| 1 | Munster | Image | HWR | 18 MB | MNIST | munster.data | munster.solution |
| 2 | City | Image | Objects | 128 MB | Cifar-10 | city.data | city.solution |
| 3 | Chucky | Image | Objects | 128 MB | Cifar-100 | chucky.data | chucky.solution |
| 4 | Pedro | Image | People | 377 MB | PA-100K | pedro.data | pedro.solution |
| 5 | Decal | Image | Aerial | 73 MB | NWPU VHR-10 | decal.data | decal.solution |
| 6 | Hammer | Image | Medical | 111 MB | Ham10000 | hammer.data | hammer.solution |
| 7 | Kreatur | Video | Action | 469 MB | KTH | kreatur.data | kreatur.solution |
| 8 | Kreatur3 | Video | Action | 588 MB | KTH | kreatur3.data | kreatur3.solution |
| 9 | Kraut | Video | Action | 1.9 GB | KTH | kraut.data | kraut.solution |
| 10 | Katze | Video | Action | 1.9 GB | KTH | katze.data | katze.solution |
| 11 | data01 | Speech | Speaker | 1.8 GB | -- | data01.data | data01.solution |
| 12 | data02 | Speech | Emotion | 53 MB | -- | data02.data | data02.solution |
| 13 | data03 | Speech | Accent | 1.8 GB | -- | data03.data | data03.solution |
| 14 | data04 | Speech | Genre | 469 MB | -- | data04.data | data04.solution |
| 15 | data05 | Speech | Language | 208 MB | -- | data05.data | data05.solution |
| 16 | O1 | Text | Comments | 828 KB | -- | O1.data | O1.solution |
| 17 | O2 | Text | Emotion | 25 MB | -- | O2.data | O2.solution |
| 18 | O3 | Text | News | 88 MB | -- | O3.data | O3.solution |
| 19 | O4 | Text | Spam | 87 MB | -- | O4.data | O4.solution |
| 20 | O5 | Text | News | 14 MB | -- | O5.data | O5.solution |
| 21 | Adult | Tabular | Census | 2 MB | Adult | adult.data | adult.solution |
| 22 | Dilbert | Tabular | -- | 162 MB | -- | dilbert.data | dilbert.solution |
| 23 | Digits | Tabular | HWR | 137 MB | MNIST | digits.data | digits.solution |
| 24 | Madeline | Tabular | -- | 2.6 MB | -- | madeline.data | madeline.solution |
❤️ 请毫不犹豫参加贡献 Open an issue 或提交 PRs。
