第一次参加时间序列预测比赛“京东杯2019第六届泰达创新创业挑战赛-用户对品类下店铺的购买预测”,单人排名在13左右,组队后在大佬带领下最终成绩a榜第五,b榜第七,在这进行总结,把整个建模过程进行记录。
根据用户行为数据以及各基本数据,来预测用户未来7天的购买率。
很显然,从目标来看,最终的特征还是基于不同维度的转化率(购买率)。问题难点应该在于如何构造样本(训练集和测试集),样本的构造决定了最后结果的上限。我的思路是取某段时间滑动取动态行为特征,并上长期的行为特征,对于近期和长期特征可以使用权重来做重要性区别。
提供2018-02-01到2018-04-15用户集合U中的用户,对商品集合S中部分商品的行为、评价、用户数据。
提供 2018-04-16 到 2018-04-22 预测用户U对哪些品类和店铺有购买,用户对品类下的店铺只会购买一次。
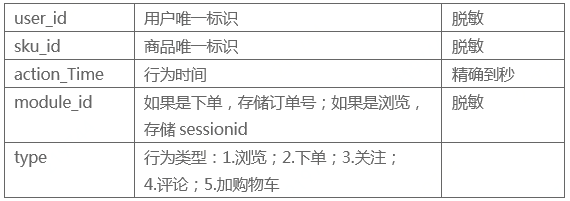
- 样本集构造:训练集2018-03-08至2018-04-08,标签为后七天是否购买,购买为1,否则为0。测试集为2018-03-15至2018-04-15.并且以用户-商品为维度进行预测。
- 窗口滑动分别根据截止日期向前推1,2,3,5,7,10,15,21,30天分别滑动取特征。对于长期特征取2018-02-01到截止日期内的特征。

可以看到数据在2月波动比较大,因为在收到春节以及春节前的年货大促影响。之后二月底到三月之后数据开始稳定。 同时327和328两天,浏览数据出现异常,不知道具体缘由。在做特征的时候需要注意。
.png)
- 蓝色表示每天的产生下单的购买数。可以发现每天的数量是稳定的。(尽管略微下降)
- B040?表示那天有行为的用户的每天的下单样本数。可以发现的是存在大量的用户是缺少历史行为的。召回率存在上限。
.png)
- 当天产生行为后,未来会购买的概率随着时间递减。符合经验。
.png)
- 蓝色为4月8日行为用户的的未来七天下单分布。橘色和绿色分别表示为最后行为日期为4月7日和4月6日的用户在未来七天的下单分布。可以看到递减迅速。所以在本场景下最终预测时直接拿最后一天(0415)的样本进行预测就取得了最优的结果。
用户对用户行为的探讨,分为三类进行建模。
- 第一类用户,发现存在只有type==2操作行为的。
- 第二类用户,有过加购物车行为的用户。在0408-0415时间段
- 第三类用户为总量用户除去前两类用户。
.png)
.png)
在建模过程中发现,第二类用户的购买转化率是最高的。只拿该部分建模可以进入前二十。第一类用户可以用规则覆盖(比如最近七天存在两次以及两次以上的购物行为等)。
- 从时间序列角度出发,该场景数据本平稳,但是受节假日影响早期存在波动。
- 数据缺失奇怪.怀疑 是主办方故意挖的坑。主要是两点。一是327,328两天浏览数据显著缺失异常。二是加入购物车行为只有408-415期间内存在。所以在数据选取时保守出发。
- 部分用户的行为,在其他表中找不到关联。该部分数据都认为脏数据处理。
- 用户-品类-最后行为时间-标签
- 日期-用户-商品sku-标签(商品 决定了 品类和标签)
- 日期-用户-品类-商店-标签
- 日期-用户-品类-标签 -> 用户-品类-商店-标签
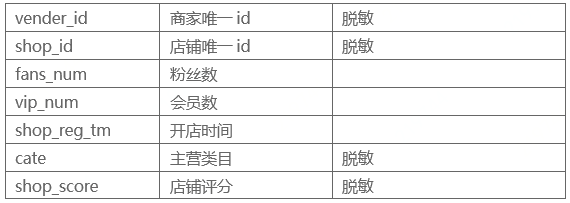
- 用户基础特征:用户注册年份,用户注册天数,年龄,性别,用户等级,城市等级,用户的地点(省份,城市,城镇)
- 商店基础特征:粉丝数,会员数,商店评分,商店注册年份和天数
同样从不同维度进行统计行为转化率。此处队里大佬对转化率进行了平滑处理,值得学习。
数量很多,举例说明: user_action1_skus_7day:用户在七天内浏览的商品(sku)数量 cate_action2_shops_7day:该品类七天内在几家商店被购买 user_cate_action5_counts_3day:用户三天内将该品类(cate)加入购物车的数量
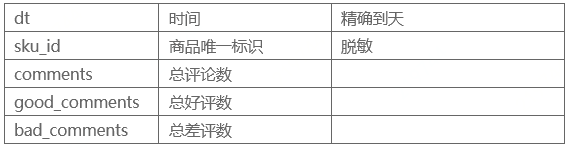
因为评论数据的粒度是sku,也就是商品,所以需要汇总到品类(cate)粒度或者商店(shop)粒度后使用,作为对品类的描述或者对该商店的描述。
- 该商店的评论数,好评数,差评数,好评率(平滑),差评率(平滑)
- 该品类的评论数,好评数,差评数,好评率(平滑),差评率(平滑)
- 该商店中该品类的评论数,好评数,差评数,好评率(平滑),差评率(平滑)
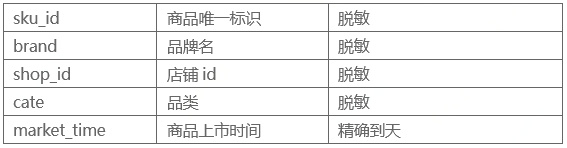
用来描述一些需要统计的店铺静态特征,比如:
- shop_cate_own_sku:该商店该品类下的商品数量。
- cate_own_skus:该品类下的商品数
- 该商店下的品类数,该品类被几家商店购买等。
对于date没有做相应特征,对于每天的time进行了切片,分为上午,下午,晚上,分别统计特征。
对于用户长期的行为特征分别从用户、商品、品类、店铺、用户-品类、用户-商铺以及用户-品类-商铺多个维度分别按天统计在不同操作类型下的操作次数,然后选取了4-15之前一个月内的数据。使用LSTM将序列特征embedding到5维。
参赛者提交的结果文件中包含对所有用户购买意向的预测结果。对每一个用户的预测结果包括两方面:
(1)该用户2018-04-16到2018-04-22是否对品类有购买,提交的结果文件中仅包含预测为下单的用户和品类(预测为未下单的用户和品类无须在结果中出现)。评测时将对提交结果中重复的“用户-品类”做排重处理,若预测正确,则评测算法中置label=1,不正确label=0。
(2)如果用户对品类有购买,还需要预测对该品类下哪个店铺有购买,若店铺预测正确,则评测算法中置pred=1,不正确pred=0。
对于参赛者提交的结果文件,按如下公式计算得分:score=0.4_F11_+0.6_F12_
此处的F1值定义为:

- 该评价指标是f1的变形。该类指标需要注意的是召回率和准确率的Trade-Off。
- 模型效果达到一定程度后,相对来说,高召回意味着低准确,高准确必然面临低召回。可以根据业务进行调整。比如想优惠更大群用户,就可以高召回下发放优惠券。