- Criando avatares com IA
- Criando Imagens Diversas
- Por trás dos panos
- Comece a criar
- Conheça mais
- créditos
Recentemente tivemos um BOOM gigante no uso de inteligências artificiais que geram imagens. Primeiro tivemos os modelos da OpenAI, os famosos DALL-E e DALL-E 2, depois surgiram o Midjourney e o Stable Diffusion.
Por sua vez as BigTechs também não poderiam ficar de fora, com a Meta anunciando o Make-A-Video, modelo treinado para criar vídeos a partir de uma imagem, e a Google com o Stable DreamFusion, modelo que cria objetos em 3D.
A partir desses modelos, e suas APIs, vários desenvolvedores começaram a criar vários apps para smartphone que automatizam o uso deles. Nessa última semana de novembro de 2022, um app que ficou muito famoso foi o Lensa, criado pela Prisma Labs, mesma empresa que criou o app Prisma, app semelhante ao Lensa, só que mais voltado para a edição de imagens com IA.
Infelizmente o Lensa é pago, mas se você também estava curioso para testar essa IA, fique calmo, a IA em si é open-source, gratuita e não precisa de tanto conhecimento para utilizá-la.
Se você não tem computador, ou ele não é muito potente, uma saída é utilizar os modelos em nuvem da OpenAI ou o Midjourney.
Os modelos DALL-E da OpenAI estão agora abertos para o público, sendo assim, você pode entrar nesse site se registar e começar a usar, um único detalhe é que esse modelo possui algumas restrições em relação a rostos, marcas, etc. Sendo assim alguns prompts que você utilizar podem sair meio distorcidos. Além disso você não possui prompts ilimitados, a OpenAI te dá um espécie de crédito todo mês (referente a quantidade de prompts disponíveis) e caso queira utilizar mais neste mês, você terá de pagar uma certa taxa. Para mais detalhes leia a documentação.
Já no caso do Midjourney, ele é baseado em um bot de Discord, sendo assim, crie uma conta no Discord, entre no site deles siga as instruções que eles te passam e se divirta :)
Agora, se maquina disponível não é um problema para você, o recomendável é utilizar o StableDiffusion, para mais detalhes de uma olhada no site deles e também no github da Stability-AI.
Agora que você conhece alguns dos modelos que estão sendo usados hoje, vamos começar a criar alguns Avatares.
Como citado antes, o Lensa utiliza um modelo open-source, no caso o Stable Diffusion, utilizando um técnica, chamada de DreamBooth, que de maneira resumida, pega algumas imagens de entrada e a classe dessas imagens, e a partir disso ele gera um modelo personalizado de text-to-image, com isso você pode utilizar esse modelo para gerar imagens personalizadas a partir das entradas que você passou para ele antes.
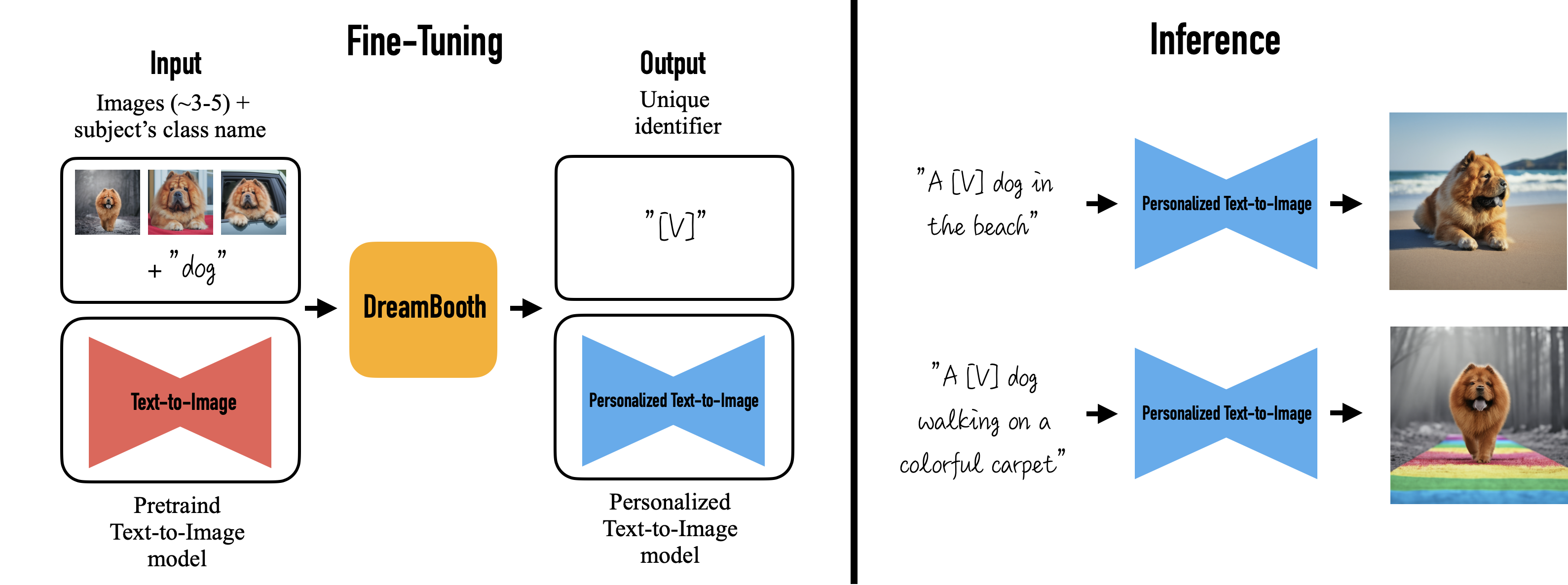
Com isso então, podemos utilizar um modelo já treinado para fazer nossas imagens, aqui utilizaremos um fork do modelo dísponivel no Github do huggingface criado pelo ShivamShrirao, do qual você pode encontrar aqui.
Para começar o tutorial, clique nesse botão abaixo
Se você está procurando o tutorial antigo clique aqui
Se você se interessar por essas inteligências artificiais, de uma olhada nessa lista de repositórios que criei.
Nela você encontrará ferramentas, modelos e outros apanhados de repositórios úteis.
Lista de repositórios
Fiz esse tutorial após ver alguns stories da Gi Bordignon(aka spacecoding), por favor, dê uma olhada nos perfis dela, vale a pena ;)