
You can also find all 39 answers here 👉 Devinterview.io - Hash Table Data Structure
A Hash Table, also known as a Hash Map, is a data structure that provides a mechanism to store and retrieve data based on key-value pairs.
It is an associative array abstract data type where the key is hashed, and the resulting hash value is used as an index to locate the corresponding value in a bucket or slot.
- Unique Keys: Each key in the hash table maps to a single value.
- Dynamic Sizing: Can adjust its size based on the number of elements.
-
Fast Operations: Average time complexity for most operations is
$O(1)$ .
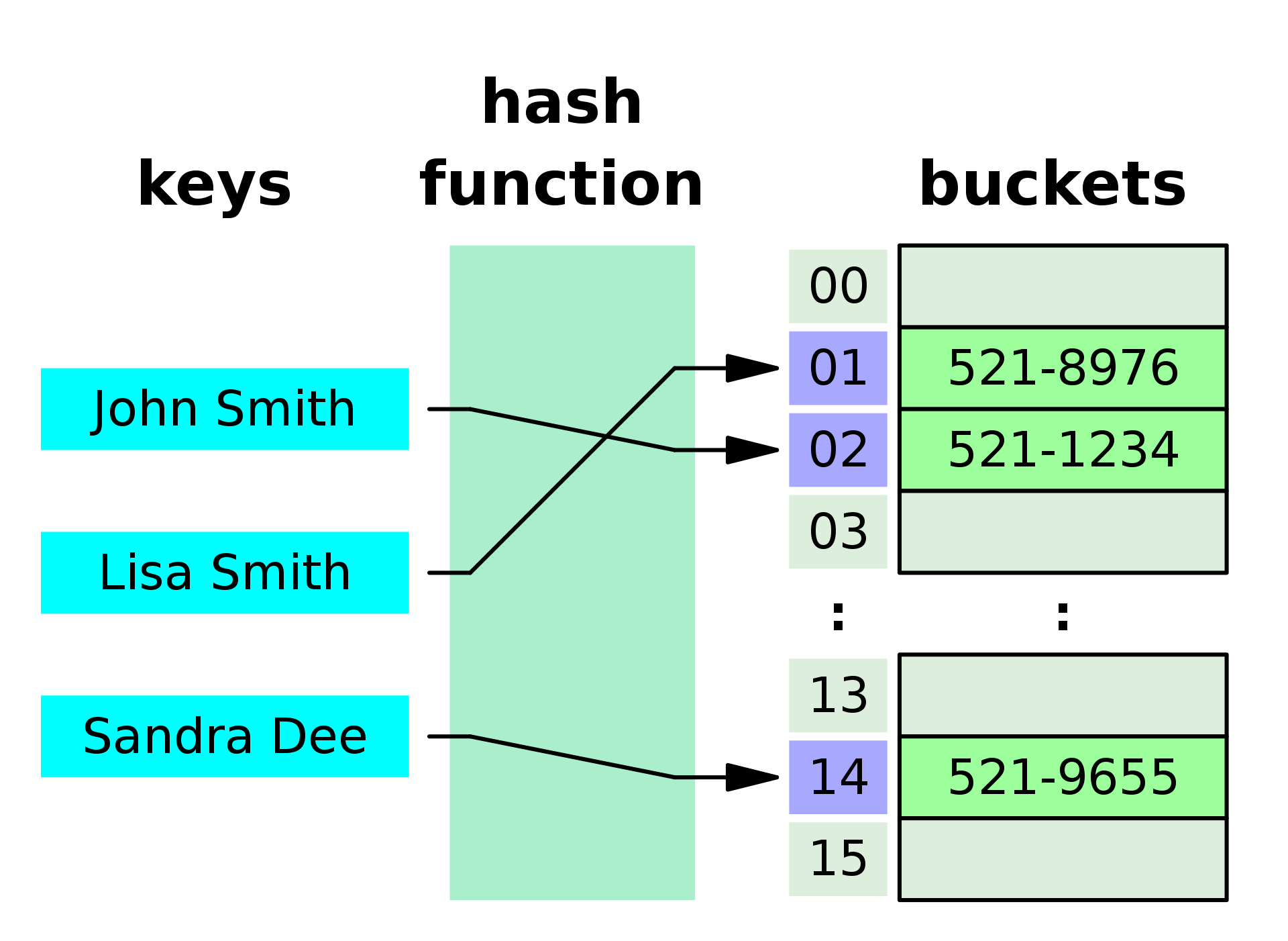
The hash function converts each key to a numerical hash value, which is then used to determine the storage location, or "bucket."
Buckets are containers within the hash table that hold the key-value pairs. The hash function aims to distribute keys uniformly across buckets to minimize collisions.
- Open-Addressing: Finds the next available bucket if a collision occurs.
- Chaining: Stores colliding keys in a linked list within the same bucket.
-
Time Complexity:
$O(1)$ - average and best-case,$O(n)$ - worst-case. -
Space Complexity:
$O(n)$
Here is the Python code:
# Initialize a hash table
hash_table = {}
# Add key-value pairs
hash_table['apple'] = 5
hash_table['banana'] = 2
hash_table['cherry'] = 3
# Retrieve a value
print(hash_table['apple']) # Output: 5
# Update a value
hash_table['banana'] = 4
# Remove a key-value pair
del hash_table['cherry']Hashing is a method that maps data to fixed-size values, known as hash values, for efficient storage and retrieval. A hash function generates these values, serving as the data's unique identifier or key.
- Speed: Hashing offers constant-time complexity for data operations.
- Data Integrity: A good hash function ensures even minor data changes will yield different hash values.
- Security: Cryptographic hashes are essential in secure data transmission.
- Collision Management: While hash collisions can occur, they are manageable and typically rare.
A hash function generates a fixed-size hash value, serving as the data's unique identifier or key for various applications like data indexing and integrity checks. Hash values are typically represented as hexadecimal numbers.
- Deterministic: The same input will always produce the same hash value.
- Fixed-Length Output: Outputs have a consistent length, making them suitable for data structures like hash tables.
- Speed: Hash functions are designed for quick computation.
- One-Way Functionality: Reconstructing the original input from the hash value should be computationally infeasible.
- Avalanche Effect: Small input changes should result in significantly different hash values.
- Collision Resistance: While it's difficult to completely avoid duplicate hash values for unique inputs, well-designed hash functions aim to minimize this risk.
- MD5: Obsolete due to vulnerabilities.
- SHA Family:
- SHA-1: Deprecated; collision risks.
- SHA-256: Widely used in cryptography.
- Databases: For quick data retrieval through hash indices.
- Distributed Systems: For data partitioning and load balancing.
- Cryptography: To ensure data integrity.
- Caching: For efficient in-memory data storage and access.
Here is the Python code:
import hashlib
def compute_sha256(s):
hasher = hashlib.sha256(s.encode())
return hasher.hexdigest()
print(compute_sha256("Hello, World!"))When discussing Hashing and Hash Tables, it's crucial to recognize that one is a technique while the other is a data structure. Here's a side-by-side comparison:
- Hashing: A computational technique that converts input (often a string) into a fixed-size value, referred to as a hash value.
- Hash Tables: A data structure that utilizes hash values as keys to efficiently store and retrieve data in memory.
- Hashing: To generate a unique identifier (hash value) for a given input, ensuring consistency and rapid computation.
- Hash Tables: To facilitate quick access to data by mapping it to a hash value, which determines its position in the table.
- Hashing: Common in cryptography for secure data transmission, data integrity checks, and digital signatures.
- Hash Tables: Used in programming and database systems to optimize data retrieval operations.
- Hashing: Focuses solely on deriving a hash value from input data.
- Hash Tables: Incorporates mechanisms to manage issues like hash collisions (when two distinct inputs produce the same hash value) and may also involve dynamic resizing to accommodate growing datasets.
-
Hashing: Producing a hash value is typically an
$O(1)$ operation, given a consistent input size. -
Hash Tables: On average, operations such as data insertion, retrieval, and deletion have
$O(1)$ time complexity, although worst-case scenarios can degrade performance.
- Hashing: Transient in nature; once the hash value is generated, the original input data isn't inherently stored or preserved.
- Hash Tables: Persistent storage structure; retains both the input data and its corresponding hash value in the table.
The parity function can serve as a rudimentary example of a hash function. It takes a single input, usually an integer, and returns either 0 or 1 based on whether the input number is even or odd.
- Deterministic: Given the same number, the function will always return the same output.
- Efficient: Computing the parity of a number can be done in constant time.
- Small Output Space: The output is limited to two possible values,
0or1. - One-Way Function: Given one of the outputs (
0or1), it is impossible to determine the original input.
Here is the Python code:
def hash_parity(n: int) -> int:
if n % 2 == 0:
return 0
return 1While the parity function serves as a simple example, real-world hash functions are much more complex. They often use cryptographic algorithms to provide a higher level of security and other features like the ones mentioned below:
- Cryptographic Hash Functions: Designed to be secure against various attacks like pre-image, second-pre-image, and collision.
- Non-Cryptographic Hash Functions: Used for general-purpose applications, data storage, and retrieval.
- Perfect Hash Functions: Provide a unique hash value for each distinct input.
Hash tables are at the core of many languages, such as Java, Python, and C++:
-
Key Insights: Hash tables allow for fast data lookups based on key values. They use a technique called hashing to map keys to specific memory locations, enabling
$O(1)$ time complexity for key-based operations like insertion, deletion, and search. -
Key Mapping: This is often implemented through a hash function, a mathematical algorithm that converts keys into unique integers (hash values or hash codes) within a fixed range. The hash value then serves as an index to directly access the memory location where the key's associated value is stored.
-
Handling Collisions:
- Challenges: Two different keys can potentially hash to the same index, causing what's known as a collision.
-
Solutions:
- Separate Chaining: Affected keys and their values are stored in separate data structures, like linked lists or trees, associated with the index. The hash table then maps distinct hash values to each separate structure.
- Open Addressing: When a collision occurs, the table is probed to find an alternative location (or address) for the key using specific methods.
-
Python
- Data Structure: Python uses an array of pointers to linked lists. Each linked list is called a "bucket" and contains keys that hash to the same index.
hashtab[hash(key) % size].insert(key, val)
- Size Dynamics: Python uses dynamic resizing, and its load factor dictates when resizing occurs.
- Data Structure: Python uses an array of pointers to linked lists. Each linked list is called a "bucket" and contains keys that hash to the same index.
-
Java
- Data Structure: The
HashMapclass uses an array of TreeNodes and LinkedLists, converting to trees after a certain threshold. - Size Dynamics: Java also resizes dynamically, triggered when the number of elements exceeds a load factor.
- Data Structure: The
-
C++ (Standard Library)
- Data Structure: Starting from C++11, the standard library
unordered_maptypically implements hash tables as resizable arrays of linked lists. - Size Dynamics: It also resizes dynamically when the number of elements surpasses a certain load factor.
- Data Structure: Starting from C++11, the standard library
Do note that C++ has several that may get used in hash tables, and it also uses separate chaining as a collision avoidance technique.
While hash tables provide constant-time lookups in the average case, several factors can influence their performance:
- Hash Function Quality: A good hash function distributes keys more evenly, promoting better performance. Collisions, especially frequent or hard-to-resolve ones, can lead to performance drops.
- Load Factor: This is the ratio of elements to buckets. When it gets too high, the structure becomes less efficient, and resizing can be costly. Java and Python automatically manage load factors during resizing.
- Resizing Overhead: Periodic resizing (to manage the load factor) can pause lookups, leading to a one-time performance hit.
In hash functions and tables, a hash collision occurs when two distinct keys generate the same hash value or index. Efficiently addressing these collisions is crucial for maintaining the hash table's performance.
- Hash Function Limitations: No hash function is perfect; certain datasets may result in more collisions.
- Limited Hash Space: Due to the Pigeonhole Principle, if there are more unique keys than slots, collisions are inevitable.
- Direct: When two keys naturally map to the same index.
- Secondary: Arising during the resolution of a direct collision, often due to strategies like chaining or open addressing.
The likelihood of a collision is influenced by the hash function's design, the number of available buckets, and the table's load factor.
Worst-case scenarios where all keys collide to the same index, can degrade a hash table's performance from
- Chaining: Each slot in the hash table contains a secondary data structure, like a linked list, to hold colliding keys.
- Open Addressing: The hash table looks for the next available slot to accommodate the colliding key.
- Cryptographic Hash Functions: These are primarily used to ensure data integrity and security due to their reduced collision probabilities. However, they're not commonly used for general hash tables because of their slower performance.
Consider a hash table that employs chaining to resolve collisions:
| Index | Keys |
|---|---|
| 3 | key1, key2 |
Inserting a new key that hashes to index 3 causes a collision. With chaining, the new state becomes:
| Index | Keys |
|---|---|
| 3 | key1, key2, key7 |
- Hash Collisions are Inevitable: Due to inherent mathematical and practical constraints.
- Strategies Matter: The efficiency of a hash table can be significantly influenced by the chosen collision resolution strategy.
- Probability Awareness: Being aware of collision probabilities is vital, especially in applications demanding high performance or security.
In hash tables, collisions occur when different keys yield the same index after being processed by the hash function. Let's look at common collision-handling techniques:
How it Works: Each slot in the table becomes the head of a linked list. When a collision occurs, the new key-value pair is appended to the list of that slot.
Pros:
- Simple to implement.
- Handles high numbers of collisions gracefully.
Cons:
- Requires additional memory for storing list pointers.
- Cache performance might not be optimal due to linked list traversal.
How it Works: If a collision occurs, the table is probed linearly (i.e., one slot at a time) until an empty slot is found.
Pros:
- Cache-friendly as elements are stored contiguously.
Cons:
- Clustering can occur, slowing down operations as the table fills up.
- Deleting entries requires careful handling to avoid creating "holes."
How it Works: Uses two hash functions. If the first one results in a collision, the second hash function determines the step size for probing.
Pros:
- Reduces clustering compared to linear probing.
- Accommodates a high load factor.
Cons:
- More complex to implement.
- Requires two good hash functions.
Here is the Python code:
class Node:
def __init__(self, key, value):
self.key = key
self.value = value
self.next = None
class HashTableWithChaining:
def __init__(self, size):
self.table = [None] * size
def _hash(self, key):
return hash(key) % len(self.table)
def insert(self, key, value):
index = self._hash(key)
new_node = Node(key, value)
# If slot is empty, simply assign it to the new node
if self.table[index] is None:
self.table[index] = new_node
return
# If slot is occupied, traverse to the end of the chain and append
current = self.table[index]
while current:
if current.key == key:
current.value = value # Overwrite if key already exists
return
if not current.next:
current.next = new_node # Append to the end
return
current = current.next
def get(self, key):
index = self._hash(key)
current = self.table[index]
while current:
if current.key == key:
return current.value
current = current.next
return None
# Example Usage:
hash_table = HashTableWithChaining(10)
hash_table.insert("key1", "value1")
hash_table.insert("key2", "value2")
hash_table.insert("key3", "value3")
hash_table.insert("key1", "updated_value1") # Update existing key
print(hash_table.get("key1")) # Output: updated_value1
print(hash_table.get("key2")) # Output: value2Here is the Python code:
class HashTable:
def __init__(self, size):
self.table = [None] * size
def _hash(self, key):
return hash(key) % len(self.table)
def insert(self, key, value):
index = self._hash(key)
while self.table[index] is not None:
if self.table[index][0] == key:
break
index = (index + 1) % len(self.table)
self.table[index] = (key, value)
def get(self, key):
index = self._hash(key)
while self.table[index] is not None:
if self.table[index][0] == key:
return self.table[index][1]
index = (index + 1) % len(self.table)
return NoneHere is the Python code:
class DoubleHashingHashTable:
def __init__(self, size):
self.table = [None] * size
def _hash1(self, key):
return hash(key) % len(self.table)
def _hash2(self, key):
return (2 * hash(key) + 1) % len(self.table)
def insert(self, key, value):
index = self._hash1(key)
step = self._hash2(key)
while self.table[index] is not None:
if self.table[index][0] == key:
break
index = (index + step) % len(self.table)
self.table[index] = (key, value)
def get(self, key):
index = self._hash1(key)
step = self._hash2(key)
while self.table[index] is not None:
if self.table[index][0] == key:
return self.table[index][1]
index = (index + step) % len(self.table)
return NoneA good hash function is fundamental for efficient data management in hash tables or when employing techniques such as hash-based encryption. Here, let's go through what it means for a hash function to be high-quality.
- Deterministic: The function should consistently map the same input to the same hash value.
-
Fast Performance: Ideally, the function should execute in
$O(1)$ time for typical use.
Collision is the term when two different keys have the same hash value.
- Few collisions: A good hash function minimizes the number of collisions when it is possible.
- Uniformly Distributed Hash Values: Each output hash value or, in the context of a hash table, each storage location should be equally likely for the positive performance of the hash table.
- Security Considerations: In the context of cryptographic hash functions, the one-way nature is essential, meaning it is computationally infeasible to invert the hash value.
- Value Independence: Small changes in the input should result in substantially different hash values, also known as the avalanche effect.
Here is the Python code:
def basic_hash(input_string):
'''A simple hash function using ASCII values'''
hash_val = 0
for char in input_string:
hash_val += ord(char)
return hash_valThis hash function sums up the ASCII values of the characters in input_string to get its hash value. While this function is easy to implement and understand, it is not a good choice in practice as it may not meet the characteristics mentioned above.
Here is the Python code:
import hashlib
def secure_hash(input_string):
'''A secure hash function using SHA-256 algorithm'''
hash_object = hashlib.sha256(input_string.encode())
hash_hex = hash_object.hexdigest()
return hash_hexIn this example, the hashlib library allows us to implement a cryptographic hash function using the SHA-256 algorithm. This algorithm is characterized by high security and the one-way nature essential for securing sensitive data.
Separate Chaining is a collision resolution technique employed in Hash Tables. This method entails maintaining a list of entries, often implemented as a linked list, for each bucket.
- Effective Collision Handling: It provides a consistent utility irrespective of the number of keys hashed.
- Easy to Implement and Understand: This technique is relatively simple and intuitive to implement.
- Bucket Assignment: Each key hashes to a specific "bucket," which could be a position in an array or a dedicated location in memory.
- Internal List Management: Keys within the same bucket are stored sequentially. Upon a collision, keys are appended to the appropriate bucket.
Search Performances
- Best-Case
$O(1)$ : The target key is the only entry in its bucket. - Worst-Case
$O(n)$ : All keys in the table hash to the same bucket, and a linear search through the list is necessary.
Here is the Python code:
# Node for key-value storage in the linked list
class Node:
def __init__(self, key, value):
self.key = key
self.value = value
self.next = None
# Hash table using separate chaining
class HashTable:
def __init__(self, capacity):
self.capacity = capacity
self.buckets = [None] * capacity # Initialize buckets with None
def hash(self, key):
return hash(key) % self.capacity # Basic hash function using modulo
def insert(self, key, value):
index = self.hash(key)
node = Node(key, value)
if self.buckets[index] is None:
self.buckets[index] = node
else:
# Append to the end of the linked list
current = self.buckets[index]
while current:
if current.key == key:
current.value = value # Update the value for existing key
return
if current.next is None:
current.next = node
return
current = current.next
def search(self, key):
index = self.hash(key)
current = self.buckets[index]
while current:
if current.key == key:
return current.value
current = current.next
return NoneOpen Addressing is a collision resolution technique where a hash table dynamically looks for alternative slots to place a colliding element.
- Linear Probing: When a collision occurs, investigate cells in a consistent sequence. The operation is mathematically represented as:
Here,
- Quadratic Probing: The cells to search are determined by a quadratic function:
Positive constants
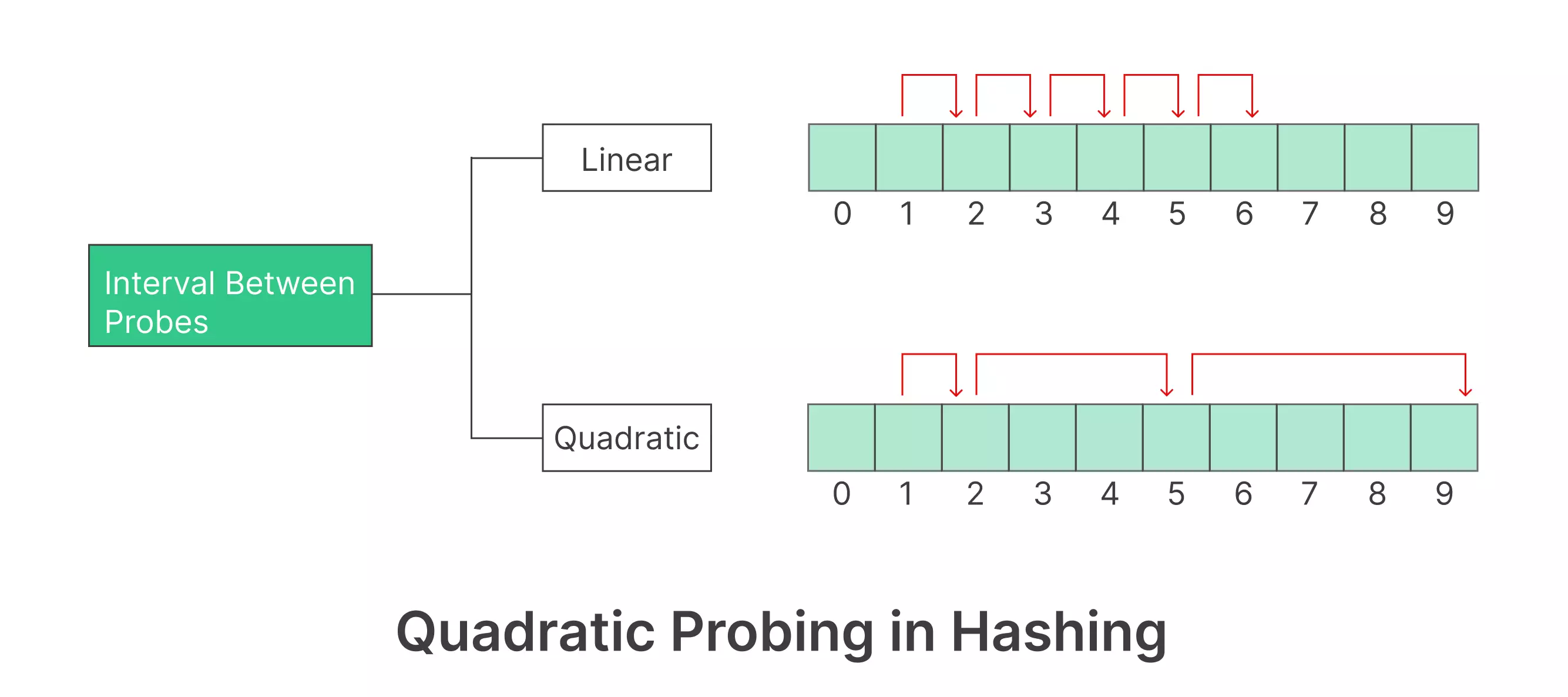
-
Double Hashing: Unlike with linear or quadratic probing, the second hash function
$h_2(k)$ computes the stride of the probe. The operation is:
Note: It's crucial for the new probe sequence to cover all positions in the table, thereby ensuring that every slot has the same probability of being the data's final location.
Hash tables offer impressive time and space performance under most conditions. Here's a detailed breakdown:
-
Best Case
$O(1)$ : With uniform distribution and no collisions, fundamental operations like lookup, insertion, and deletion are constant-time. -
Average and Amortized Case
$O(1)$ : Even with occasional collisions and rehashing, most operations typically remain constant-time. While rehashing can sometimes take$O(n)$ , its infrequency across many$O(1)$ operations ensures an overall constant-time complexity. -
Worst Case
$O(n)$ : Arises when all keys map to one bucket, forming a linked list. Such cases are rare and typically result from suboptimal hash functions or unique data distributions.
The primary storage revolves around the
The load factor is a key performance metric for hash tables, serving as a threshold for resizing the table. It balances time and space complexity by determining when the table is full enough to warrant expansion.
The load factor is calculated using the following formula:
It represents the ratio of stored elements to available buckets.
- Space Efficiency: It helps to minimize the table's size, reducing memory usage.
- Time Efficiency: A well-managed load factor ensures constant-time operations for insertion and retrieval.
- Collision Management: A high load factor can result in more collisions, affecting performance.
- Resizing: The load factor is a trigger for resizing the table, which helps in redistributing elements.
- Standard Defaults: Libraries like Java's
HashMapor Python'sdictusually have well-chosen default load factors. - Balanced Values: For most use-cases, a load factor between 0.5 and 0.75 strikes a good balance between time and space.
- Dynamic Adjustments: Some advanced hash tables, such as Cuckoo Hashing, may adapt the load factor for performance tuning.
The initial capacity is the starting number of buckets, usually a power of 2, while the load factor is a relative measure that triggers resizing. They serve different purposes in the operation and efficiency of hash tables.
The load factor is a key parameter that influences the performance and memory efficiency of a hashtable. It's a measure of how full the hashtable is and is calculated as:
When the load factor exceeds a certain predetermined threshold, known as the rehashing or resizing threshold, the table undergoes a resizing operation. This triggers the following:
- Rehashing: Every key-value pair is reassigned to a new bucket, often using a new hash function.
- Reallocating memory: The internal data structure grows or shrinks to ensure a better balance between load factor and performance.
- Insertions: As the load factor increases, the number of insertions before rehashing decreases. Consequently, insertions can be faster with a smaller load factor, albeit with a compromise on memory efficiency.
- Retrievals: In a well-maintained hash table, retrievals are expected to be faster with a smaller load factor.
However, these ideal situations might not hold in practice due to these factors:
-
Cache Efficiency: A smaller load factor might result in better cache performance, ultimately leading to improved lookup speeds.
-
Access Patterns: If insertions and deletions are frequent, a higher load factor might be preferable to avoid frequent rehashing, which can lead to performance overhead.
Here is the Python code:
class HashTable:
def __init__(self, initial_size=16, load_factor_threshold=0.75):
self.initial_size = initial_size
self.load_factor_threshold = load_factor_threshold
self.buckets = [None] * initial_size
self.num_entries = 0
def insert(self, key, value):
# Code for insertion
self.num_entries += 1
current_load_factor = self.num_entries / self.initial_size
if current_load_factor > self.load_factor_threshold:
self.rehash()
def rehash(self):
new_size = self.initial_size * 2 # Doubling the size
new_buckets = [None] * new_size
# Code for rehashing
self.buckets = new_bucketsResizing a hash table is essential to maintain efficiency as the number of elements in the table grows. Let's look at different strategies for resizing and understand their time complexities.
Resizing a hash table with separate chaining and open addressing entails different methods and time complexities:
-
Separate Chaining: Direct and has a time complexity of
$O(1)$ for individual insertions. -
Open Addressing: Requires searching for a new insertion position, which can make the insertion
$O(n)$ in the worst-case scenario. For handling existing elements during resizing, the complexity is$O(n)$ . Common heuristics and strategies, such as Lazy Deletion or Double Hashing, can help mitigate this complexity.
Array resizing is the most common method due to its simplicity and efficiency. It achieves dynamic sizing by doubling the array size when it becomes too crowded and halving when occupancy falls below a certain threshold.
-
Doubling Size: This action, also known as rehashing, takes
$O(n)$ time, where$n$ is the current number of elements. For each item currently in the table, the hash and placement in the new, larger table require$O(1)$ time. -
Halving Size: The table needs rescaling when occupancy falls below a set threshold. The current table is traversed, and all elements are hashed for placement in a newly allocated, smaller table, taking
$O(n)$ time.
- Resizing a dynamic list denoted as a table:
| Operation | Time Complexity |
|---|---|
| Insert/Drop at the end | O(1) |
| Insert/Drop at any position | O(1) |
| Doubling/Halving | O(n) |
Here is the Python code:
class HashTable:
def __init__(self, size):
self.size = size
self.threshold = 0.7 # Example threshold
self.array = [None] * size
self.num_elements = 0
def is_overloaded(self):
return self.num_elements / self.size > self.threshold
def is_underloaded(self):
return self.num_elements / self.size < 1 - self.threshold
def resize(self, new_size):
old_array = self.array
self.array = [None] * new_size
self.size = new_size
self.num_elements = 0
for item in old_array:
if item is not None:
self.insert(item)
def insert(self, key):
if self.is_overloaded():
self.resize(self.size * 2)
# Insert logic
self.num_elements += 1
def delete(self, key):
# Deletion logic
self.num_elements -= 1
if self.is_underloaded():
self.resize(self.size // 2)The efficiency of a hash table relies significantly on the hash function used. An inadequate hash function can lead to clustering, where multiple keys map to the same bucket, degrading performance to O(n), essentially turning the hash table into an unordered list.
On the other hand, a good hash function achieves a uniform distribution of keys, maximizing the O(1) operations. Achieving balance requires careful selection of the hash function and understanding its impact on performance.
-
Uniformity: Allowing for an even distribution of keys across buckets.
-
Consistency: Ensuring repeated calls with the same key return the same hash.
-
Minimizing Collisions: A good function minimizes the chances of two keys producing the same hash.
-
Identity Function: While simple, it doesn't support uniform distribution. It is most useful for testing or as a placeholder while the system is in development.
-
Modulous Function: Useful for small tables and keys that already have a uniform distribution. Be cautious with such an implementation, especially with table resizing.
-
Division Method: This hash function employs division to spread keys across defined buckets. The efficiency of this method can depend on the prime number that is used as the divisor.
-
MurmurHash: A non-cryptographic immersion algorithm, known for its speed and high level of randomness, making it suitable for general-purpose hashing.
-
MD5 and SHA Algorithms: While designed for cryptographic use, they still can be used in hashing where security is not a primary concern. However, they are slower than non-cryptographic functions for hashing purposes.
-
Keep it Simple: Hash functions don't have to be overly complex. Sometimes, a straightforward approach suffices.
-
Understand the Data: The nature of the data being hashed can often point to the most appropriate type of function.
-
Protect Against Malicious Data: If your data source isn't entirely trustworthy, consider a more resilient hash function.
Explore all 39 answers here 👉 Devinterview.io - Hash Table Data Structure