


This repository is my bachelor graduation project, and it is also a study of TensorFlow, Deep Learning (CNN, RNN, etc.).
The main objective of the project is to determine whether the two sentences are similar in sentence meaning (binary classification problems) by the two given sentences based on Neural Networks (Fasttext, CNN, LSTM, etc.).
- Python 3.6
- Tensorflow 1.1 +
- Numpy
- Gensim
- Make the data support Chinese and English (Which use
jiebaseems easy). - Can use your own pre-trained word vectors (Which use
jiebaseems easy). - Add embedding visualization based on the tensorboard.
- Design two subnetworks to solve the task --- Text Pairs Similarity Classification.
- Add the correct L2 loss calculation operation.
- Add gradients clip operation to prevent gradient explosion.
- Add learning rate decay with exponential decay.
- Add a new Highway Layer (Which is useful according to the model performance).
- Add Batch Normalization Layer.
- Add several performance measures (especially the AUC) since the data is imbalanced.
- Can choose to train the model directly or restore the model from the checkpoint in
train.py. - Add
test.py, the model test code, it can show the predicted values and predicted labels of the data in Testset when creating the final prediction file. - Add other useful data preprocess functions in
data_helpers.py. - Use
loggingfor helping to record the whole info (including parameters display, model training info, etc.). - Provide the ability to save the best n checkpoints in
checkmate.py, whereas thetf.train.Savercan only save the last n checkpoints.
See data format in data folder which including the data sample files.
You can use jieba package if you are going to deal with the Chinese text data.
This repository can be used in other datasets (text pairs similarity classification) in two ways:
- Modify your datasets into the same format of the sample.
- Modify the data preprocess code in
data_helpers.py.
Anyway, it should depend on what your data and task are.
You can pre-training your word vectors (based on your corpus) in many ways:
- Use
gensimpackage to pre-train data. - Use
glovetools to pre-train data. - Even can use a fasttext network to pre-train data.
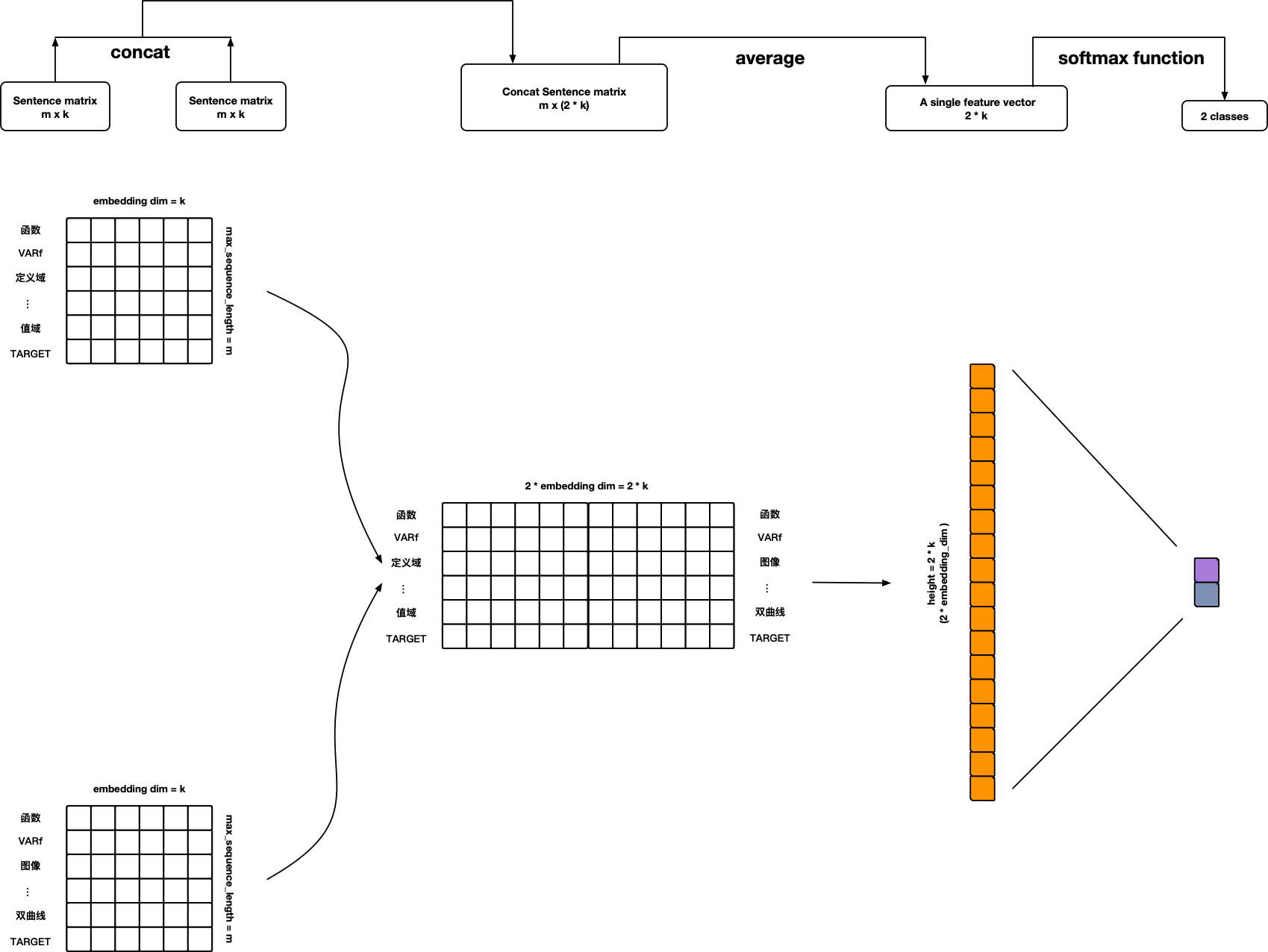
References:
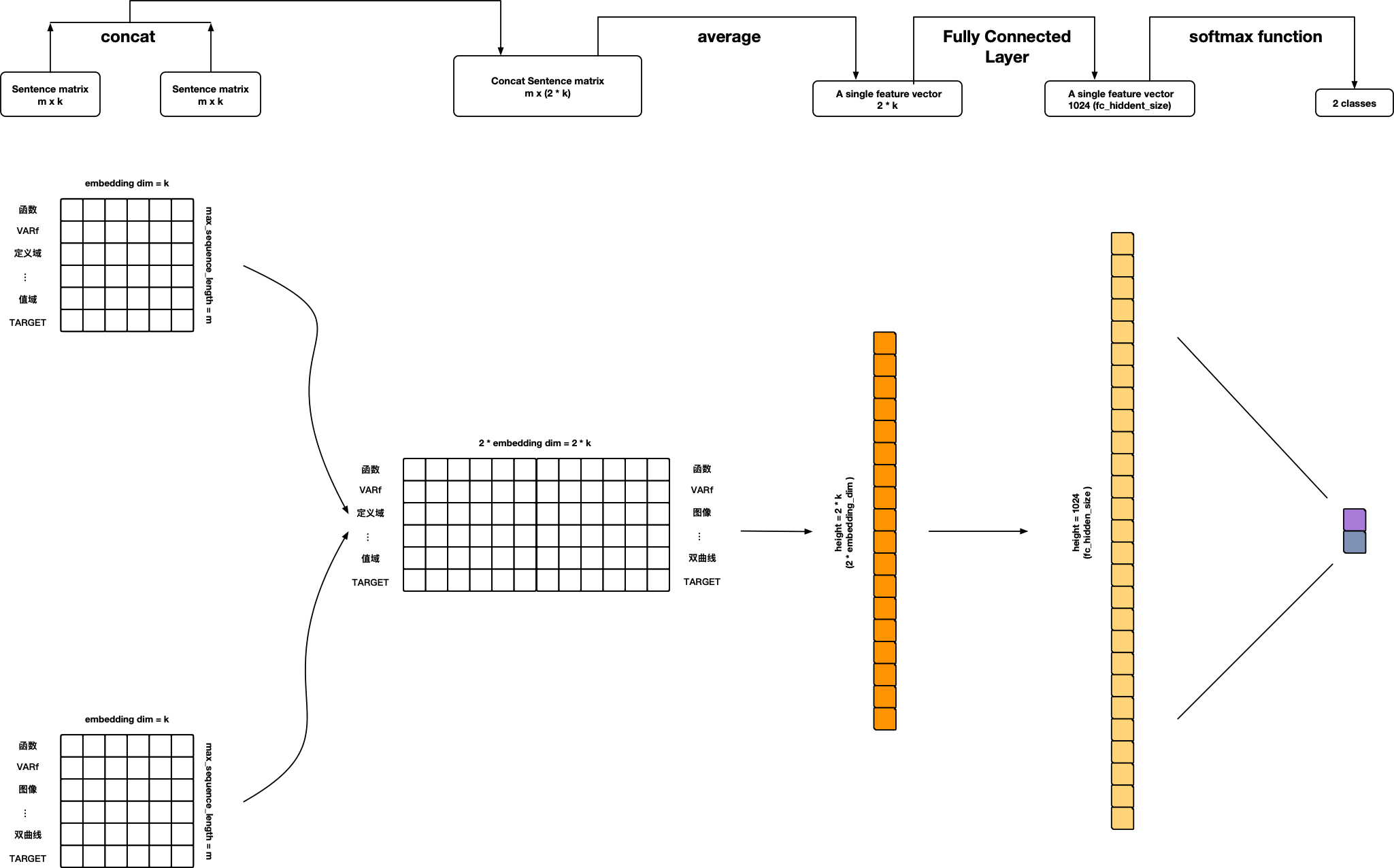
References:
- Personal ideas 🙃
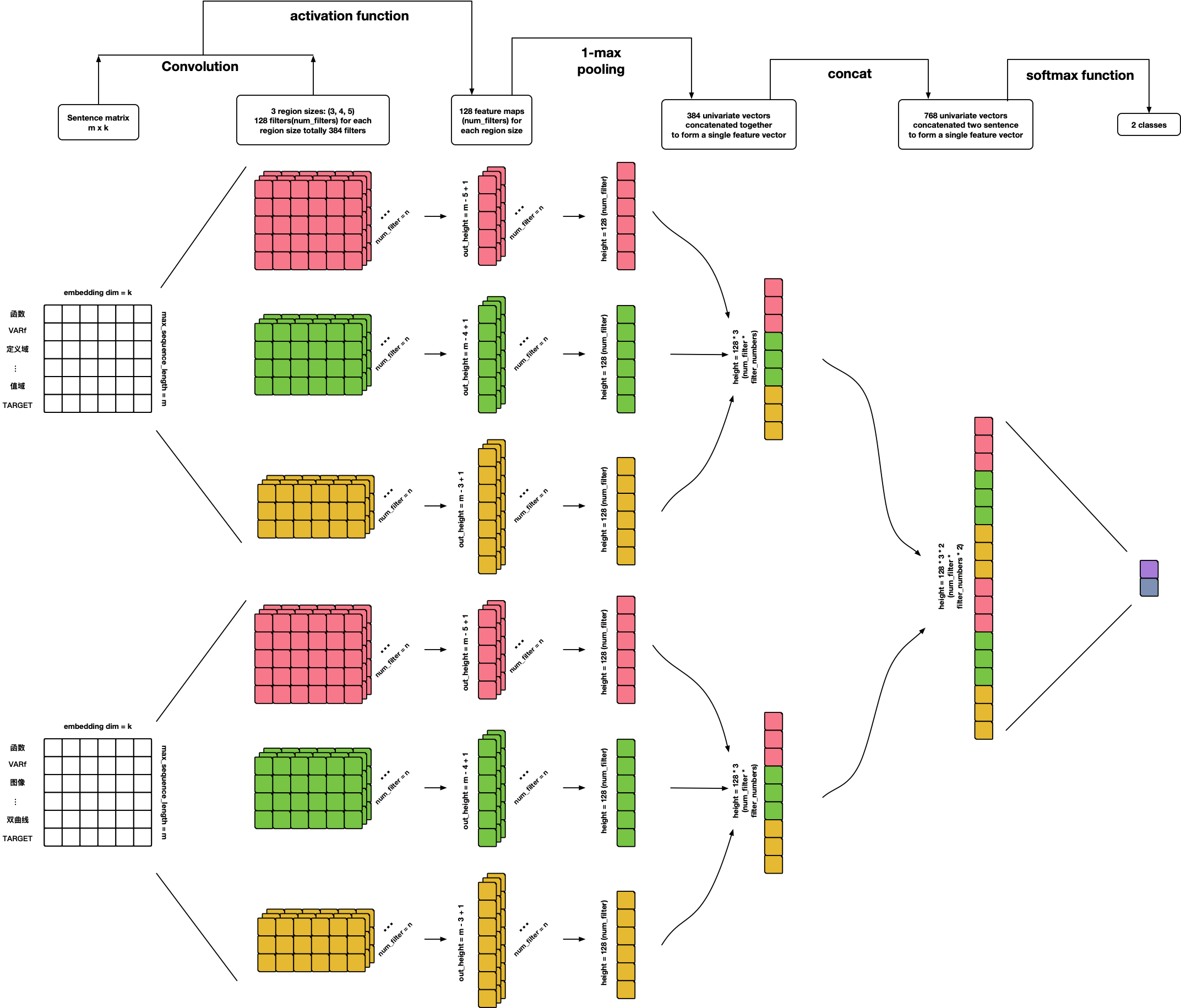
References:
- Convolutional Neural Networks for Sentence Classification
- A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification
Warning: Model can use but not finished yet 🤪!
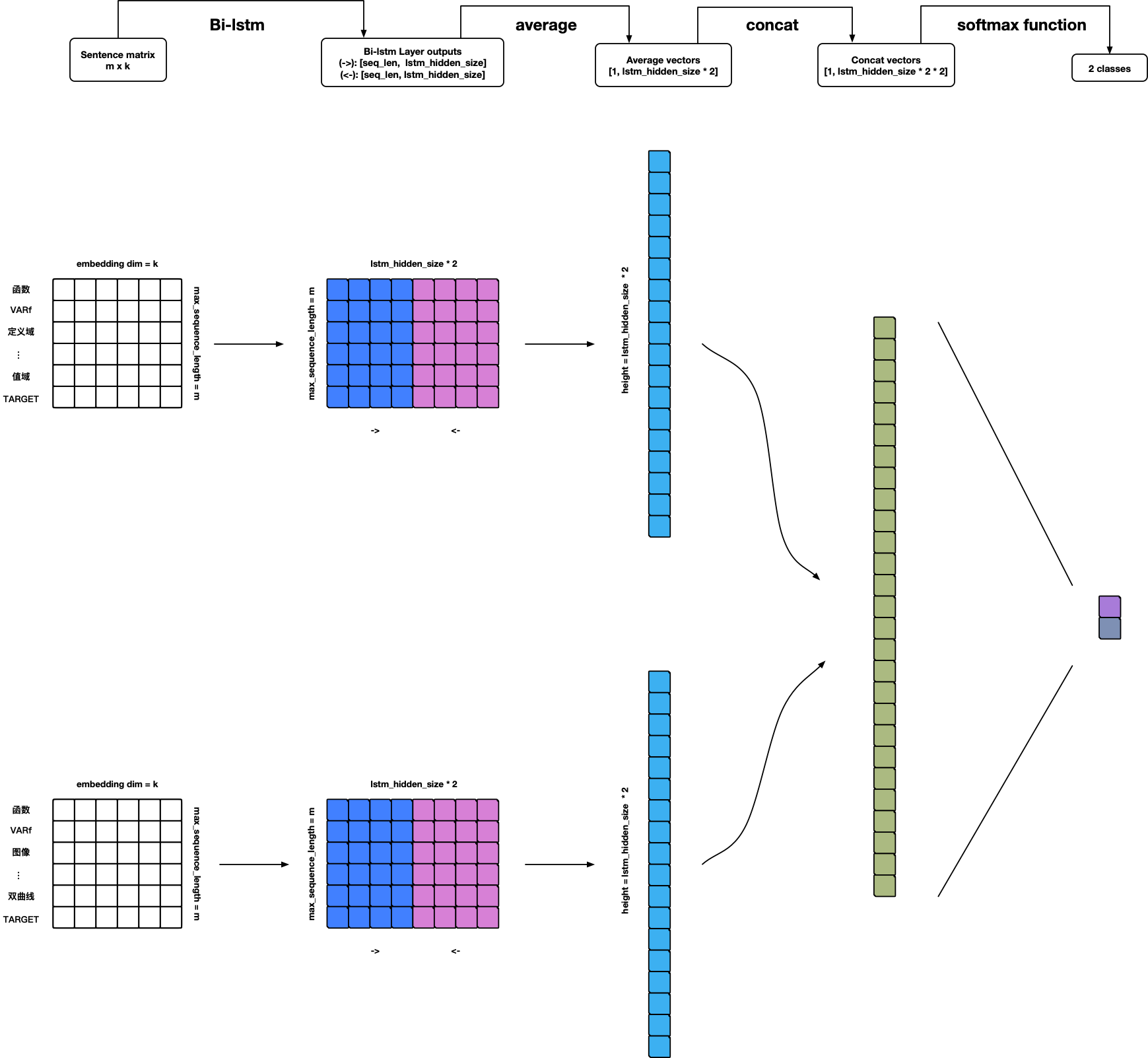
- Add BN-LSTM cell unit.
- Add attention.
References:
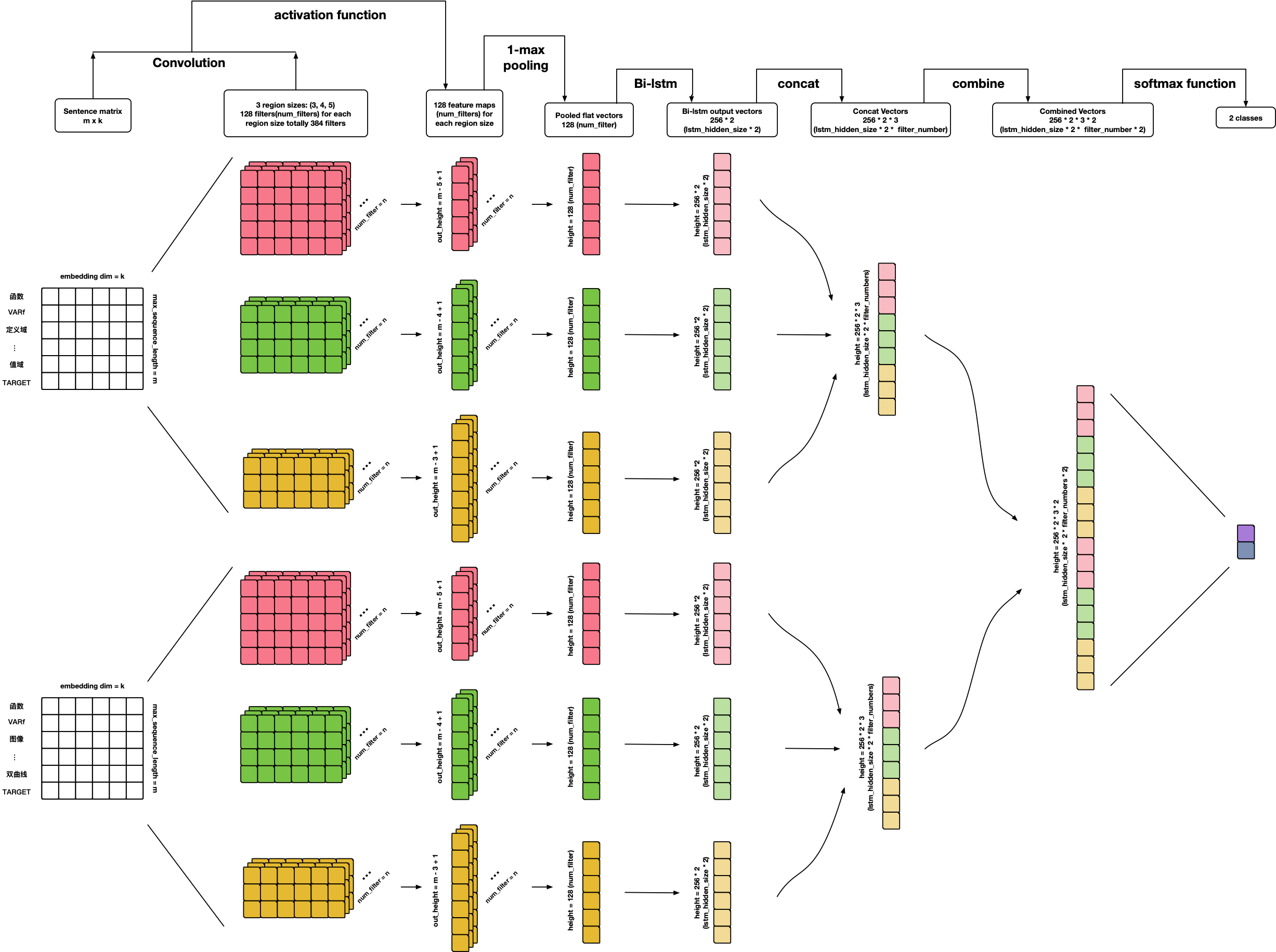
References:
- Personal ideas 🙃
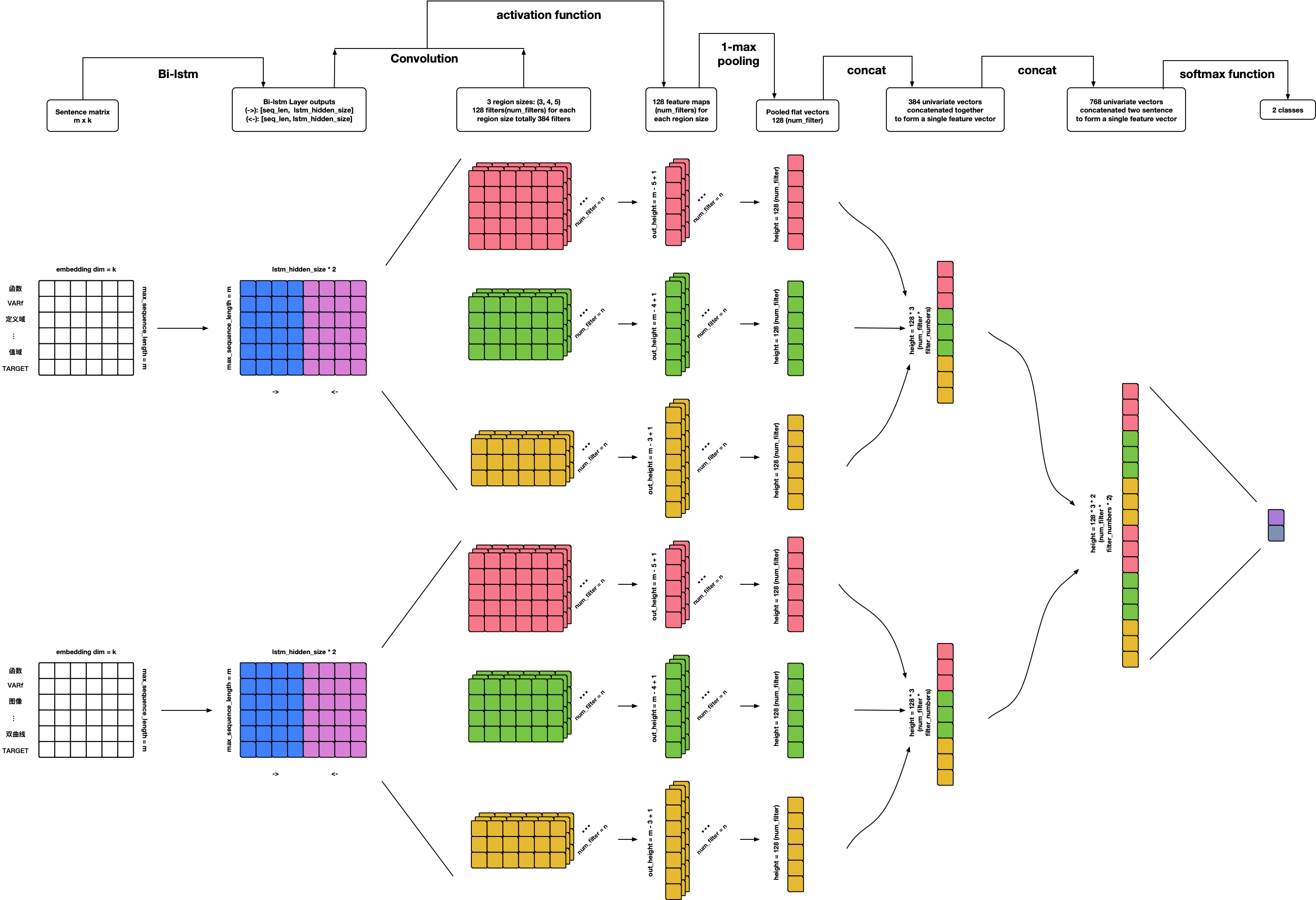
References:
- Personal ideas 🙃
References:
Warning: Model can use but not finished yet 🤪!
- Add attention penalization loss.
- Add visualization.
References:
Warning: Only achieve the ABCNN-1 Model🤪!
- Add ABCNN-3 model.
References:
黄威,Randolph
SCU SE Bachelor; USTC CS Master
Email: chinawolfman@hotmail.com
My Blog: randolph.pro
LinkedIn: randolph's linkedin