AI Chatbot for Moringa School

- Overview
- Business Understanding
- Business Problem
- Objectives of the Chatbot
- Data Understanding
- Exploratory Data Analysis (EDA)
- Modeling
- Evaluation
- Conclusions and Recommendations
- Deployment
Authors:
The primary objective of this project is to develop an AI chatbot for Moringa School's website. The chatbot aims to understand user queries, connect users to key information about courses and enrollment, and provide technical support for any issues faced by visitors. The chatbot will leverage Natural Language Toolkit (NLTK) for natural language processing, ensuring a comprehensive understanding of user inquiries.
The adoption of chatbots is on the rise, with the project anticipating that by the end of 2030, over 75% of customer queries will be resolved by chatbots. Companies are increasingly using chatbots to boost efficiency by automating recurring queries, providing quick customer assistance, and enhancing customer experience by reducing wait times and offering 24/7 support. In the education sector, this project falls under the category of "service-oriented chatbots," designed to answer FAQs and provide general information.
Moringa School, a learning accelerator in Nairobi, Kenya, has experienced substantial growth, training over 2000 students globally since its inception in 2014. With a goal to train over 200,000 students by 2030 and new course launches, the demand for Moringa School's services is expected to increase. The current modes of accessing Moringa services, such as visiting the website or making calls, may not efficiently cater to the growing demand. The business problem is to bridge this gap by employing a chatbot to provide fast, 24/7 service, improve customer experience, offer access to information, and provide technical support.
-
Provide Fast, 24/7 Service: The chatbot will ensure round-the-clock support, especially during peak hours, peak seasons, or for international students in different time zones, reducing wait times when human assistants are unavailable.
-
Improve Customer Experience: Welcoming users to the website and offering navigation assistance, the chatbot will enhance the overall user experience by providing efficient links to specific resources.
-
Provide Access to Information: Users can inquire about general information, such as courses offered, admission procedures, tuition fees, and events. The chatbot will provide details, schedules, and registration information for events.
-
Offer Technical Support: The chatbot will address technical issues users may face on the website, guiding them through troubleshooting steps or redirecting them to relevant resources.
-
Data Collection for Learning: As the chatbot assists users, it will collect data on user queries, frequently asked questions and areas for improvement. This data will enable the chatbot to learn, providing more accurate and personalized responses over time. The chatbot will improve its ability to discern which queries it can handle autonomously and which may require human assistance.
- Source of Data: The project obtained data by scraping Moringa School's websites, employing two Python scripts: link_scraper.py and web_scraper.py.
-
Link Scraper: Utilizes BeautifulSoup to extract hyperlinks from Moringa School's website pages, saving the links to a JSON file named scraped_links.json.
-
Web Scraper: Utilizes links from scraped_links.json to extract text content from corresponding web pages. Text data is then saved in moringa_text_corpus.json.
-
Data Files:
-
scraped_links.json: Contains unique URLs obtained during link scraping.
-
moringa_text_corpus.json: Stores text content in a structured format, associating each link with a list of unique text snippets.
Objectives:
- Thoroughly examine the dataset of intents, questions, and responses.
- Understand the distribution and nature of the data.
- Identify patterns and uncover insights to guide the AI Chatbot development.
Key Areas of Analysis:
- Diversity of intents.
- Structure and length of questions and responses.
- Common themes and word frequencies.
Intent distribution

Findings
- In the dataset, there are a total of 10 unique intents, each representing a specific category or topic.
- On average, each intent contains approximately 52.40 questions. This statistic provides insight into the typical number of questions associated with each intent.
- The median number of questions per intent is 30. This means that half of the intents have 30 or fewer questions, while the other half contains more than 30 questions. The median helps us understand the central tendency of question counts.
Question and Response Length Analysis

Findings
- The blue bars (questions) are clustered more towards the left side of the graph, indicating that most questions are shorter in length. The tallest blue bar, indicating the highest frequency, falls in the range of 0-10 words approximately.
- The red bars (responses) show a wider distribution across the word count, suggesting that responses have a more varied length. The tallest red bar is in the range of 10-20 words.
- The blue bars (questions) have a peak frequency much higher than the red bars (responses), suggesting that there is a common word count range where most questions fall.
Word Frequency Analysis

Word Cloud

Findings
- The analysis provides insights into the key themes and topics present in the dataset.
- The most common words reflect a strong emphasis on courses, data science, Moringa, and educational aspects.
- With 'course' being the most frequent word, the dataset places a substantial emphasis on educational offerings.
- 'data,' 'science,' and 'moringa' indicate a strong focus on data science education, aligning with industry and institutional themes.
- The repetition of terms like 'student,' 'develop,' and 'learn' underscores a learner-centric approach in the dataset.
Bi-grams and Tri-grams Analysis
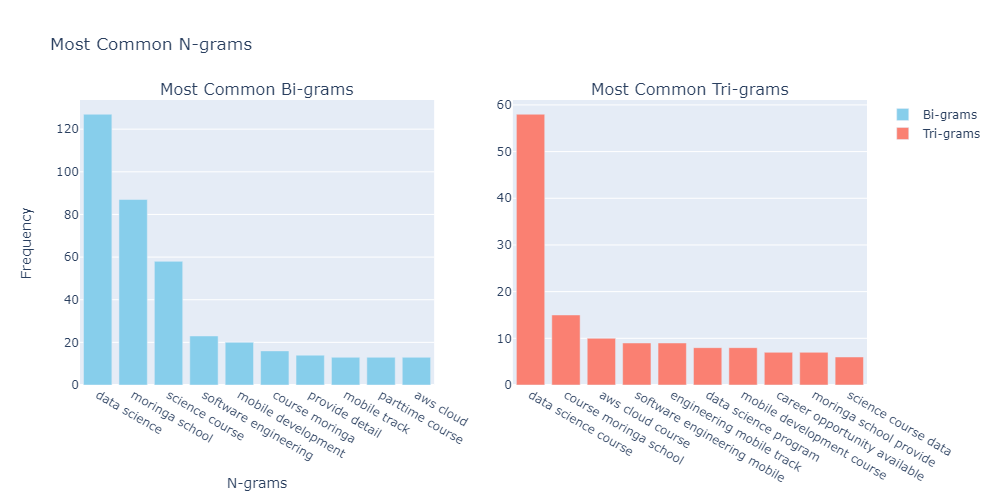

Findings
- On the left, the bi-grams bar chart shows that "data science" is the most frequent bi-gram, followed by "moringa school" and others.
- On the right, the tri-grams bar chart indicates "data science course" as the most frequent tri-gram, with a notable drop in frequency for subsequent tri-grams
Base Model Performance


Findings The base model demonstrates a high training accuracy of approximately 98%, suggesting effective learning from the training data. However, a significant performance gap is observed, with the validation accuracy plateauing at 30-40%, raising concerns about overfitting. The validation loss notably increases in later epochs, reaching around 9.8, further reinforcing overfitting concerns. To address these issues, recommendations include incorporating both questions and responses in the training data for a more comprehensive understanding, implementing regularization techniques to mitigate overfitting, and exploring performance improvement measures such as learning rate tuning and optimizing hidden layers. Additionally, testing different vectorization methods like TFIDF and embeddings is suggested, with the option to consider alternative deep learning models if necessary.
Train on both questions and responses


Findings The model exhibits notable improvement, with training accuracy at approximately 99.42% and validation accuracy at around 58.78%. Despite this progress, there is potential for further enhancement in the validation accuracy.
Regularization - Dropout regularization

 Optimize the number of hidden layers:
Optimize the number of hidden layers:


Term Frequency * Inverse Document Frequency (TFIDF) vectorization


This model is a feedforward neural network with multiple hidden layers. Here's a summary of its architecture and training performance:
-
Architecture:
- Input Layer:
- Dense layer with 128 neurons, using the hyperbolic tangent (tanh) activation function. Regularized with L2 regularization with a regularization parameter of 0.01.
- Dropout layer with a dropout rate of 0.8 to prevent overfitting.
- Hidden Layers:
- Dense layer with 64 neurons, using the tanh activation function.
- Dropout layer with a dropout rate of 0.5.
- Dense layer with 150 neurons, using the tanh activation function.
- Dropout layer with a dropout rate of 0.5.
- Output Layer:
- Dense layer with the number of neurons equal to the number of classes (output categories), using the softmax activation function.
- Model is compiled with categorical cross-entropy loss function and Stochastic Gradient Descent (SGD) optimizer with a learning rate of 0.001, momentum of 0.9, and Nesterov momentum.
- Input Layer:
-
Training Performance:
- The model is trained for 250 epochs with a batch size of 5.
- Throughout training, the loss decreases steadily, indicating that the model is learning to make better predictions.
- The accuracy on the training data reaches around 91-93%, while the accuracy on the validation data is consistently high, around 92-96%, indicating that the model generalizes well to unseen data.
Overall, this model seems to perform well, achieving high accuracy on both the training and validation sets. The dropout layers help prevent overfitting, and the regularization helps control the model's complexity. However, it's essential to evaluate the model's performance on unseen test data to assess its generalization ability accurately.
Based on the analysis and models developed, here are the conclusions and recommendations:
-
Intent Classification:
- The intent classification model achieved good performance, accurately categorizing user queries into predefined intent categories. This model can effectively route user queries to appropriate response handlers or workflows.
-
Response Generation:
- The response generation system, utilizing cosine similarity with TF-IDF vectors, showed promising results in mapping user queries to appropriate responses. However, there is room for improvement, particularly in handling context and generating more diverse and contextually relevant responses.
-
Model Evaluation:
- Model performance evaluation revealed high accuracy and generalization ability, indicating that the models can effectively handle a wide range of user queries. However, continuous monitoring and evaluation are necessary to ensure consistent performance over time.
-
Continuous Learning and Adaptation:
- Implement mechanisms for continuous learning and adaptation, allowing the chatbot to evolve over time based on user feedback, new data, and changing requirements.
- Monitor performance metrics and user satisfaction to measure the effectiveness of the chatbot and identify areas for enhancement.
By addressing these recommendations and focusing on continuous improvement, the chatbot AI system can deliver a more engaging, personalized, and effective user experience, ultimately enhancing user satisfaction and achieving the desired business outcomes.
This model was deployed using the following technologies:
- Flask: We used flask to expose the necessary APIs needed for the chatbot like:
/vectorize: this API endpoint vectorizes the user input./response: this API endpoint fetches a response using Cosine Similarity depending on thetagprediction.
- ReactJS: This was used to create the front-end of the app, i.e the web UI.
- TensorFlow JS: This was used to deserialize our model and enable it to be used on the front-end (this was used because
Streamlitdoesn't allow one to use a custom user-interface).
📦
├─ .gitignore
├─ .ipynb_checkpoints
│ ├─ index-checkpoint.ipynb
│ └─ moringa-checkpoint.txt
├─ Deployment
│ ├─ __init__.py
│ ├─ app.py
│ ├─ chatbot
│ ├─ config.py
│ ├─ pickles
│ ├─ requirements.txt
│ ├─ utils.py
│ └─ wsgi.py
├─ Final_Intents.json
├─ LICENSE
├─ Moringa_Chatbot_Slides.pdf
├─ README.md
├─ chunk_files**
├─ images
├─ index.ipynb
├─ moringa.txt
└─ moringa_scraper
├─ .ipynb_checkpoints
│ ├─ moringa_text_corpus-checkpoint.json
│ └─ web_scraper-checkpoint.py
├─ __init__.py
├─ link_scraper.py
├─ moringa_text_corpus.json
├─ scraped_links.json
└─ web_scraper.py
©generated by Project Tree Generator
This project is licensed under the MIT License - see the LICENSE file for details.