English | 中文简体
This project is based on GPT3.5-turbo and can answer user's questions based on the PDF text files provided by the user.
Here is a simple example:
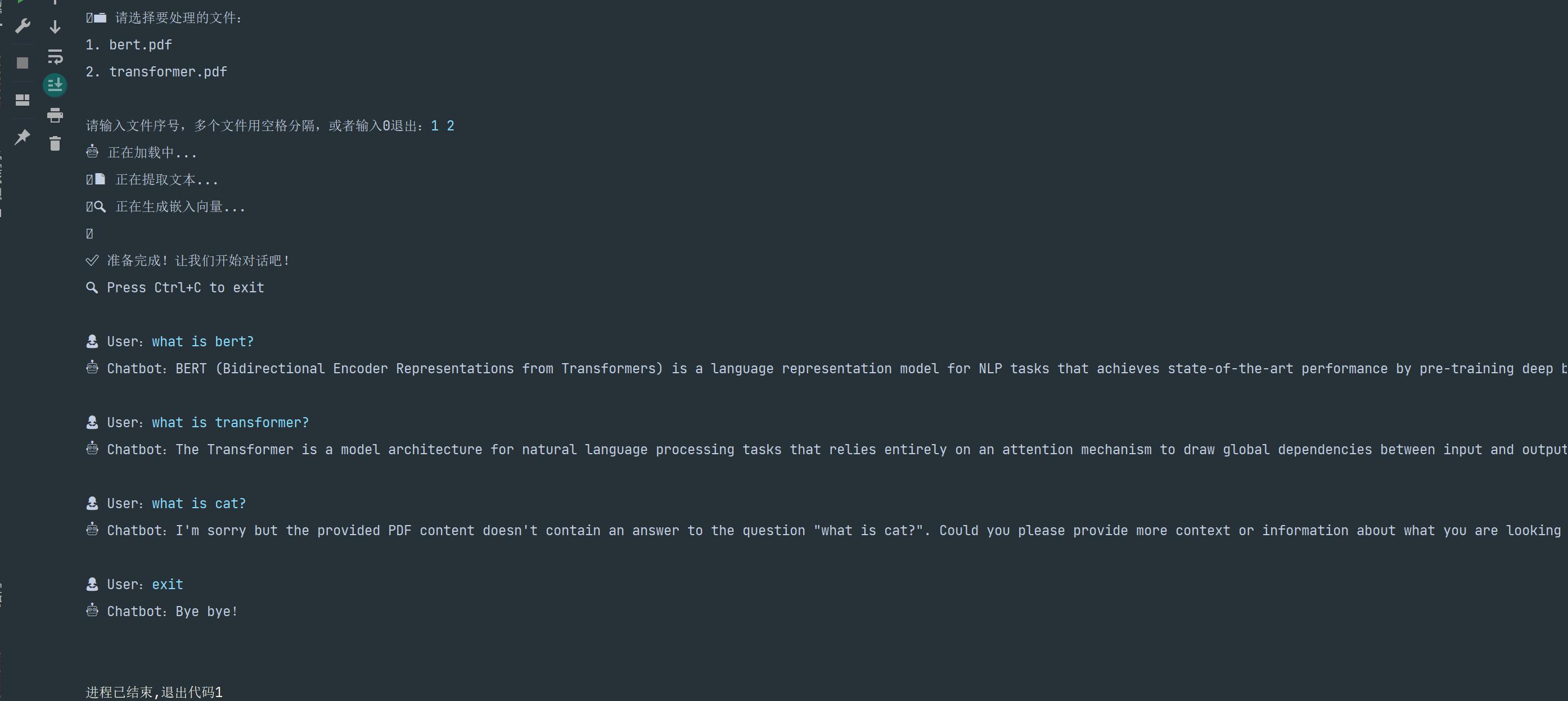
.
├── .env.example # Example environment variables file
├── .gitignore # Git ignore rules file
├── example_history.json # JSON file containing example history
├── LICENSE # License file
├── main.py # Main Python script
├── README.md # Readme file in English
├── README.zh-CN.md # Readme file in Simplified Chinese
├── requirements.txt # File listing required dependencies
├── setup.sh # Shell script for setup
├── utils.py # Utility Python script
└── pdf_files # Directory containing PDF files
├── bert.pdf # PDF file named bert
└── transformer.pdf # PDF file named transformer
- Read the PDF file and segment it.
- Generate a feature vector for each text segment using
text-embedding-ada-002. - Generate a feature vector for user input.
- Calculate the similarity between the user input and the text using
distances_from_embeddings, and return a list of the most similar texts. - Design a prompt and use
GPT3.5-turboto generate answers based on the most similar text list.
- Download the project
git@github.com:Duguce/Mini-ChatPDF.git && cd Mini-ChatPDF
- Create a virtual environment and install the required dependencies
./setup.sh
- Set up environment variables
Obtain a GPT API key from OpenAI and copy it to the corresponding location in the .env file.
- Add documents
Add the PDF documents you want to use in the ./pdf_files/ directory.
- Activate the virtual environment
source .venv/bin/activate
- Run the script
You should see (.venv) ~/Mini-ChatPDF$ when you run the script. If not, please first run source .venv/bin/activate
python main.py
- Start the conversation
-
Support reading multiple PDF documents simultaneously.
-
Support other text encoding vector methods.
-
Add functionality to save text encoding vectors.
-
Implement a graphical user interface (GUI).
-
Optimize the
prompt.
This project is licensed under the MIT License.