-
Academic publishing has risen 2-fold in the past ten years, making it nearly impossible to sift through a large number of papers and identify broad areas of research within disciplines.
-
In order to understand such vast volumes of research, there is a need for automated content analysis (ACA) tools.
-
However, existing ACA tools such are expensive and lack in-depth analysis of publications.
-
To address these issues, we developed
pyResearchInsightsan end-to-end, open-source, automated content analysis tool that:- Scrapes abstracts from scientific repositories,
- Cleans the abstracts collected,
- Analyses temporal frequency of keywords,
- Visualizes themes of discussions using natural language processing.
This project is a collaboration between Sarthak J. Shetty, from the Center for Ecological Sciences, Indian Institute of Science and Vijay Ramesh, from the Department of Ecology, Evolution & Environmental Biology, Columbia University.
To install the package using pip, use the command:
pip install pyResearchInsightsSince pyResearchInsights is available on pip, it can be run on Google Colab as well where users can leverage Google's powerful CPU and GPU hardware.
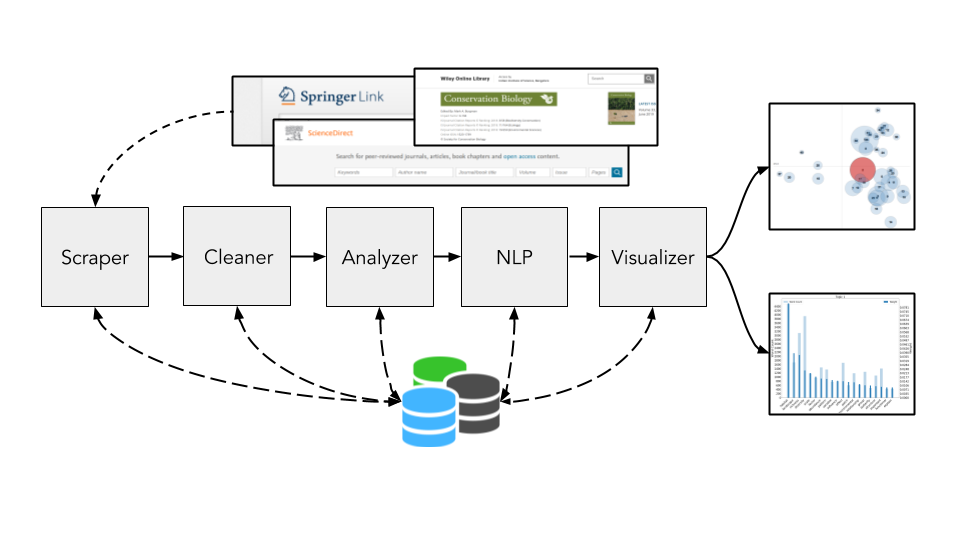
Figure 3.1 Diagrammatic representation of the pipeline.
pyResearchInsights is modular in nature. Each part of the package can be run independently or part of a larger pipeline.
This is an example pipeline, where we scrape abstracts from Springer pertaining to the conservation efforts in the Western Ghats.
from pyResearchInsights.common_functions import pre_processing
from pyResearchInsights.Scraper import scraper_main
from pyResearchInsights.Cleaner import cleaner_main
from pyResearchInsights.Analyzer import analyzer_main
from pyResearchInsights.NLP_Engine import nlp_engine_main
'''Abstracts containing these keywords will be queried from Springer'''
keywords_to_search = "Western Ghats Conservation"
'''Calling the pre_processing functions here so that abstracts_log_name and status_logger_name is available across the code.'''
abstracts_log_name, status_logger_name = pre_processing(keywords_to_search)
'''Runs the scraper here to scrape the details from the scientific repository'''
scraper_main(keywords_to_search, abstracts_log_name, status_logger_name)
'''Cleaning the corpus here before any of the other modules use it for analysis'''
cleaner_main(abstracts_log_name, status_logger_name)
'''Calling the Analyzer Function here'''
analyzer_main(abstracts_log_name, status_logger_name)
'''Calling the visualizer code below this portion'''
nlp_engine_main(abstracts_log_name, status_logger_name)Each module of the pacakage can be run independtely, as described in the following sections:
'''Importing pre_processing() which generates LOG files during the code run'''
from pyResearchInsights.common_functions import pre_processing
'''Importing the scraper_main() which initiates the scraping process'''
from pyResearchInsights.Scraper import scraper_main
'''Abstracts containing these keywords will be scraped from Springer'''
keywords_to_search = "Valdivian Forests Conservation"
'''The refernce to the LOG folder and the status_logger are returned by pre_processing() here'''
abstracts_log_name, status_logger_name = pre_processing(keywords_to_search)
'''Calling the scraper_main() to start the scraping processing'''
scraper_main(keywords_to_search, abstracts_log_name, status_logger_name)Here,
-
keywords- Abstracts queried from Springer will contain these keywords. -
abstracts_log_name- The.txtfile containing the abstracts downloaded. -
status_logger_name- File that contains logs the sequence of functions executed for later debugging. -
This script downloads abstracts from Springer containing the
keywords"Valdivian Forests Conservation".
'''Importing the cleaner_main() to clean the txt file of abstracts'''
from pyResearchInsights.Cleaner import cleaner_main
'''The location of the file to be cleaned is mentioned here'''
abstracts_log_name = "/location/to/txt/file/to/be/cleaned"
'''status_logger() logs the seequence of functions executed during the code run'''
status_logger_name = "Status_Logger_Name"
'''Calling the cleaner_main() here to clean the text file provided'''
cleaner_main(abstracts_log_name, status_logger_name)Here,
-
abstracts_log_name- The.txtfile containing the abstracts to be cleaned before generating research themes. -
status_logger_name- File that contains logs the sequence of functions executed for later debugging. -
This script cleans the
file_name.txtand generates afile_name_CLEANED.txtfile. Abstracts available online are often riddled with poor formatting and special characters.


'''Importing the analyzer_main() to analyze the frequency of keywords encountered in the text file'''
from pyResearchInsights.Analyzer import analyzer_main
'''The location of the file to be analyzed is mentioned here'''
abstracts_log_name = "/location/to/txt/file/to/be/analyzed"
'''status_logger() logs the seequence of functions executed during the code run'''
status_logger_name = "Status_Logger_Name"
'''Calling the cleaner_main() here to analyze the text file provided'''
analyzer_main(abstracts_log_name, status_logger_name)Here,
-
abstracts_log_name- The.txtfile containing the abstracts to be analyzed for temporal frequency of various keywords. -
status_logger_name- File that contains logs the sequence of functions executed for later debugging. -
This script analyzes the frequency of different keywords occuring in texts contained in
file_name.txt, and generates afile_name_FREQUENCY_CSV.csvfile.
'''Importing the nlp_engine_main() to generate the interactive topic modelling charts'''
from pyResearchInsights.NLP_Engine import nlp_engine_main
'''The location of the abstracts which will be used to train the language models'''
abstracts_log_name = "/location/to/txt/file/to/be/analyzed"
'''status_logger() logs the seequence of functions executed during the code run'''
status_logger_name = "Status_Logger_Name"
'''Calling the nlp_engine_main() here to train the language models on the texts provided'''
nlp_engine_main(abstracts_log_name, status_logger_name)Note: The Visualizer is integrated within the NLP_Engine function.
Here,
-
abstracts_log_name- The.txtfile containing the abstracts from which research themes are to be generated. -
status_logger_name- File that contains logs the sequence of functions executed for later debugging. -
This script generates the topic modelling and the frequency/weight charts for the abstracts in the
abstracts_log_namefile.
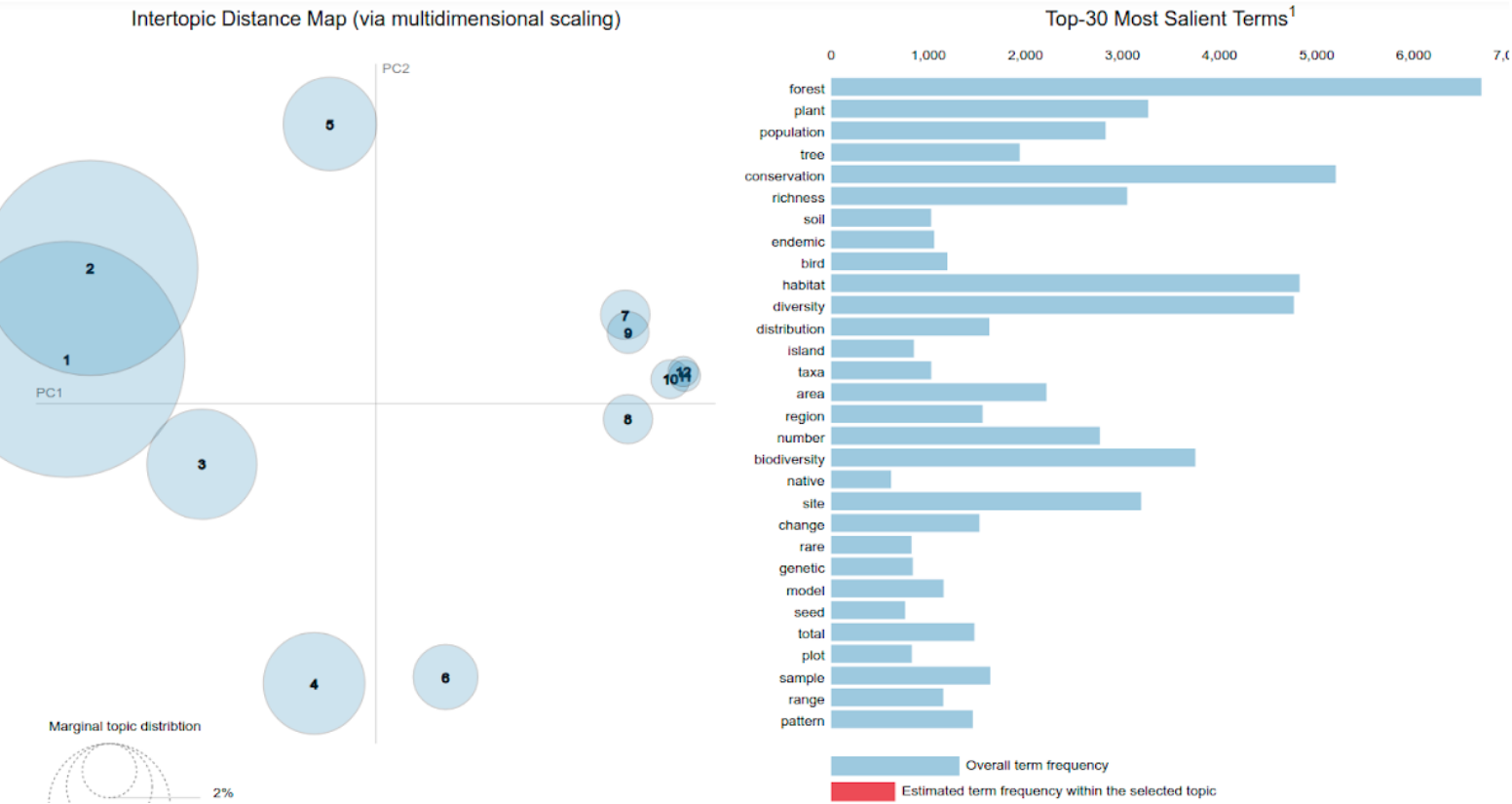
Figure 4.1 Distribution of topics presented as pyLDAvis charts
- Circles indicate topics generated from the
.txtfile supplied to theNLP_Engine.py. The number of topics here can be varied usine the--num_topicsflag of theNLP_Engine. - Each topic is made of a number of keywords, seen on the right.
- More details regarding the visualizations and the udnerlying mechanics can be checked out here.
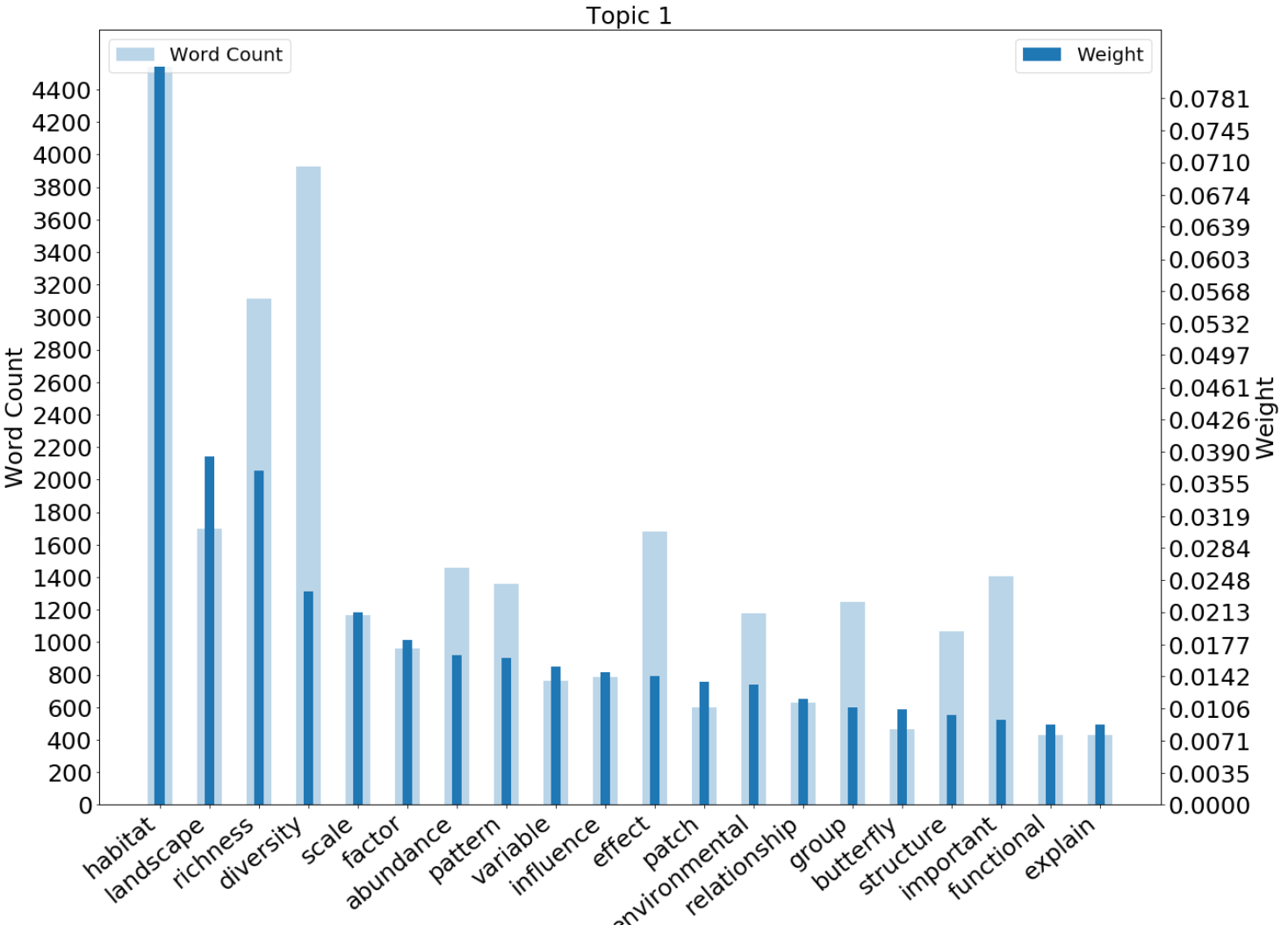
Figure 4.2 Here, we plot the variation in the weights and frequency of topic keywords.
- The weight of a keyword is calculated by its: i) frequency of occurance in the corpus and, ii) its frequency of co-occurance with other keywords in the same topic.