

VimTS is a unified video and image text spotter for enhancing the cross-domain generalization. It outperforms the state-of-the-art method by an average of 2.6% in six cross-domain benchmarks such as TT-to-IC15, CTW1500-to-TT, and TT-to-CTW1500. For video-level cross-domain adaption, our method even surpasses the previous end-to-end video spotting method in ICDAR2015 video and DSText v2 by an average of 5.5% on the MOTA metric, using only image-level data.

2024.5.3🚀 Code available.2024.5.1🚀 Release paper VimTS.
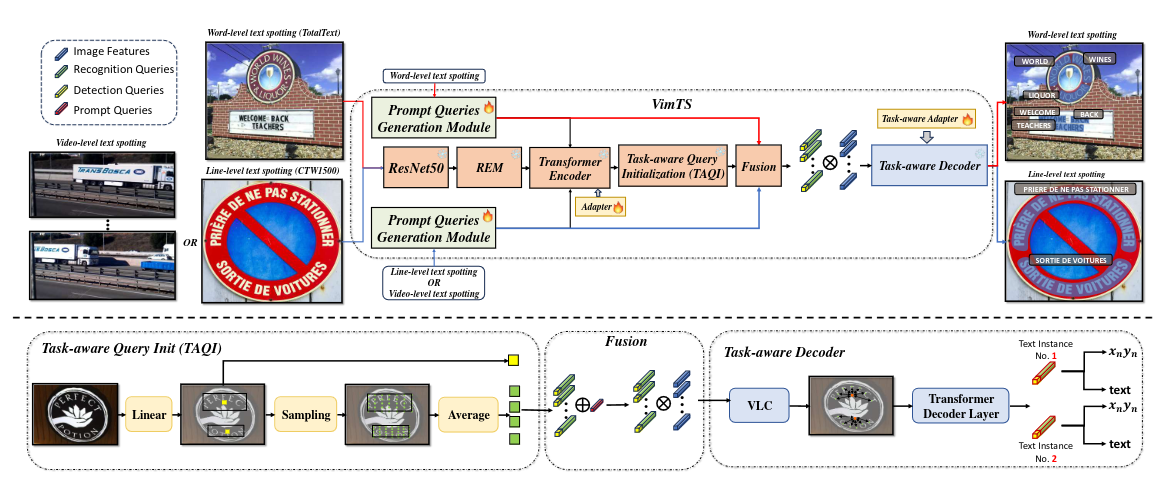
Overall framework of our method.
Overall framework of CoDeF-based synthetic method.
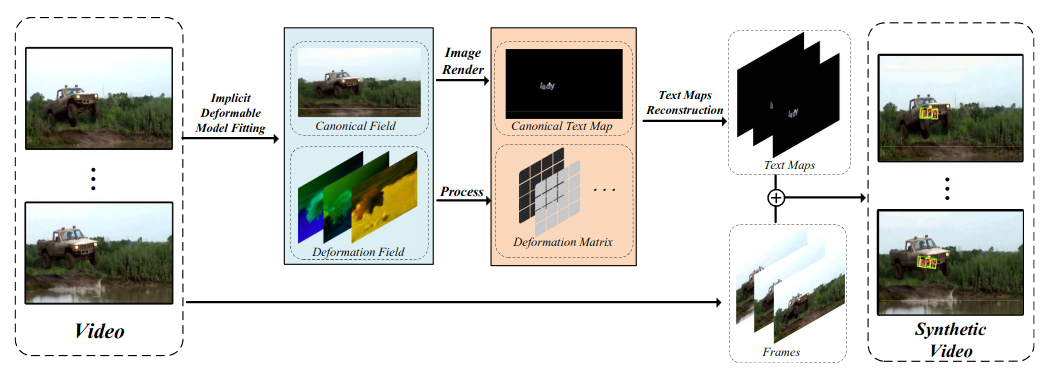
We manually collect and filter text-free, open-source and unrestricted videos from NExT-QA, Charades-Ego, Breakfast, A2D, MPI-Cooking, ActorShift and Hollywood. By utilizing the CoDeF, our synthetic method facilitates the achievement of realistic and stable text flow propagation, significantly reducing the occurrence of distortions.

Python 3.8 + PyTorch 1.10.0 + CUDA 11.3 + torchvision=0.11.0 + Detectron2 (v0.2.1) + OpenCV for visualization
conda create -n VimTS python=3.8 -y
conda activate VimTS
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=11.3 -c pytorch -c conda-forge
pip install -r requirements.txt
git clone https://github.com/Yuliang-Liu/VimTS.git
cd detectron2-0.2.1
python setup.py build develop
pip install opencv-python
cd models/vimts/ops
sh make.shPlease download TotalText, CTW1500, and ICDAR2015 according to the guide provided by SPTS v2: README.md.
Extract all the datasets and make sure you organize them as follows
- datasets
| - CTW1500
| | - annotations
| | - ctwtest_text_image
| | - ctwtrain_text_image
| - totaltext (or icdar2015)
| | - test_images
| | - train_images
| | - test.json
| | - train.json
We use 8 GPUs for training and 2 images each GPU by default.
bash scripts/multi_tasks.sh /path/to/your/dataset
Download the weight Google Drive.
0 for Text Detection; 1 for Text Spotting.
bash scripts/test.sh config/VimTS/VimTS_multi_finetune.py /path/to/your/dataset 1 /path/to/your/checkpoint /path/to/your/test_dataset
e.g.:
bash scripts/test.sh config/VimTS/VimTS_multi_finetune.py ../datasets 1 cross_domain_checkpoint.pth totaltext_val
Visualize the detection and recognition results
python vis.py
If you wish to refer to the baseline results published here, please use the following BibTeX entries:
@misc{liuvimts,
author={Liu, Yuliang and Huang, Mingxin and Yan, Hao and Deng, Linger and Wu, Weijia and Lu, Hao and Shen, Chunhua and Jin, Lianwen and Bai, Xiang},
title={VimTS: A Unified Video and Image Text Spotter for Enhancing the Cross-domain Generalization},
publisher={arXiv preprint arXiv:2404.19652},
year={2024},
}We welcome suggestions to help us improve the VimTS. For any query, please contact Prof. Yuliang Liu: ylliu@hust.edu.cn. If you find something interesting, please also feel free to share with us through email or open an issue. Thanks!