在线测试和预览(转换成JSON);当前最新版为 2019文件夹 内的2018.190827版数据,此数据发布于统计局2019-01-31、民政部2019-08-27。
可直接打开2019/采集到的数据文件夹内的文件来使用:
- ok_data_level3.csv: 省市区3级数据。
ok_data_level4.csv: 省市区镇4级数据。ok_geo.csv.7z: 为省市区3级的坐标和行政区域边界范围数据,csv格式,解压后130M+。
csv格式非常方便解析成其他格式,算是比较通用;如果在使用csv文件过程中出现乱码、错乱等情况,需自行调对utf-8(带BOM)编码(或者使用文本编辑器
如 notepad++把文件转成需要的编码),文本限定符为"。csv文件导入数据库如果接触的比较多应该能很快能完成导入,坐标和边界可参考2019/map_geo_格式化.js 中SQL Server的导入流程。
温馨建议:不要在没有动态更新机制的情况下把数据嵌入到Android、IOS、等安装包内;缓存数据应定期从服务器拉取更新
注:本库最高采集省市区镇4级数据、省市区3级边界范围,如果需要街道5级数据、或者更高精度的边界范围,请参考底下的其他资源。
-
国家统计局 > 统计数据 > 统计标准 > 统计用区划和城乡划分代码,此为主要数据源
-
民政部 > 民政数据 > 行政区划代码,此数据源用来补全统计局的滞后不足
-
高德地图坐标和行政区域边界范围
chrome 控制台,Chrome 41这版本蛮好,win7能用,Chrome 46这版本win10能用;新版本Chrome 72+乱码(统计局内页编码为gb2312,新版本xhr对编码反而支持的超级不友好,估计是印度阿三干的)、SwitchyOmega代理没有效果、各种问题(简单制作chrome便携版实现多版本共存)。
乱码的根本原因在于统计局服务器响应的内容编码为gb2312,但服务器响应头只给了Content-Type: text/html,因此可用Fiddler篡改Content-Type响应头为Content-Type: text/html; charset=gb2312也可解决新版Chrome乱码问题。
- 2019文件夹采集了4层,省、市、区、镇,2018.190827版数据;省市区3级额外合并了民政部2019-08-27数据。采集高德省市区三级坐标和行政区域边界范围。
- 2018文件夹采集了3层,省、市、区,2017版数据。
- 2017文件夹采集了3层,省、市、区,2016版数据。
- 2013文件夹采集了4层,省、市、区、镇,2013版数据。
省市区镇数据表。
| 字段 | 描述 |
|---|---|
| id | 统计局的编号经过去除后缀的0{3,6,8}得到的短编号;如果是添加的港澳台等数据,此编号为自定义编号 |
| pid | 上级ID |
| deep | 层级深度,0:省,1:市,2:区,3:镇 |
| name | 城市名称,为统计局的名称精简过后的 |
| pinyin_prefix | name的拼音前缀,取的是pinyin第一个字母;用来排序时应当先根据拼音前缀排序,相同的再根据名称排序 |
| pinyin | name的完整拼音 |
| ext_id | 统计局原始的编号;如果是添加的港澳台等数据,此编号为0 |
| ext_name | 原始名称,为未精简的名称 |
此表为坐标和行政区域边界范围数据表,因为数据文件过大(130M+),所以分开存储。由于边界数据的解析比较复杂,请参考2019/map_geo_格式化.js内的SQL Server的解析语句。
| 字段 | 描述 |
|---|---|
| id | 和ok_data表中的ID相同,通过这个ID关联到省市区具体数据,map_geo_格式化.js中有数据合并SQL语句 |
| geo | 城市中心坐标,高德地图GCJ-02火星坐标系。格式:"lng lat" or "EMPTY",少量的EMPTY代表此城市没有抓取到坐标信息 |
| polygon | 行政区域边界,高德地图GCJ-02火星坐标系。格式:"lng lat,...;lng lat,..." or "EMPTY",少量的EMPTY代表此城市没有抓取到边界信息;存在多个地块时用;分隔,每个地块的坐标点用,分隔,特别要注意:多个地块组合在一起可能是MULTIPOLYGON或者POLYGON,需用工具进行计算和对数据进行验证 |
欢迎加QQ群:484560085,纯小写口令:areacity

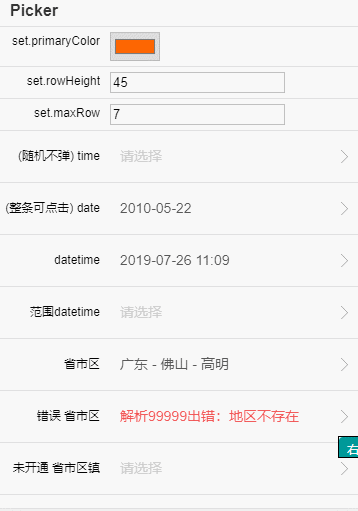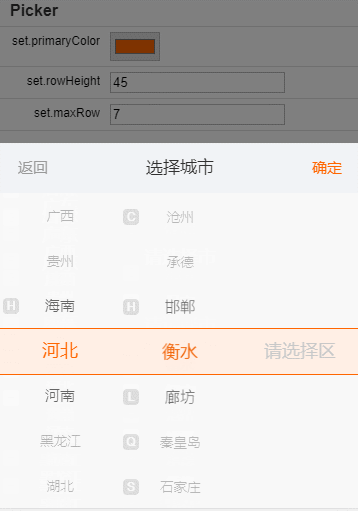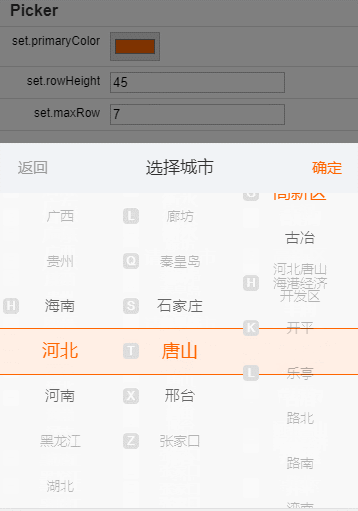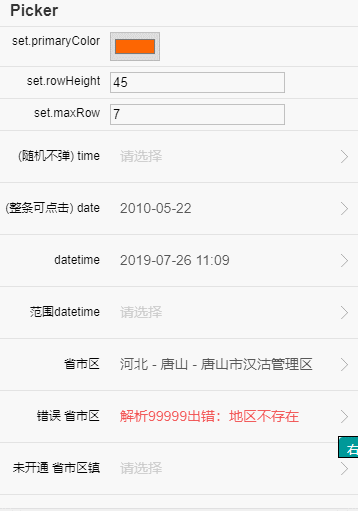
在线测试工具地址:https://xiangyuecn.github.io/AreaCity-JsSpider-StatsGov/
或者直接使用测试和WEB数据格式转换工具.js,在任意网页控制台中使用。
此工具主要用于把csv数据转换成别的格式,另外提供省市区多级联动测试,并且可生成js源码(含数据)下载,3级联动生成的文件紧凑版68kb,4级联动紧凑版1mb大小。
- 数据预览和测试。
- 将csv数据导出成压缩后的紧凑版js格式纯数据文件,省市区3级数据65kb大小。
- 将csv数据导出成JSON对象、JSON数组纯数据文件,省市区3级数据120kb+。
- 网页版省市区镇多级联动测试。
- 网页版省市区多级联动js代码生成(含数据)。

省市区这三级采用在线拼音工具转换,据说依据《新华字典》、《现代汉语词典》等规范性辞书校对,多音字地名大部分能正确拼音,重庆:chong qing,朝阳:chao yang,郫都:pi du,闵行:min hang,康巴什:kang ba shi。
镇级以下地名采用本地拼音库(assets/pinyin-python-server)转换,准确度没有省市区的高。
目前采用的是截取第一个字拼音的首字母。
方案一(2016版废弃):取每个字的拼音首字母排序,比如:河北:hb 湖北:hb 黑龙江:hlj 河南:hn 湖南:hn
方案二(2018版废弃):取的是第一个字前两个字母和后两个字首字母排序:河北:heb 黑龙江:helj 河南:hen 湖北:hub 湖南:hun
方案三(返璞归真):取第一个字首字母进行排序,如果两个字母相同,再使用名称文本进行排序:河北:h.河北 河南:h.河南 黑龙江:h.黑龙江 湖北:h.湖北 湖南:h.湖南
排序方案三看起来好些;为什么不直接用名称文本进行排序,我怕不同环境下对多音字不友好,最差情况下也不会比方案一差。
使用高德接口采集的,本来想采百度地图的,但经过使用发现百度地图数据有严重问题(百度已更新,不能复现了):
参考 肃宁县(右下方向那块飞地)、路南区(唐山科技职业技术学院那里一段诡异的边界) 边界,百度数据大量线段交叉的无效(百度地图测试),没有人工无法修正,高德没有这个问题(高德地图测试);polygon(百度已更新,不能复现了)
并且高德对镂空性质的地块处理比百度强,参考天津市对唐山大块飞地的处理,高德数据只需要Union操作就能生成polygon,百度既有Union操作又有Difference操作,极其复杂数据还无效。
所以放弃使用百度地图数据。
坐标和边界数据 和 省市区 数据是分开存储的,通过ID来进行关联。
可以把ok_geo.csv导入到数据库内使用,由于POLYGON需要解析,蛮复杂的,可以参考2019/map_geo_格式化.js内的SQL Server导入用的SQL语句的例子。
如果需要特定的POLYGON格式,可以根据上面介绍的字段格式,自行进行解析和验证。
使用过程中如果遇到多种不同坐标系的问题,比如请求的参数是WGS-84坐标(GPS),我们后端存储的是高德的坐标,可以通过将WGS-84坐标转成高德坐标后进行处理,百度的坐标一样。转换有相应方法,转换精度一般可以达到预期范围,可自行查找。或者直接把高德的原始坐标数据转换成目标坐标系后再存储(精度?)。


-
id编号和国家统计局的编号基本一致,方便以后更新,有很多网站接口数据中城市编号是和这个基本是一致的。
-
东莞、中山、儋州等没有第三级区级,自动添加同名的一级作为区级,以保证整个数据结构的一致性,添加的区以上级的ID结尾加两个0作为新ID,此结构ID兼容性还不错,比如:东莞(4419)下级只有一个区 东莞(441900)。 -
如果市、区没有下级,自动添加同名的一个城镇作为下级,以保证数据层次的一致性(任何一个数据都能满足省市区镇4级结构,没有孤立的);比如:
福建-泉州-金门没有镇,调整后为福建-泉州-金门-金门;另外从民政部中补全的城市也会缺失下级,照此规则自动补齐。 -
直辖市(河南、湖北、海南、** 的县级行政区划)根据编号规则本来只能作为区级,但为了便于用户选择,所有直辖市自动添加一个同名的市级,比如:
湖北-直辖市-仙桃-*镇调整后为湖北-仙桃-仙桃-*镇 -
地区名字是直接去掉常见的后缀进行精简的,如直接清除结尾的
市|区|县|街道办事处|XX族自治X,数量较少并且移除会导致部分名字产生歧义的后缀并未精简。 -
2017版开始数据结尾添加了自定义编号的
港澳台90、海外91数据,此编号并非标准编码,而是整理和参考标准编码规则自定义的,方便用户统一使用(注:民政部的台港澳编码为71、81、82)。 -
2018.190621版开始统计局采集过来的数据会和民政部的数据交叉对比后进行合并;由于统计局的数据明显的滞后,民政部内新添加的市、区将不会有镇级(自动补齐同名镇级);如果民政部数据存在明文撤销的市、区,那么合并的时候会删除统计局对应的数据,如:
山东-莱芜市于2019-01撤销,并在济南市新加莱芜区、钢城区;如果统计局中的数据在民政部数据内不存在,将原样保留,如:西沙群岛、100多个高新区、经济开发区。实际对比发现:统计局多出约150条数据;相对民政部缺失的数据很少(估计统计局下次发布就能抹平);统计局和民政部的编号完全一致。 -
2018版开始从高德采集了省市区三级坐标和行政区域边界范围数据,省市区总计3300+条数据,未采集到边界的有160条以内。关于未获取到坐标或边界的城市,本采集方案采取不处理策略,空着就空着,覆盖主要城市和主要人群,未覆盖区域实际使用过程中应该进行降级等处理。比如:尽最大可能的根据用户坐标来确定用户所在城市,因为存在没有边界信息的区域,未匹配到的应使用ip等城市识别方法。
- issues/2
乐亭县的乐读lào,此县下面的乐亭读音均已修正。
在低版本chrome控制台内运行1、2、3打头的文件即可完成采集,前提是指定网页打开的控制台。这三个文件按顺序执行。
最新采集代码内对拼音转换的接口变化蛮大,由于优秀的那个公网接口采取了IP限制措施,就算使用了全自动的切换代理,全量转换还是极为缓慢,因此采用了本地转换接口和公网转换接口结合的办法,省市区三级采用公网接口,其他的采用本地接口。公网接口转换的正确度极高,本地的略差那么一点。
- 打开国家统计局任页面 http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/。
- 控制台内粘贴
1_1_抓取国家统计局城市信息.js代码执行。 - 采集完成自动弹出下载,保存得到文件
data1_1.txt。 - 同样类似操作,在民政部网址把
1_2_抓取民政部城市信息.js执行,就能得到统计局和民政部合并的数据data1_2.txt。
- 启动
assets/pinyin-python-server中的本地拼音服务,根据2_1_抓取拼音.js中的提示对4级进行本地拼音转换,得到data-pinyin-local.txt。 - 根据
2_2_抓取拼音.js开头注释打开拼音接口页面,然后导入数据,进行省市区3级进行高准确度拼音转换。 - 拼音采集完成自动弹出下载,保存得到文件
data-pinyin.txt。
- 任意页面,最好是第二步这个页面,根据
3_格式化.js中的提示导入data-pinyin.txt,并执行代码。 - 格式化完成自动弹出下载,保存得到最终文件
ok_data_1234.csv。
使用坐标和边界目录内的map_geo.js、map_geo_格式化.js在高德地图测试页面,根据文件内的说明即可完成采集。
- 全国基础地理数据库:http://www.webmap.cn
- OpenStreetMap:https://www.openstreetmap.org
- 含街道居委会(五级)数据:https://github.com/modood/Administrative-divisions-of-China
如果这个库有帮助到您,请 Star 一下。
你也可以选择使用支付宝给我捐赠:

