中文 | English







⚡特性:
- 添加ChatGPT fine-tuning实现,推荐有额度的朋友在ChatGPT上进行微调实验;
- 支持ChatGPT-Next-Web部署微调的模型;
- 支持Gradio部署微调的模型;
- 支持LLaMA、LLaMA-2全系列模型训练;
- 支持LoRA、QLoRA,包括后续PPO、DPO强化学习训练;
- 支持模型与知识库结合问答;
- 开源了超过60个医院科室的导诊材料信息;
- 开发了支持GPT-4/ChatGPT模型蒸馏医学数据的工具,能够批量生成各种用于构建知识库和微调的数据;
- 聚合了丰富的开源医学LLM、LLM训练的医学数据、LLM部署资料、LLM测评以及相关LLM的资源整理;
- 我们参与了医学LLM的CMB榜单评测-IvyGPT,在测试中,我们领先ChatGPT及一众开源医学LLM;
- 我们基于自有数据集在不同基座LLM上训练开源了多个医疗LLM,您可以直接下载体验;
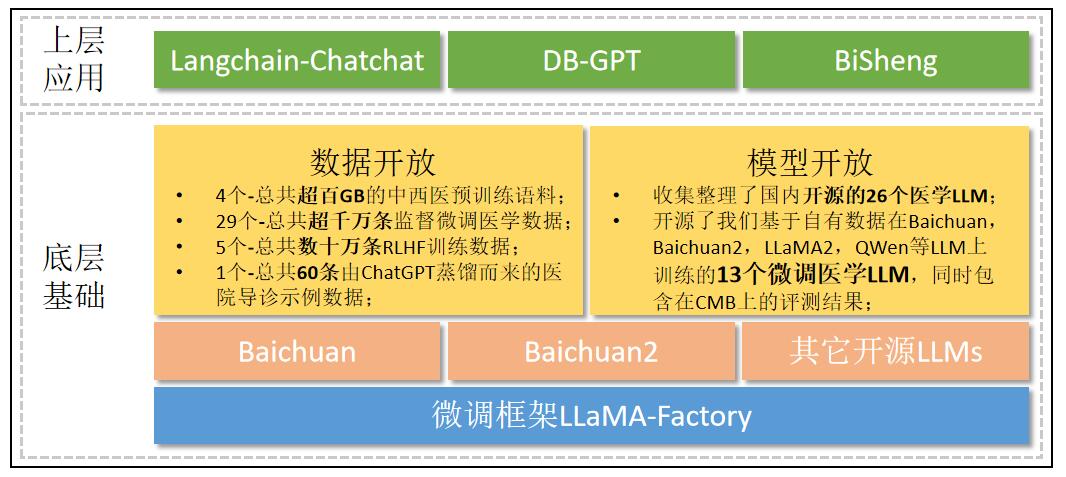
- LLM-Pretrain-FineTune/data_pretrain
- MedicalGPT/pretrain
- zysj
- TCM-Ancient-Books (近700项中医药古籍文本)
- epfl-llm/guidelines
- icliniq-10k(en)
- HealthCareMagic-100k(en)
- ShenNong_TCM_Dataset
- ✅ChatMed_Consult_Dataset
- Chinese-medical-dialogue-data
- cMedQA2
- ✅Huatuo-26M
- cMedQA2
- webMedQA
- PubMedQA
- CMCQA
- ✅QiZhenGPT
- ✅LLM-Pretrain-FineTune/data_sft
- Medical-Dialogue-System
- IMCS-V2
- CHIP-MDCFNPC
- MedDG
- ✅HuatuoGPT-sft-data-v1
- MedicalGPT/finetune
- ✅shibing624/medical
- medAlpaca/data
- ✅Zhongjing/sft
- medical_dialog
- huatuo_encyclopedia_qa
- Med-ChatGLM/data
- CMB
- GenMedGPT-5k(en)
- Alpaca-CoT(general)
- ✅DISC-Med-SFT
- ✅HuatuoGPT2_sft_instruct
- FreedomIntelligence/Medbase_data
conda create -n llm python=3.11
conda activate llm
python -m pip install -r requirements.txt# 转为HF格式
python -m transformers.models.llama.convert_llama_weights_to_hf \
--input_dir path_to_llama_weights --model_size 7B --output_dir path_to_llama_model- LLaMA-2模型下载:https://huggingface.co/meta-llama
数据集配置、PT、SFT、RW数据格式
如果您使用自定义数据集,请务必在 dataset_info.json 文件中以如下格式提供您的数据集定义。
"数据集名称": {
"hf_hub_url": "HuggingFace上的项目地址(若指定,则忽略下列三个参数)",
"script_url": "包含数据加载脚本的本地文件夹名称(若指定,则忽略下列两个参数)",
"file_name": "该目录下数据集文件的名称(若上述参数未指定,则此项必需)",
"file_sha1": "数据集文件的SHA-1哈希值(可选)",
"columns": {
"prompt": "数据集代表提示词的表头名称(默认:instruction)",
"query": "数据集代表请求的表头名称(默认:input)",
"response": "数据集代表回答的表头名称(默认:output)",
"history": "数据集代表历史对话的表头名称(默认:None)"
}
}其中 prompt 和 response 列应当是非空的字符串。query 列的内容将会和 prompt 列拼接作为模型输入。history 列应当是一个列表,其中每个元素是一个字符串二元组,分别代表用户请求和模型答复。
.txt格式,一行一个无监督数据。
Machine learning (ML) is a field devoted to understanding and building methods that let machines "learn" – that is, methods that leverage data to improve computer performance on some set of tasks.
Machine learning algorithms build a model based on sample data, known as training data, in order to make predictions or decisions without being explicitly programmed to do so. Machine learning algorithms are used in a wide variety of applications, such as in medicine, email filtering, speech recognition, agriculture, and computer vision, where it is difficult or unfeasible to develop conventional algorithms to perform the needed tasks.[
{
"instruction": "听起来很不错。人工智能可能在哪些方面面临挑战呢?",
"input": "",
"output": "人工智能面临的挑战包括数据隐私、安全和道德方面的问题,以及影响就业机会的自动化等问题。",
"history": [
["你好,你能帮我解答一个问题吗?", "当然,请问有什么问题?"],
["我想了解人工智能的未来发展方向,你有什么想法吗?", "人工智能在未来的发展方向可能包括更强大的机器学习算法,更先进的自然语言处理技术,以及更加智能的机器人。"]
]
}
][
{
"instruction": "听起来很不错。人工智能可能在哪些方面面临挑战呢?",
"input": "",
"output": "人工智能面临的挑战包括数据隐私、安全和道德方面的问题,以及影响就业机会的自动化等问题。",
"history": []
}
][
{
"instruction": "生成三个与“道歉”意思相同的动词",
"input": "",
"output": [
"承认,表示遗憾,弥补。",
"道歉"
]
}
]训练参数与指令
查看你的显卡是否是NVLINK连接,NVLINK连接才能有效使用accelerate进行并行加速训练。
nvidia-smi topo -m
accelerate config # configure the environment
accelerate launch src/train_bash.py # arguments (same as above)# LLaMA-2
accelerate launch src/train_bash.py \
--stage sft \
--model_name_or_path ./Llama-2-7b-chat-hf \
--do_train \
--dataset mm \
--finetuning_type lora \
--quantization_bit 4 \
--overwrite_cache \
--output_dir output \
--per_device_train_batch_size 8 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 2.0 \
--plot_loss \
--fp16 \
--template llama2 \
--lora_target q_proj,v_proj
# LLaMA
accelerate launch src/train_bash.py \
--stage sft \
--model_name_or_path ./Llama-7b-hf \
--do_train \
--dataset mm,hm \
--finetuning_type lora \
--overwrite_cache \
--output_dir output-1 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 2000 \
--learning_rate 5e-5 \
--num_train_epochs 2.0 \
--plot_loss \
--fp16 \
--template default \
--lora_target q_proj,v_proj# LLaMA-2, DPO
accelerate launch src/train_bash.py \
--stage dpo \
--model_name_or_path ./Llama-2-7b-chat-hf \
--do_train \
--dataset rlhf \
--template llama2 \
--finetuning_type lora \
--quantization_bit 4 \
--lora_target q_proj,v_proj \
--resume_lora_training False \
--checkpoint_dir ./output-2 \
--output_dir output-dpo \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 1e-5 \
--num_train_epochs 1.0 \
--plot_loss \
--fp16推理参数与指令
# LLaMA-2
python src/web_demo.py \
--model_name_or_path ./Llama-2-7b-chat-hf \
--checkpoint_dir output \
--finetuning_type lora \
--template llama2
# LLaMA
python src/web_demo.py \
--model_name_or_path ./Llama-7b-hf \
--checkpoint_dir output-1 \
--finetuning_type lora \
--template default
# DPO
python src/web_demo.py \
--model_name_or_path ./Llama-2-7b-chat-hf \
--checkpoint_dir output-dpo \
--finetuning_type lora \
--template llama2# LLaMA-2
python src/api_demo.py \
--model_name_or_path ./Llama-2-7b-chat-hf \
--checkpoint_dir output \
--finetuning_type lora \
--template llama2
# LLaMA
python src/api_demo.py \
--model_name_or_path ./Llama-7b-hf \
--checkpoint_dir output-1 \
--finetuning_type lora \
--template default
# DPO
python src/api_demo.py \
--model_name_or_path ./Llama-2-7b-chat-hf \
--checkpoint_dir output-dpo \
--finetuning_type lora \
--template llama2测试API:
curl -X 'POST' \
'http://127.0.0.1:8888/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "string",
"messages": [
{
"role": "user",
"content": "你好"
}
],
"temperature": 0,
"top_p": 0,
"max_new_tokens": 0,
"stream": false
}'# LLaMA-2
python src/cli_demo.py \
--model_name_or_path ./Llama-2-7b-chat-hf \
--checkpoint_dir output \
--finetuning_type lora \
--template llama2
# LLaMA
python src/cli_demo.py \
--model_name_or_path ./Llama-7b-hf \
--checkpoint_dir output-1 \
--finetuning_type lora \
--template default
# DPO
python src/cli_demo.py \
--model_name_or_path ./Llama-2-7b-chat-hf \
--checkpoint_dir output-dpo \
--finetuning_type lora \
--template llama2# LLaMA-2
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path ./Llama-2-7b-chat-hf \
--do_predict \
--dataset mm \
--template llama2 \
--finetuning_type lora \
--checkpoint_dir output \
--output_dir predict_output \
--per_device_eval_batch_size 8 \
--max_samples 100 \
--predict_with_generate
# LLaMA
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path ./Llama-7b-hf \
--do_predict \
--dataset mm \
--template default \
--finetuning_type lora \
--checkpoint_dir output-1 \
--output_dir predict_output \
--per_device_eval_batch_size 8 \
--max_samples 100 \
--predict_with_generate# LLaMA-2
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path ./Llama-2-7b-chat-hf \
--do_eval \
--dataset mm \
--template llama2 \
--finetuning_type lora \
--checkpoint_dir output \
--output_dir eval_output \
--per_device_eval_batch_size 8 \
--max_samples 100 \
--predict_with_generate
# LLaMA
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path ./Llama-7b-hf \
--do_eval \
--dataset mm \
--template default \
--finetuning_type lora \
--checkpoint_dir output-1 \
--output_dir eval_output \
--per_device_eval_batch_size 8 \
--max_samples 100 \
--predict_with_generate在4/8-bit评估时,推荐使用--per_device_eval_batch_size=1和--max_target_length 128
Gradio部署指令
# LLaMA-2
python src/export_model.py \
--model_name_or_path ./Llama-2-7b-chat-hf \
--template llama2 \
--finetuning_type lora \
--checkpoint_dir output-1 \
--output_dir output_export
# LLaMA
python src/export_model.py \
--model_name_or_path ./Llama-7b-hf \
--template default \
--finetuning_type lora \
--checkpoint_dir output \
--output_dir output_export%cd Gradio
python app.py
6.ChatGPT-Next-Web部署
Next部署指令
# LLaMA-2
python src/api_demo.py \
--model_name_or_path ./Llama-2-7b-chat-hf \
--checkpoint_dir output \
--finetuning_type lora \
--template llama2
# LLaMA
python src/api_demo.py \
--model_name_or_path ./Llama-7b-hf \
--checkpoint_dir output-1 \
--finetuning_type lora \
--template default- 下载Next:
- 修改配置:
安装并打开Next,然后打开
设置,修改接口地址为:http://127.0.0.1:8000/(即你的API接口地址),然后就可以使用了。

- 在CareGPT中并未对分词模型进行中文分词的添加和重新训练,但是效果依旧表现可喜;
- 全流程的LLM训练包括:预训练、监督微调、奖励模型、强化学习,多数情况下监督微调即可满足自身需求;
- 在算力充足情况下推荐使用医疗数据和通用语料数据进行训练,这样模型既可以有医学上的训练学习,也可以保持通用能力(如指令遵循);
- 不要指望一个医疗LLM就可以满足所有需求,合理的做法可能是实时更新的知识库+微调的医疗LLM(如ChatLaw);
- BLOOMZ模型系列使用了PILE语料库进行训练,该语料库包含各种医学文本,包括
PubMed Central和PubMed Abstracts等。这些宝贵的文本极大地丰富了BLOOMZ模型的医学知识体系,所以很多开源项目都会优先选择BLOOMZ做医学微调的底座模型; - (2023.08.26) ChatGPT基于代码GPT训练而来,那我们采用CodeLLaMA在下游任务微调会不会比在LLaMA-1/2上微调取得更好的结果呢?
- 结合我们最近的工作与最近许多公开发表的工作证明:在LLM时代,数据
质量 > 数量这个真理,如:Less is More! 上交清源 && 里海 | 利用200条数据微调模型,怒超MiniGPT-4!,超大规模的SFT数据会让下游任务LLM减弱或者失去ICL、CoT等能力; - 对于垂类模型,或许我们更应该关注PT的过程,而不是采集千万百万的SFT数据做训练,我们的建议是
大规模预训练+小规模监督微调=超强的LLM模型; - 一个好的预训练医学LLM尚未在开源社区中被开放出来,期待有人能去补充这样的工作;
预训练可以灌入知识,监督微调只是激活领域能力(无法关注知识)?预训练的知识与监督微调知识应该呼应?预训练几十GB的语料知识会被原来数万亿token预训练的模型知识淹没?- 大量数据进行二次预训练需要配比各类型其他数据:(1)语言模型训练完成后,参数各个区域负责部分已经确定,如果大量增加某类在预训练时没有的知识,会造成参数的大幅度变化,造成整个语言模型能力损失; (2)进行大规模数据的二次预训练,需要添加5-10倍原始预训练中的数据,并打混后一起训练;
- 指令微调阶段不能够进行过多轮次训练:(1)针对少量数据进行多个EPOCH的训练,可能会造成语言关键区域变化,从而导致整个模型失效; (2)为了特定任务提升的指令微调,为了保证模型语言能力关键区不被大幅度调整,需要添加通用指令微调数据或者预训练数据;
- 训练数据要严格控制噪音:(1)预训练数据中如果出现少量连续的噪音数据,比如连续重复单词、非单词序列等,都可能造成特定维度的调整,从而使得模型整体PPL大幅度波动; (2)有监督微调指令中如果有大量与原有大语言模型不匹配的指令片段,也可能造成模型调整特定维度,从而使得模型整体性能大幅度下降;
- 大模型混合多种能力数据微调时呈现:高资源冲突,低资源增益,所以混合不同数据进行微调需要一定的工程技巧;
- 通常来说,lora与full-tuning有不可忽略的性能差异(如LoRA results in 4-6% lower performance compared to full fine-tuning);
- 7B系列模型请优先采用全参数微调方式,13B及以上参数模型可使用LoRA,QLoRA等方法;
- 超大参数模型即使被量化其能力依然能保持的较好;
- 虽然 LLM 训练(或者说在 GPU 上训练出的所有模型)有着不可避免的随机性,但多 lun 训练的结果仍非常一致;
- 如果受 GPU 内存的限制,QLoRA 提供了一种高性价比的折衷方案。它以运行时间增长 39% 的代价,节省了 33% 的内存;
- 在微调 LLM 时,优化器的选择不是影响结果的主要因素。无论是 AdamW、具有调度器 scheduler 的 SGD ,还是具有 scheduler 的 AdamW,对结果的影响都微乎其微;
- 虽然 Adam 经常被认为是需要大量内存的优化器,因为它为每个模型参数引入了两个新参数,但这并不会显著影响 LLM 的峰值内存需求。这是因为大部分内存将被分配用于大型矩阵的乘法,而不是用来保留额外的参数;
- 对于静态数据集,像多轮训练中多次迭代可能效果不佳。这通常会导致过拟和,使训练结果恶化;
- 如果要结合 LoRA,确保它在所有层上应用,而不仅仅是 Key 和 Value 矩阵中,这样才能最大限度地提升模型的性能;
- 调整 LoRA rank 和选择合适的 α 值至关重要。提供一个小技巧,试试把 α 值设置成 rank 值的两倍;
- 14GB RAM 的单个 GPU 能够在几个小时内高效地微调参数规模达 70 亿的大模型。对于静态数据集,想要让 LLM 强化成「全能选手」,在所有基线任务中都表现优异是不可能完成的。想要解决这个问题需要多样化的数据源,或者使用 LoRA 以外的技术;
- 根据NeurIPS workshop的建议,截止2023年12月18日,微调模型建议选型为
英文10B以下选择Mistral-7B中文,10B以下选择Yi-6B,10B以上选择Qwen-14B和Yi-34B;
Important
欢迎大家在ISSUE中补充新的经验!
11~13方法论来自于130亿大语言模型仅改变1个权重就会完全丧失语言能力!复旦大学自然语言处理实验室最新研究.
14方法论来自于How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition
17~25方法论来自LLM Optimization: Layer-wise Optimal Rank Adaptation (LORA) 中文版解读
| 阶段 | 权重介绍 | 下载地址 | 特点 | 底座模型 | 微调方法 | 数据集 |
|---|---|---|---|---|---|---|
| 🌟监督微调 | 多轮对话数据基于LLaMA2-7b-Chat训练而来 | ⚙️CareLlama2-7b-chat-sft-multi、🧰CareLlama2-7b-multi | 出色的多轮对话能力 | LLaMA2-7b-Chat | QLoRA | mm |
| 监督微调 | 丰富高效医患对话数据基于LLaMA2-7b-Chat训练而来 | ⚙️CareLlama2-7b-chat-sft-med | 出色的患者疾病诊断能力 | LLaMA2-7b-Chat | QLoRA | hm |
| 监督微调 | 混合数据基于LLaMA-7b训练而来 | ⚙️CareLlama1-7b-merge | 更出色的医疗对话能力 | LLaMA-7b | LoRA | mm,hm |
| 监督微调 | 混合数据基于LLaMA2-7b-Chat训练而来 | ⚙️CareLlama2-7b-merge、🧰CareLlama2-7b-merge-mix | 更出色的医疗对话能力 | LLaMA2-7b-Chat | QLoRA | mm,hm |
| DPO | ⚙️CareLlama2-7b-merge-dpo | rlhf | ||||
| 监督微调 | 更多混合数据基于LLaMA2-7b-Chat训练而来 | ⚙️CareLlama2-7b-super、🧰CareLlama2-7b-super-mix | 更出色的医疗对话能力 | LLaMA2-7b-Chat | QLoRA | mm,ls,ks,mc,ms,qz,hm |
| 监督微调 | 多轮对话数据基于Baichuan-13B-Chat训练而来 | ⚙️Baichuan-13B-Chat-sft-multi | 出色的多轮对话能力 | Baichuan-13B-Chat | QLoRA | mm |
| 监督微调 | 混合对话数据基于Baichuan-13B-Chat训练而来 | ⚙️Baichuan-13B-Chat-sft-merge | 更出色的医患对话能力 | Baichuan-13B-Chat | QLoRA | mm,hm |
| 监督微调 | 混合对话数据基于Baichuan-13B-Chat训练而来 | ⚙️Baichuan-13B-Chat-sft-super、🧰Baichuan-13B-Chat-sft-super-mix | 更出色的医患对话能力 | Baichuan-13B-Chat | QLoRA | mm,ls,ks,mc,ms,qz,hm |
| 🌟监督微调 | 多轮对话数据基于QWen-7B训练而来 | 🧰carellm | 出色的多轮对话能力 | QWen-7B | QLoRA | mm |
| 监督微调 | 多轮对话数据基于QWen-14B-Chat训练而来 | ⚙️careqwen-14B-Chat-sft-multi | 出色的多轮对话能力 | QWen-14B-Chat | QLoRA | mm |
| 监督微调 | 多轮对话数据基于InternLM-20B-Chat训练而来 | ⚙️careinternlm-20B-Chat-sft-multi、🧰careinternlm-20B-Chat-sft-multi-mix | 出色的多轮对话能力 | InternLM-20B-Chat | QLoRA | mm |
| 🌟监督微调 | 多轮对话数据基于Baichuan2-13B-Chat训练而来 | ⚙️Baichuan2-13B-Chat-sft-multi、🧰Baichuan2-13B-Chat-sft-multi-mix | 出色的多轮对话能力 | Baichuan2-13B-Chat | QLoRA | mm |
使用方法:
| Model | Institution | Score |
|---|---|---|
| ShuKunGPT | 数坤科技 | 64.44 |
| GPT-4 | OpenAI | 58.37 |
| Baichuan2-53B | 百川智能 | 45.69 |
| ChatGLM2-6B | 智谱AI | 44.91 |
| Baichuan-13B-chat | 百川智能 | 41.63 |
| IvyGPT (Baichuan2-13B+10W) | 澳门理工大学 | 38.54 |
| ChatGPT | OpenAI | 38.09 |
| IvyGPT (Baichuan-13B+10W) | 澳门理工大学 | 34.60 |
| ChatGLM3-6B | 智谱AI | 33.76 |
| HuatuoGPT (BLOOMZ) | 香港中文大学 (深圳) | 31.38 |
| IvyGPT (Qwen-7B+PT-WiNGPT32亿+10W) | 澳门理工大学 | 28.26 |
| MedicalGPT | - | 26.45 |
| ChatMed-Consult | 华东师范大学 | 21.71 |
| Bentsao | 哈尔滨工业大学 | 21.25 |
| ChatGLM-Med | 哈尔滨工业大学 | 20.67 |
| IvyGPT (LLaMA-2-7B+220W) | 澳门理工大学 | 18.55 |
| DoctorGLM | 上海科技大学 | 7.63 |
| BianQue-2 | 华东师范大学 | 7.26 |
| Model | Non-hallucination Rate |
|---|---|
| ERNIE-Bot | 69.33% |
| Baichuan2-53B | 68.22% |
| ChatGLM-Pro | 61.33% |
| GPT-4-0613 | 53.11% |
| QWen-14B-Chat | 46.89% |
| Baichuan2-13B-Chat | 42.44% |
| Baichuan2-7B-Chat | 40.67% |
| GPT3.5-turbo-0613 | 39.33% |
| ChatGLM2-6B | 34.89% |
| Baichuan2-13B-base | 33.78% |
| Baichuan-13B-Chat | 31.33% |
| Baichuan-13B-base | 25.33% |
| Baichuan2-7B-base | 25.33% |
| Baichuan-7B-base | 22.22% |
参考自:2310.03368.pdf

查看更多演示





本项目相关资源仅供学术研究之用,严禁用于商业用途。使用涉及第三方代码的部分时,请严格遵循相应的开源协议。模型生成的内容受模型计算、随机性和量化精度损失等因素影响,本项目无法对其准确性作出保证。即使本项目模型输出符合医学事实,也不能被用作实际医学诊断的依据。对于模型输出的任何内容,本项目不承担任何法律责任,亦不对因使用相关资源和输出结果而可能产生的任何损失承担责任。
- CareGPT(原名CareLlama) 为MPU的医疗大语言模型IvyGPT的分支,其存在意义是探索医疗数据、医疗LLM训练与部署相关的工作研究。
- 本工作由澳门理工大学应用科学学院硕士研究生王荣胜、周瑞哲、陈浩铭完成,指导老师为檀韬副教授和王亚鹏副教授。
- 我们的工作(IvyGPT)已经被CMB论文引用,相关论文已经被提交至NAACL:https://openreview.net/pdf?id=rHDSaubv25
如果你使用了本项目的模型,数据或者代码,请声明以下引用:
@misc{wang2023caregpt,
title={CareGPT: Medical LLM, Open Source Driven for a Healthy Future},
author={Rongsheng Wang, Ruizhe Zhou, Haoming Chen, Yapeng Wang, Tao Tan},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/WangRongsheng/CareGPT}},
}@article{wang2023ivygpt,
title={IvyGPT: InteractiVe Chinese pathwaY language model in medical domain},
author={Wang, Rongsheng and Duan, Yaofei and Lam, ChanTong and Chen, Jiexi and Xu, Jiangsheng and Chen, Haoming and Liu, Xiaohong and Pang, Patrick Cheong-Iao and Tan, Tao},
journal={arXiv preprint arXiv:2307.10512},
year={2023}
}@Misc{llama-factory,
title = {LLaMA Factory},
author = {hiyouga},
howpublished = {\url{https://github.com/hiyouga/LLaMA-Factory}},
year = {2023}
} |
本项目已被收录到机器之心SOTA库,获 |
 |
本项目已参与Backdrop Build V2活动。 |
 |
本项目已参与百川智能携手亚马逊云科 |
此存储库遵循MIT License ,请参阅许可条款。
如果觉得这个项目对您有所帮助,并且愿意支持我们的工作,您可以通过以下方式(请备注您的微信给我们):
 |
 |
您的支持将是我们继续探索LLM的动力,所有的支持将用于模型的推理部署任务中。
- https://github.com/llSourcell/DoctorGPT
- https://github.com/facebookresearch/llama-recipes
- https://github.com/Kent0n-Li/ChatDoctor
- https://github.com/michael-wzhu/ShenNong-TCM-LLM
- https://github.com/michael-wzhu/ChatMed
- https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
- https://github.com/SCIR-HI/Med-ChatGLM
- https://github.com/xionghonglin/DoctorGLM
- https://github.com/MediaBrain-SJTU/MING
- https://github.com/CMKRG/QiZhenGPT
- https://github.com/NLPxiaoxu/LLM-Pretrain-FineTune
- https://github.com/scutcyr/BianQue
- https://github.com/thomas-yanxin/Sunsimiao
- https://github.com/kbressem/medAlpaca
- https://github.com/FreedomIntelligence/HuatuoGPT
- https://github.com/shibing624/MedicalGPT
- https://github.com/chaoyi-wu/PMC-LLaMA
- https://github.com/pariskang/CMLM-ZhongJing
- https://github.com/SupritYoung/Zhongjing
- https://github.com/openmedlab/PULSE
- https://github.com/FudanDISC/DISC-MedLLM
- https://github.com/Zlasejd/HuangDI
- https://github.com/2020MEAI/TCMLLM
- https://github.com/PharMolix/OpenBioMed
- https://huggingface.co/Writer/palmyra-med-20b
- https://github.com/winninghealth/WiNGPT2
- https://github.com/DUTIR-BioNLP/Taiyi-LLM
- https://github.com/TONYCHANBB/HealGPT
- https://github.com/som-shahlab/Clinfo.AI
- https://github.com/DUTIR-BioNLP/Taiyi-LLM
- https://github.com/OptimalScale/LMFlow
- https://huggingface.co/SYNLP/ChiMed-GPT-1.0
- https://github.com/AI-in-Health/DrugGPT
- https://github.com/epfLLM/meditron
- https://github.com/FreedomIntelligence/HuatuoGPT-II
- https://github.com/baiyang2464/chatbot-base-on-Knowledge-Graph
- https://huggingface.co/BioMistral/BioMistral-7B
- https://github.com/MAGIC-AI4Med/MMedLM
- https://github.com/FreedomIntelligence/CMB
- https://github.com/MaksymPetyak/medplexity
- https://github.com/MediaBrain-SJTU/GenMedicalEval
- https://medical.chat-data.com/
- http://med.fudan-disc.com/
- https://www.huatuogpt.cn/
- https://huggingface.co/spaces/wangrongsheng/CareLlama
- (password)https://huggingface.co/spaces/fb700/chatglm-fitness-RLHF
- http://heal-gpt.cn/
- 商汤科技-大医:https://chat.sensetime.com/
- 科大讯飞-讯飞晓医:小程序搜索使用
- https://www.clinfo.ai/
- 阿里通义仁心:https://tongyi.aliyun.com/renxin
- https://github.com/a16z-infra/llama2-chatbot
- https://github.com/liltom-eth/llama2-webui
- https://github.com/soulteary/docker-llama2-chat
- https://huggingface.co/spaces/LinkSoul/Chinese-Llama-2-7b
- https://github.com/mushan0x0/AI0x0.com
- https://github.com/Yidadaa/ChatGPT-Next-Web
- https://github.com/sunner/ChatALL
- https://github.com/chatchat-space/Langchain-Chatchat
- https://github.com/wenda-LLM/wenda
- https://github.com/xusenlinzy/api-for-open-llm
- https://github.com/yuanjie-ai/ChatLLM
- https://github.com/labring/FastGPT
- https://github.com/vllm-project/vllm
- https://github.com/dataelement/bisheng
- https://github.com/lobehub/lobe-chat
- https://github.com/purton-tech/bionicgpt
- https://github.com/Chainlit/chainlit
- https://github.com/arc53/DocsGPT
- https://vercel.com/templates/ai
- https://github.com/ollama-webui/ollama-webui
- https://github.com/huggingface/chat-ui
- https://github.com/xusenlinzy/api-for-open-llm
- https://github.com/yanqiangmiffy/GoGPT-Instruction
- https://github.com/wpydcr/LLM-Kit
- https://github.com/huang1332/finetune_dataset_maker
- https://github.com/threeColorFr/LLMforDialogDataGenerate
- https://github.com/alibaba/data-juicer
- https://github.com/duanyu/LabelFast
- https://label-assistant.vercel.app/
- https://github.com/onejune2018/Awesome-Medical-Healthcare-Dataset-For-LLM
- https://github.com/WangRongsheng/MedQA-ChatGLM
- https://github.com/hiyouga/LLaMA-Efficient-Tuning
- https://github.com/WangRongsheng/Use-LLMs-in-Colab
- https://github.com/HqWu-HITCS/Awesome-Chinese-LLM
- https://github.com/LearnPrompt/LLMs-cookbook
- https://github.com/liucongg/ChatGPTBook
- https://github.com/EvilPsyCHo/train_custom_LLM
- https://github.com/QwenLM/Qwen-VL
- https://github.com/haotian-liu/LLaVA
- https://github.com/kyegomez/Med-PaLM
- https://github.com/williamliujl/Qilin-Med-VL
- https://github.com/LLaVA-VL/LLaVA-Plus-Codebase
- https://github.com/Yuliang-Liu/Monkey
