搭建一个学术论文的综合搜索引擎,用户可以检索到一篇论文的综合信息,不仅有pdf文件,还有oral视频,数据集,源代码等多模态信息。
本项目为综合搜索引擎的检索模块,从MongoDB中读取爬虫爬到的数据,建立索引,实现综合检索,包括全文检索、字段检索、视频检索等功能。
Low-LevelMasterDoSearch
底层研究生也能做检索。
| 姓名 | 学号 | 分工 |
|---|---|---|
| @Zhu** | ---------- | 数据处理 |
| @Xiong** | ---------- | 数据字段协商/ES维护/PDF抽取 |
| @He** | ---------- | 视频定位/封装Python包 |
| @Yao** | ---------- | 视频字幕提取 |
| @Cheng** | ---------- | 基本检索 |
| @Li** | ---------- | 检索优化 |
| @Sun** | ---------- | 字幕翻译 |
- 支持“综合检索”和“高级检索”两种方式
- 支持不同检索字段的组合
- 支持按年份,引用量,相关性等多种排序方式
- 支持筛选论文发表时间及设置不同检索字段优先级(按顺序)
| 检索方式 | 检索字段组合 | 多种排序方式 | 多种筛选方式 | 设置检索字段优先级 |
|---|---|---|---|---|
| 综合检索 | ✔ | ✔ | ✔ | ✔ |
| 高级检索 | ✔ | ✔ | ✔ |
视频字幕信息也可以作为论文的检索依据:
- 支持定位到匹配视频的具体时间段
- 支持根据论文内容或ID等多种视频检索方式
- 使用BERT优化句子相似度计算,并封装成服务以提高检索速度
| 检索方式 | 获取论文视频 | 获取含关键字的视频 | 指定视频关键字定位 |
|---|---|---|---|
| 视频检索 | ✔ | ✔ | ✔ |
- 支持先过滤再排序,优化检索速度
- 支持根据不同指标进行重排序,优化检索质量
- 支持根据不同指标综合排序,提高检索多样性
-
数据库版本:
MongoDB 3.6.21
ElasticSearch 5.0.0
-
提供给系统展示模块的Python包版本:
mdsearch 0.0.9
search-low-levelmasterdosearch
├─ .gitignore
├─ data 数据定义与处理
│ ├─ mongoDB.json MongoDB数据字段
│ └─ esIndex.json ElasticSearch数据字段
├─ pdfToJson PDF解析模块
│ ├─ requirements.txt
│ ├─ client.py
│ ├─ pdfClient.py PDF处理客户端
│ ├─ config.json GROBID参数
│ ├─ xmlToJson.py XML解析代码
│ ├─ example.json 示例JSON输出
│ ├─ example.pdf 示例PDF输入
│ └─ run.py 示例运行代码
├─ searcher 检索模块
│ ├─ Similarity 语义相似度计算
│ ├─ _init_.py
│ ├─ sentence_similarity.py
│ ├─ similarity_server.py
│ └─ similarity_test.py
│ └─ searcher.py 检索功能代码
├─ videoContent 视频字幕解析模块
│ ├─ requirements.txt
│ ├─ videoContent.py 视频字幕提取、翻译及词向量计算
│ ├─ eng2chn.py
│ ├─ speech2txt.py
│ └─ textEmbedding.py
├─ README.md
└─ test.py 测试样例
pip install mdsearch如果已将下载源替换为镜像源,请输入如下命令:
pip install mdsearch -i https://pypi.org/simple
整体流程为通过search_info封装用户的查询内容,然后调用相关API返回检索结果。
-
初始化
from mdsearch import Searcher S = Searcher(index_name='paperdb', doc_type='papers')
-
构造search_info
综合检索:
search_info = { 'query_type': 'integrated_search', 'query': string, # 用户查询的内容 'match': { 'title': bool, # True/False表示是否检索这个字段的内容 'abstract': bool, 'paperContent': bool, 'videoContent': bool, 'authors': bool, }, 'filter': { 'yearfrom': 1000, # paper的年份限制 'yearbefore': 3000, }, 'sort': 'relevance', # 排序方式:year/cited/relevance 'is_filter': False, # 是否先过滤后排序,建议True,提升检索效率 'is_rescore': False, # 是否采用重排序,依据relevance排序时建议True,增强排序效果 'is_cited': False # 是否使用引用量参与排序,由于未爬取引用量字段,只能为False }
高级检索:
search_info_2 = { 'query_type': 'advanced_search', 'match': { 'title': string, # 用户查询内容 'abstract': string, # 若不含有某项,设置成 None 'paperContent': string, 'videoContent': string, 'authors': string, }, 'filter': { 'yearfrom': 1000, 'yearbefore': 3000, }, 'sort': 'year', 'is_filter': False, # 高级检索无论True还是False都不会进行过滤 'is_rescore': False, 'is_cited': False }
-
根据search_info检索论文
paper, paper_id, paper_num = S.search_paper_by_name(search_info)
返回结果说明: paper_num : A int number of paper. paper_id : A list of string, each string means paper id. paper : A list of dicts, each dict stores information of a paper. -
检索单个论文视频中的相关内容(可通过前一步检索论文返回的paper_id或者paper,注意是单个)
video_pos = S.get_video_pos_by_paper_id(search_info, paper_id) video_pos = S.get_video_pos_by_paper(search_info, paper)
文献数据保存在paperdb.papers中,一篇文献的存储字段如下:
{
"_id": "deeprewiringtrainingverysparsedeepnetworks",
"arxiv_id": "arXiv:1711.05136",
"title": "Deep Rewiring: Training very sparse deep networks",
"authors": [{
"firstName": "Guillaume",
"lastName": "Bellec"
},
{
"firstName": "David",
"lastName": "Kappel"
},
{
"firstName": "Wolfgang",
"lastName": "Maass"
},
{
"firstName": "Robert",
"lastName": "Legenstein"
}
],
"year": "2017",
"publisher": "arXiv",
"cited": "11",
"keywords": ["keyword1", "keyword2"],
"abstract": "Neuromorphic hardware tends to pose limits on the connectivity of deepnetworks that one can run on them. But also generic hardware and ...",
"subjects": "Neural and Evolutionary Computing (cs.NE)",
"paperUrl": "https://arxiv.org/pdf/1711.05136",
"paperPdfUrl": "https://arxiv.org/pdf/1711.05136.pdf#pdfjs.action=download",
"paperPath": "/home/work/crawler/paper/deeprewiringtrainingverysparsedeepnetworks.pdf",
"paperContent": {
"text": "Network connectivity is one of the main determinants for whether a neural network can be efficiently implemented in hardware or ...",
"subtitles": [
"1 INTRODUCTION",
"2 REWIRING IN DEEP NEURAL NETWORKS",
"3 EXPERIMENTS",
"4 CONVERGENCE PROPERTIES OF DEEP R AND SOFT-DEEP R",
"5 DISCUSSION"
],
"subtexts": [
["paragraph 1.1", "paragraph 1.2"],
["paragraph 2.1", "paragraph 2.2", "paragraph 2.3"],
["paragraph 3.1", "paragraph 3.2"],
["paragraph 4.1", "paragraph 4.2", "paragraph 4.3"],
["paragraph 5.1", "paragraph 5.2"]
]
},
"references": [{
"refTitle": "Fine-grained analysis of sentence embeddings using auxiliary prediction tasks",
"refAuthors": [{
"firstName": "Yossi",
"lastName": "Adi"
},
{
"firstName": "Einat",
"lastName": "Kermany"
},
{
"firstName": "Yonatan",
"lastName": "Belinkov"
},
{
"firstName": "Ofer",
"lastName": "Lavi"
},
{
"firstName": "Yoav",
"lastName": "Goldberg"
}
],
"refYear": "2017",
"refPublisher": ""
}],
"videoUrl": "https://...",
"videoContent": {
"startTime": ["time1", "time3", "time5"],
"endTime": ["time2", "time4", "time6"],
"textEmbedding": ["vector1", "vector2", "vector3"],
"textEnglish": ["haha", "hehe", "heihei"],
"textChinese": ["哈哈", "呵呵", "嘿嘿"]
},
"codeUrl": "https://...",
"datasetUrl": "https://..."
}| 字段 | 类型 | 说明 | 是否为集合 | 是否索引 |
|---|---|---|---|---|
| title | text | 文献标题 | × | √ |
| authors | nested | 文献作者 | √ | √ |
| firstName | keyword | 作者名 | × | √ |
| lastName | keyword | 作者姓 | × | √ |
| year | keyword | 文献发表年份(YYYY格式) | × | √ |
| publisher | keyword | 文献发表期刊 | × | √ |
| cited | integer | 文献被引用次数 | × | × |
| keywords | keyword | 关键词 | √ | √ |
| abstract | text | 文献摘要 | × | √ |
| subjects | keyword | 文献所属类别 | √ | √ |
| paperUrl | keyword | 文献链接 | × | × |
| paperPdfUrl | keyword | 文献下载链接 | × | × |
| paperPath | keyword | 文献在本地的位置 | × | × |
| paperContent | nested | 文献正文内容 | × | √ |
| text | text | 文献正文 | × | √ |
| subtitles | text | 段落标题 | √ | √ |
| subtexts | text | 段落内容 | √ | √ |
| references | nested | 引用 | × | √ |
| refTitle | text | 被引用文献的标题 | × | √ |
| refAuthors | nested | 被引用文献的作者 | √ | √ |
| refYear | keyword | 被引用文献的发表年份 | × | √ |
| refPublisher | keyword | 被引用文献的发表期刊 | × | √ |
| videoUrl | keyword | 视频链接 | × | × |
| videoPath | keyword | 视频在本地的位置 | × | × |
| videoContent | nested | 视频内容 | × | √ |
| startTime | keyword | 每句字幕起始时间 | √ | × |
| endTime | keyword | 每句字幕结束时间 | √ | × |
| textEmbedding | keyword | 单句字幕向量 | √ | × |
| textEnglish | text | 单句字幕(英文) | √ | √ |
| textChinese | text | 单句字幕(中文) | √ | × |
| codeUrl | keyword | 代码链接 | × | × |
| datasetUrl | keyword | 数据集链接 | × | × |
-
ElasticSearch中每条数据以JSON格式存储。这意味着除了_id,其他用户自定义的字段都可以“不存在”,上述例子中的存储字段是最完整的版本。
-
当字段类型为
text时,它会被分词以支持全文检索。而当字段类型为keyword时,它会按照精确值进行过滤、排序、聚合等操作。 -
当字段的
index设为false时,表示不支持检索,通常用于网页链接。 -
title字段支持“部分匹配”的检索。这意味着即使不输入完整的单词,也能匹配到相关数据。例如可以用前缀"integra"检索到文献"Integration of Leaky-Integrate-and-Fire-Neurons in Deep Learning Architectures"。 -
nested类型的字段支持嵌套检索,例如可以用"match": { "authors.last": "Ji" }检索所有姓Ji的作者。
检索模块实现的功能见功能特色部分。
展示端通过构造search_info,实现对不同字段的检索,并按指定优先级、排序方式返回检索结果,参考代码调用。综合检索和高级检索的query_type分别是integrated_search和advanced_search。当检索到某篇包含视频的论文后,还可以进一步定位视频字幕信息。
| 功能 | 函数名 | 输入 | 输出 |
|---|---|---|---|
| 检索论文 | search_paper_by_name | search_info | paper, paper_id, paper_num |
| 获取论文视频字幕信息 | get_video_pos_by_paper_id | search_info, paper_id | video_pos |
-
使用综合检索,搜索标题为Attention Is All You Need的文献:
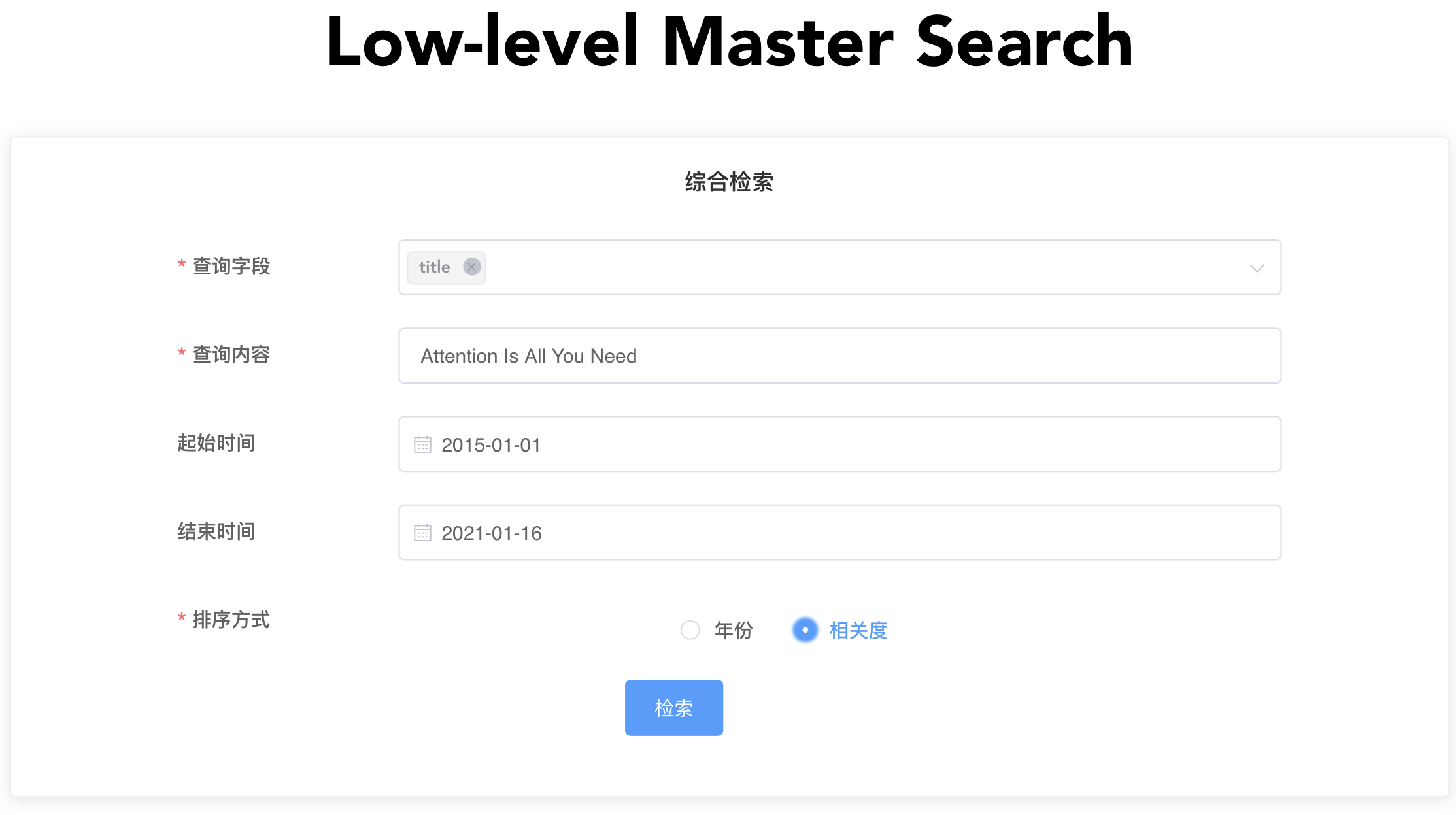
-
构造search_info:
search_info = { 'query_type': 'integrated_search', 'query': 'Attention Is All You Need', 'match': { 'title': True, 'abstract': False, 'paperContent': False, 'videoContent': False, 'authors': False }, 'filter': { 'yearfrom': 1000, 'yearbefore': 3000, }, 'sort': 'relevance', 'is_filter': False, 'is_rescore': False, 'is_cited': False }
-
调用search_paper_by_name函数
paper, paper_id, paper_num = S.search_paper_by_name(search_info)
-
Top10检索结果的标题如下图:

-
-
使用高级检索,搜索标题包含attention且作者名为Ashish的文献:
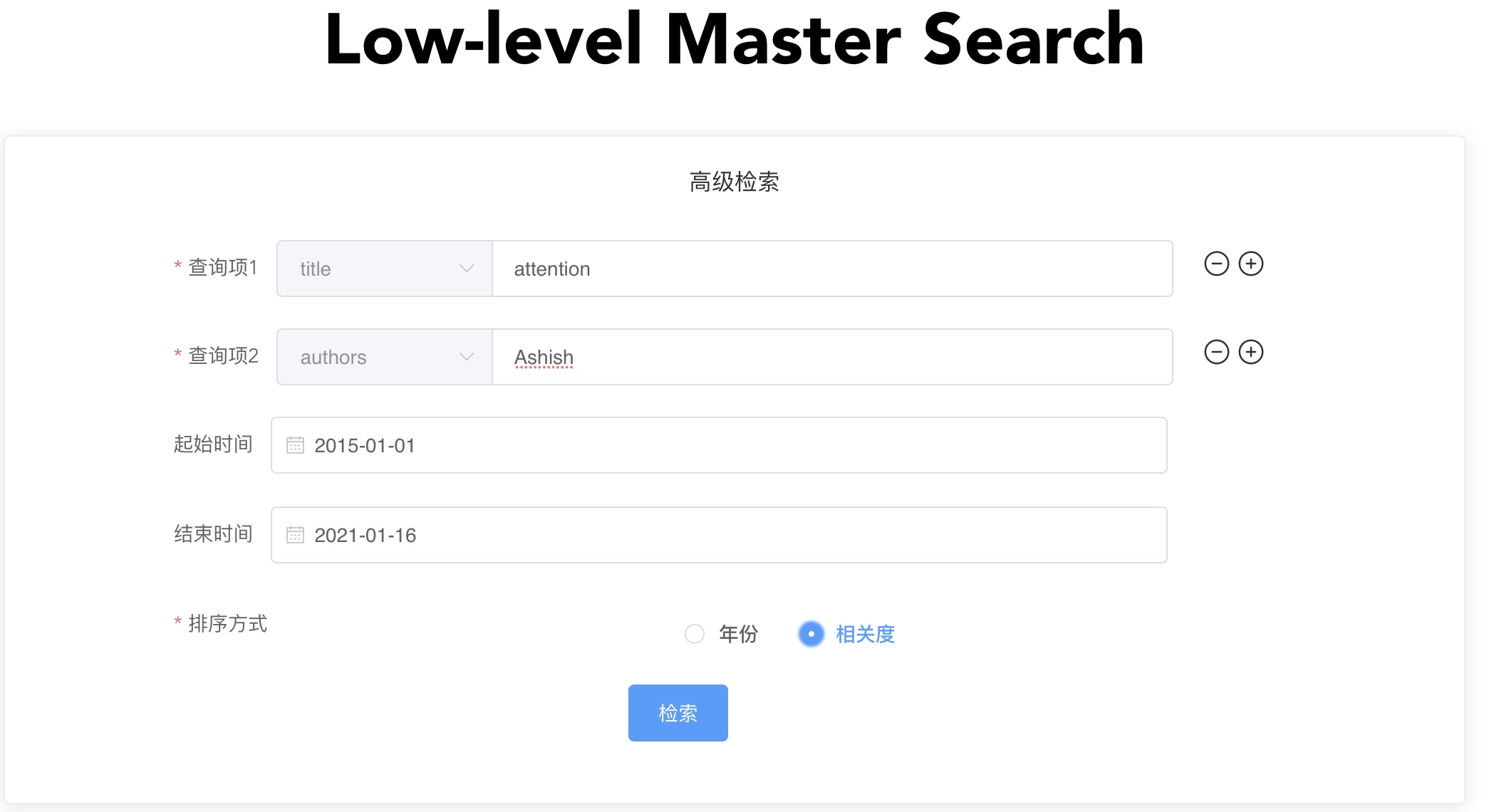
-
构造search_info_2:
search_info_2 = { 'query_type': 'advanced_search', 'match': { 'title': 'attention', 'abstract': None, 'paperContent': None, 'videoContent': None, 'authors': "Ashish" }, 'filter': { 'yearfrom': 1000, 'yearbefore': 3000, }, 'sort': 'relevance', 'is_filter': False, 'is_rescore': False, 'is_cited': False }
-
调用search_paper_by_name函数:
paper, paper_id, paper_num = S.search_paper_by_name(search_info_2)
-
Top10检索结果的标题如下图:

-
-
使用视频定位,在给定论文(已知论文ID)中搜索所有与dialog相关的视频定位:
-
构造search_info,并设置p_id为已知论文的ID
search_info = { 'query_type': 'integrated_search', 'query': 'dialog', 'match': { 'title': True, 'abstract': True, 'paperContent': True, 'videoContent': True, }, 'filter': { 'yearfrom': 1000, 'yearbefore': 3000, }, # 'sort': 'relevance', 'sort': 'year', 'is_filter': False, 'is_rescore': False, 'is_cited': False } p_id = 'semisuperviseddialoguepolicylearningviastochasticrewardestimation' # 在实际应用中p_id是已知的
-
调用get_video_pos_by_paper_id函数:
video_pos = S.get_video_pos_by_paper_id(search_info, p_id)
-
检索结果如下图:

-





文本解析模块的作用是从下载到本地的PDF文件中抽取结构化数据,以JSON格式保存,供检索使用。该模块主要分为以下两部分:
- PDF转XML:GROBID是一个机器学习库,用于将原始文档(如PDF)提取、解析和重新构造为结构化XML/TEI编码的文档。在服务器安装并运行GROBID Server后,向指定
ip:port提交PDF文档后,可以返回XML文档。 - XML转JSON:
xmlToJson.py文件封装了从XML文档中抽取信息,重新构造为JSON格式数据的功能。
从一篇文献的PDF中抽取得到的JSON数据如下:
{
"title": "title of a paper",
"authors": [
{
"firstName": "firstName of an author",
"lastName": "lastName of an author "
}
],
"keywords":["keyword1","keyword2"],
"abstract": "abstract of a paper",
"paperContent":{
"text": "all content of a paper (This is also a concatenation of subtexts)",
"subtitles": [
"1 INTRODUCTION",
"2 REWIRING IN DEEP NEURAL NETWORKS",
"3 EXPERIMENTS",
"4 CONVERGENCE PROPERTIES OF DEEP R AND SOFT-DEEP R",
"5 DISCUSSION"
],
"subtexts":[
["paragraph 1.1", "paragraph 1.2"],
["paragraph 2.1", "paragraph 2.2", "paragraph 2.3"],
["paragraph 3.1", "paragraph 3.2"],
["paragraph 4.1", "paragraph 4.2", "paragraph 4.3"],
["paragraph 5.1", "paragraph 5.2"],
]
},
"references":[
{
"refTitle": "title of a reference paper",
"refAuthors": [
{
"firstName": "firstName of an author",
"lastName": "lastName of an author "
}
],
"refYear": "publised year of a reference paper",
}
]
}-
安装依赖包
pip install -r requirements.txt
-
从
pdfClient.py文件中引用grobid_clientfrom pdfClient import grobid_client
-
初始化一个PDF处理客户端实例,可以通过config文件修改GROBID Server处理PDF的参数
pdfClient = grobid_client(config_path = config_path)
-
向
process_pdf函数传入待处理的PDF文件路径,输出JSON格式的结构化数据jsonData = pdfClient.process_pdf(pdf_path)
视频解析模块的作用是将爬虫组提供的论文讲解视频中的语音,识别为文字,并记录每段文字在视频中出现的时间段,并对英文字幕进行翻译,得到中英文双语字幕信息,此外,还需要计算字幕的Embedding词向量,以JSON格式进行存储,供视频检索定位模块使用。该模块主要分为以下三部分:
- 视频字幕抽取:使用ffmpeg及百度api等完成视频到文字的转换,并记录出现时间,即抽取字幕。
- 视频字幕翻译:调用baidu和google的api,将第一步得到的字幕进行翻译,得到双语字幕。
- 字幕词向量计算:使用BERT模型计算第一步得到字幕的词向量,用于后续检索功能中的相似度计算。
对一段视频的字幕抽取结果JSON化格式如下:
{
"_id": "paperid",
"videoContent": [
{
"startTime": "00:00:04:276",
"endTime": "00:00:04:759",
"textEnglish": "hello",
"textEmbedding": "[0.15500609576702118, 0.09710085391998291,.]",
"textChinese": "你好"
},
{
"startTime": "00:00:05:276",
"endTime": "00:00:05:759",
"textEnglish": "sentences",
"textEmbedding": "[embedding...]",
"textChinese": "translation"
}
]
}-
主函数
def get_videoContent( path: str ) -> List[Dict]
-
Parameters
-
path:
str待解析视频路径
-
-
Returns
-
video_list:
List[Dict]视频解析结果列表
-
-
-
视频字幕提取
class Subtitle(object): def __init__( self, path: str ) def return_subtitle( self ) -> List[str], List[str], List[str], str
-
Parameters
-
path:
str待解析视频路径
-
-
Returns
-
startTime:
List[str]字幕开始时间列表
-
endTime:
List[str]字幕结束时间列表
-
videoTextEnglish:
List[str]字幕抽取文本列表
-
allTextEnglish:
str字幕抽取总文本
-
-
-
视频字幕翻译
class Translation(object): def __init__( self, english_list: List[str], site: str = "baidu" ) def parse_chinese( self ) -> List[str], str
-
Parameters
-
english_list:
List[str]待翻译字幕列表
-
site:
str, optional (default = "baidu")翻译接口,默认值为"baidu",可选["google", "baidu"]
-
-
Returns
-
videoTextChinese:
List[str]翻译列表
-
allTextChinese:
str翻译总文本
-
-
-
字幕词向量计算
class Embedding(object): def __init__( self ) def text_embedding( self, sentences: str ) -> List[str]
-
Parameters
-
sentences:
str待计算词向量的字幕文本
-
-
Returns
-
embedding_list:
List[str]字幕文本的词向量表示
-
-
-
安装依赖包
pip install -r requirements.txt
-
实例化
Subtitle,通过return_subtitle()获取英文字幕信息S = Subtitle(path) startTime, endTime, videoTextEnglish, allTextEnglish = S.return_subtitle()
-
实例化
Translation,通过parse_chinese()翻译为中文字幕信息T = Translation(videoTextEnglish, site="baidu") videoTextChinese, allTextChinese = T.parse_chinese()
-
实例化
Embedding,通过text_embedding()获取字幕embeddingE = Embedding() embeddings = E.text_embedding(videoTextEnglish)
-
运行
videoContent.py文件python videoContent.py
支持万亿级别海量数据检索功能。
万级数据综合检索与高级检索平均耗时约0.09秒。
文本解析模块和视频解析模块是检索端和爬虫端交叉的部分:
- 如果检索端动态处理PDF和视频,则检索端需要具备“得知爬虫端获取了新的PDF或视频”的能力。要么由爬虫端不断通知检索端,要么由检索端不断扫描数据库中已有的数据。且检索端需要将解析后的结构化数据插入数据库,那么爬虫端和检索端都会对数据库有所操作,同步可能出错,过程也不够自然。
- 如果检索端在爬取结束后,一次性地同步已有数据并解析所有的PDF和视频,那么就不能与增量式爬取的爬虫端联动,也不方便并行开发。
因此,本项目采取的策略是将文本解析模块和视频解析模块打包,供爬虫端调用,爬取的数据和解析的数据都插入MongoDB数据库,再同步到ElasticSearch数据库供检索使用。
我们需要为MongoDB中数据库创建replica set
-
启动服务
mongod --dbpath <dbpath> --logpath <logpath> --port <port> --bind_ip_all --fork --replSet rs0
-
进入对应数据库,输入初始化命令
./mongo <ip:port> use <db> rs.initiate()返回OK=1,表示成功创建
-
安装相关包
pip install mongo-connector[elastic5] pip install elastic2-doc-manager[elastic5]
-
使用同步命令
mongo-connector -m <ip1>:<port1> -t <ip2>:<port2> -d elastic2_doc_manager -n lowermaster.crawler -g paperdb.papers
- -m:MongoDB的IP地址和端口
- -t:ElasticSearch的IP地址和端口
- -n:MongoDB中数据库名称
- -g:ElasticSearch中数据库名称
展示模块用pip安装的Python包,在代码中import包中的函数和类,即可实现检索模块提供的所有功能。
pip install mdsearch如果已将下载源替换为镜像源,请输入如下命令:
pip install mdsearch -i https://pypi.org/simple详细内容请查阅代码调用