Born from the DAHN project, a technological and scientific collaboration between Inria, Le Mans Université and EHESS, and funded by the French Ministry of Higher Education, Research and Innovation (more information on this project can be found here), the pipeline aims at reaching the following goal: facilitate the digitization of data extracted from archival collections, and their dissemination to the public in the form of digital documents in various formats and/or as an online edition.
This pipeline has been created by Floriane Chiffoleau, under the supervision of Anne Baillot and Laurent Romary, and with the help of Alix Chagué and Manon Ovide.
As the previously showned schema demonstrated it, the pipeline for digital scholarly editions is made of six steps: digitization, segmentation, transcription, post-OCR correction, encoding and publication. Each of this steps requires interface, tools, scripts and documentation. Every element required to execute each phase is presented below.
Every publication project starts with a collection of papers. Even though the digital format of those papers (PDF, PNG, JPG, TIFF, etc.) does not matter for the process that they will go through afterwards, having those papers in a sustainable and interoperable state is preferable.
Consequently, the digitization phase relies on the IIIF (International Image Interoperability Framework) format to host images for the exploited corpus. Many IIIF servers exist to host images, some conservation sites have their own and they can upload some of their archives on it but it is not systematic. Therefore, in addition to the information given to add IIIF links to the future TEI XML files of the corpus, this pipeline proposes an easy-to-use and open-source (French) IIIF server.
- NAKALA --> To be able to use it, it is required that you create a Huma-Num account
- Documentation NAKALA
- Scripts for the execution of this step, going from gathering the metadata for the upload on NAKALA to adding the IIIF links to the TEI XML encoded files
- Documentation explaining how to run the scripts
- Blog post about the development of this step : Availability and high quality: distributing the facsimile with NAKALA
To obtain a machine-readable version of a collection of papers, it needs to go through the process of segmentation and transcription. Every page of the collection have to be segmented, i.e. have the layout and every line identified, and then transcribed, i.e. have the text contained by those lines recognized.
Many tools created to execute this specific task can be found online (some free and some not) but we chose a specific one for this step, because of the many advantages it brings. Firstly, it is not in command line but works with an interface, so it is easier to use for a beginner. Secondly, it works for printed, typewritten and handwritten texts. Thirdly, it does not only allow the user to segment/transcribe, it also proposes to train your own model with your own ground truth. Finally, this tool comes with an extended link to the digital humanities community, which offers ways to improve the experience with the chosen tool.
- Kraken --> It is the OCR system we are relying on to do this step
- eScriptorium --> This interface is an alternative to CLI transcription. To be able to use it, it is required to get an account.
- Documentation eScriptorium
- HTR-United: GitHub organization gathering ground truth of all periods and style of writing, mostly but not exclusively in French to rapidly train models on smaller corpora
- Documentation on how to do a transcription (using eScriptorium)
- Examples of models of segmentation and transcription and their logs
- Blog posts about the development of this step :
The process of text recognition is not perfect. Even with a highly accurate model, there are often errors still present in the transcription. This step has been created in order to speed up the process of correcting those errors.
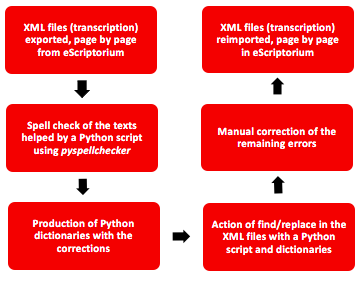
- Pyspellchecker --> It is the module used for spell checking the transcriptions
- Scripts to check for errors and subsequently correct it, available for Page XML, XML Alto and TEXT files
- Documentation on how to do a transcription (using eScriptorium) (same as the one in the previous step)
- Repository containing frequency words for a large selection of languages : hermitdave/FrequencyWords
- Blog post about the development of this step : Transcribing the corpus
- The TEI Guidelines
- Page2tei: GitHub repostiory for the transformation of a PAGE XML file into XML-TEI format
- Scripts for the encoding of TEXT files, for the metadata, the body and the named entities
- Documentation on how to use the various scripts mentioned before
- Guidelines for the encoding of ego documents
- Blog posts about the development of this step :
- eXist-db --> servor hosting TEI Publisher's platforms
- TEI Publisher
- Documentation of TEI Publisher
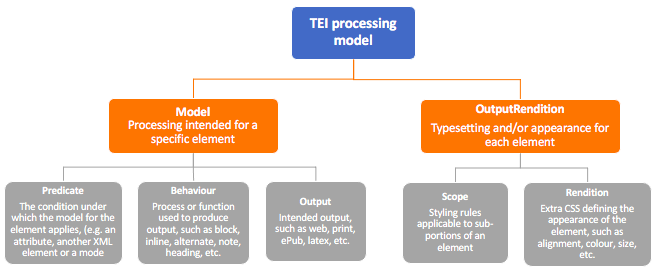
- Schema of how the TEI processing model works:
- Digital Scholarly Editions (DiScholEd) --> Application created for the publication of the corpora worked on to establish this pipeline
- Documentation of the composition and running of DiScholEd
- Blog posts about the development of this step :
During the development of the pipeline and the creation of its components, I took part in multiple conferences on digital humanities and other related topics, during which I presented the pipeline and its steps, according to its state of advancement. Here are the list of conferences in which I gave a presentation, as well as some of the publications I made afterwards.
- "Le projet DAHN, production d’une chaîne d’édition scientifique numérique pour un corpus d’égodocuments", Journées EVEille 2021, Journée 2 : Bibliothèques numériques, 12/02/2021 : https://eveille.hypotheses.org/journees-eveille-2021
- "DAHN: An accessible and transparent pipeline for publishing historical egodocuments ", What's Past is Prologue: The NewsEye International Conference 2021, 17/03/2021 : https://www.newseye.eu/blog/news/the-newseye-international-conference/
- "A TEI-based publication pipeline for historical egodocuments -the DAHN project", Next Gen TEI, 2021 - TEI Conference and Members’ Meeting, 26/10/2021 : https://tei-c.org/next-gen-tei-2021/
- "Penser la réutilisabilité patrimoniale : présentation de la pipeline d'édition numérique de documents d'archives du projet DAHN", Humanistica 2022, 20/05/2022 : https://humanistica2022.sciencesconf.org
- Alix Chagué, Floriane Chiffoleau. "An accessible and transparent pipeline for publishing historical egodocuments." WPIP21 - What's Past is Prologue: The NewsEye International Conference, Mar 2021, Virtual, Austria. ⟨hal-03173038⟩
- Floriane Chiffoleau, DAHN Project category, Digital Intellectuals Blog, 2020-2021: https://digitalintellectuals.hypotheses.org/category/dahn
- Floriane Chiffoleau, Anne Baillot, Manon Ovide. "A TEI-based publication pipeline for historical egodocuments -the DAHN project." Next Gen TEI, 2021 - TEI Conference and Members’ Meeting, Oct 2021, Virtual, United States. ⟨hal-03451421⟩
- Floriane Chiffoleau, Anne Baillot. "Le projet DAHN : une pipeline pour l'édition numérique de documents d'archives." 2022. ⟨hal-03628094⟩