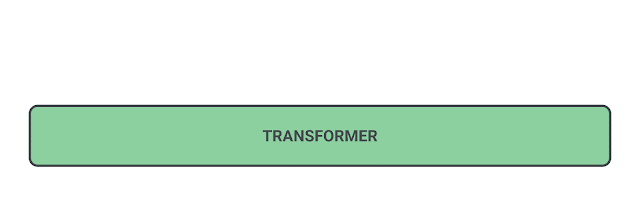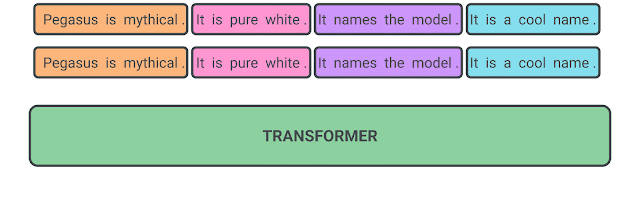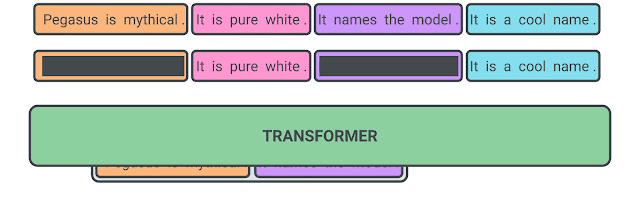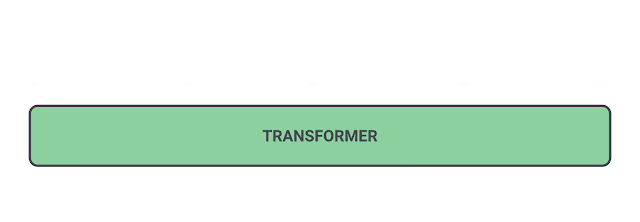
Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models, or PEGASUS, uses self-supervised objective Gap Sentences Generation (GSG) to train a transformer encoder-decoder model. The paper can be found on arXiv. ICML 2020 accepted. check code source from here.
Python 3+
tensorflow==2.2.0
sentencepiece
numpy
To run the summery, download pre-trained model on cnn_dailymail from here or gigaword from here. Unzip it and put it to model/.
python scripts/summery.py --article example_article --model_dir model/ --model_name cnn_dailymail
Two types of dataset format are supported: TensorFlow Datasets (TFDS) or TFRecords. The pn-summary dataset can be used for this purpose. pn-summary comprises numerous articles of various categories that have been crawled from six news agency websites. Each document (article) includes the long original text as well as a human-generated summary.
- Collab demo
- fine-tune on persian dataset