A Pytorch Implementation of Detectron


Example output of e2e_mask_rcnn-R-101-FPN_2x using Detectron pretrained weight.

Corresponding example output from Detectron.

Example output of e2e_keypoint_rcnn-R-50-FPN_s1x using Detectron pretrained weight.
This code follows the implementation architecture of Detectron. Only part of the functionality is supported. Check this section for more information.
With this code, you can...
- Train your model from scratch.
- Inference using the pretrained weight file (*.pkl) from Detectron.
This repository is originally built on jwyang/faster-rcnn.pytorch. However, after many modifications, the structure changes a lot and it's now more similar to Detectron. I deliberately make everything similar or identical to Detectron's implementation, so as to reproduce the result directly from official pretrained weight files.
This implementation has the following features:
-
It is pure Pytorch code. Of course, there are some CUDA code.
-
It supports multi-image batch training.
-
It supports multiple GPUs training.
-
It supports three pooling methods. Notice that only roi align is revised to match the implementation in Caffe2. So, use it.
-
It is memory efficient. For data batching, there are two techiniques available to reduce memory usage: 1) Aspect grouping: group images with similar aspect ratio in a batch 2) Aspect cropping: crop images that are too long. Aspect grouping is implemented in Detectron, so it's used for default. Aspect cropping is the idea from jwyang/faster-rcnn.pytorch, and it's not used for default.
Besides of that, I implement a customized
nn.DataParallelmodule which enables different batch blob size on different gpus. Check My nn.DataParallel section for more details about this.
Getting Started
Clone the repo:
git clone https://github.com/roytseng-tw/mask-rcnn.pytorch.git
Requirements
Tested under python3.
- python packages
- pytorch==0.3.1 (cuda80, cudnn7.1.2)
- torchvision==0.2.0
- cython
- numpy
- scipy
- opencv
- pyyaml
- pycocotools — for COCO dataset, also available from pip.
- tensorboardX — for logging the losses in Tensorboard
- An NVIDAI GPU and CUDA 8.0 or higher. Some operations only have gpu implementation.
- NOTICE: different versions of Pytorch package have different memory usages.
Compilation
Compile the CUDA code:
cd lib # please change to this directory
sh make.sh
If your are using Volta GPUs, uncomment this line in lib/mask.sh and remember to postpend a backslash at the line above. CUDA_PATH defaults to /usr/loca/cuda. If you want to use a CUDA library on different path, change this line accordingly.
It will compile all the modules you need, including NMS, ROI_Pooing, ROI_Crop and ROI_Align. (Actually gpu nms is never used ...)
Note that, If you use CUDA_VISIBLE_DEVICES to set gpus, make sure at least one gpu is visible when compile the code.
Data Preparation
Create a data folder under the repo,
cd {repo_root}
mkdir data
-
COCO: Download the coco images and annotations from coco website.
And make sure to put the files as the following structure:
coco ├── annotations | ├── instances_minival2014.json │ ├── instances_train2014.json │ ├── instances_train2017.json │ ├── instances_val2014.json │ ├── instances_val2017.json │ ├── instances_valminusminival2014.json │ ├── ... | └── images ├── train2014 ├── train2017 ├── val2014 ├──val2017 ├── ...Download coco mini annotations from here. Please note that minival is exactly equivalent to the recently defined 2017 val set. Similarly, the union of valminusminival and the 2014 train is exactly equivalent to the 2017 train set.
Feel free to put the dataset at any place you want, and then soft link the dataset under the
data/folder:ln -s path/to/coco data/cocoRecommend to put the images on a SSD for possible better training performance
Pretrained Model
I use ImageNet pretrained weights from Caffe for the backbone networks.
Download them and put them into the {repo_root}/data/pretrained_model.
You can the following command to download them all:
- extra required packages:
argparse_color_formater,colorama,requests
python tools/download_imagenet_weights.py
NOTE: Caffe pretrained weights have slightly better performance than Pytorch pretrained. Suggest to use Caffe pretrained models from the above link to reproduce the results. By the way, Detectron also use pretrained weights from Caffe.
If you want to use pytorch pre-trained models, please remember to transpose images from BGR to RGB, and also use the same data preprocessing (minus mean and normalize) as used in Pytorch pretrained model.
Training
Adapative config adjustment
Following config options will be adjusted according to actual training setups: 1) number of GPUs NUM_GPUS, 2) batch size per GPU TRAIN.IMS_PER_BATCH, 3) update period iter_size
Let's define some terms first
batch_size: NUM_GPUS x TRAIN.IMS_PER_BATCH
effective_batch_size: batch_size x iter_size
change of somethining: new value of something / old value of something
SOLVER.BASE_LR: adjust directly propotional to the change of batch_size.SOLVER.STEPS,SOLVER.MAX_ITER: adjust inversely propotional to the change of effective_batch_size.
Train from scratch
Take mask-rcnn with res50 backbone for example.
python tools/train_net_step.py --dataset coco2017 --cfg configs/e2e_mask_rcnn_R-50-C4.yml --use_tfboard --bs {batch_size} --nw {num_workers}
Use --bs to overwrite the default batch size to a proper value that fits into your GPUs. Simliar for --nw, number of data loader threads defaults to 4 in config.py.
Specify —-use_tfboard to log the losses on Tensorboard.
NOTE: use --dataset keypoints_coco2017 when training for keypoint-rcnn.
The use of --iter_size
As in Caffe, update network once (optimizer.step()) every iter_size iterations (forward + backward). This way to have a larger effective batch size for training. Notice that, step count is only increased after network update.
python tools/train_net_step.py --dataset coco2017 --cfg configs/e2e_mask_rcnn_R-50-C4.yml --bs 4 --iter_size 4
iter_size defaults to 1.
Finetune from a pretrained checkpoint
python tools/train_net_step.py ... --load_ckpt {path/to/the/checkpoint}
or using Detectron's checkpoint file
python tools/train_net_step.py ... --load_detectron {path/to/the/checkpoint}
Resume training with the same dataset and batch size
python tools/train_net_step.py ... --load_ckpt {path/to/the/checkpoint} --resume
When resume the training, step count and optimizer state will also be restored from the checkpoint. For SGD optimizer, optimizer state contains the momentum for each trainable parameter.
NOTE: --resume is not yet supported for --load_detectron
Set config options in command line
python tools/train_net_step.py ... --no_save --set {config.name1} {value1} {config.name2} {value2} ...
- For Example, run for debugging.
Load less annotations to accelarate training progress. Add
python tools/train_net_step.py ... --no_save --set DEBUG True--no_saveto avoid saving any checkpoint or logging.
Show command line help messages
python train_net_step.py --help
Two Training Scripts
In short, use train_net_step.py.
In train_net_step.py:
SOLVER.LR_POLICY: steps_with_decayis supported.- Training warm up in Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour is supported.
(Deprecated) In train_net.py some config options have no effects and worth noticing:
-
SOLVER.LR_POLICY,SOLVER.MAX_ITER,SOLVER.STEPS,SOLVER.LRS: For now, the training policy is controlled by these command line arguments:--epochs: How many epochs to train. One epoch means one travel through the whole training sets. Defaults to 6.--lr_decay_epochs: Epochs to decay the learning rate on. Decay happens on the beginning of a epoch. Epoch is 0-indexed. Defaults to [4, 5].
For more command line arguments, please refer to
python train_net.py --help -
SOLVER.WARM_UP_ITERS,SOLVER.WARM_UP_FACTOR,SOLVER.WARM_UP_METHOD: Training warm up is not supported.
Inference
Evaluate the training results
For example, test mask-rcnn on coco2017 val set
python tools/test_net.py --dataset coco2017 --cfg config/e2e_mask_rcnn_R-50-FPN_1x.yaml --load_ckpt {path/to/your/checkpoint}
Use --load_detectron to load Detectron's checkpoint. If multiple gpus are available, add --multi-gpu-testing.
Specify a different output directry, use --output_dir {...}. Defaults to {the/parent/dir/of/checkpoint}/test
Visualize the training results on images
python tools/infer_simple.py --dataset coco --cfg cfgs/e2e_mask_rcnn_R-50-C4.yml --load_ckpt {path/to/your/checkpoint} --image_dir {dir/of/input/images} --output_dir {dir/to/save/visualizations}
--output_dir defaults to infer_outputs.
Supported Network modules
-
Backbone:
- ResNet:
ResNet50_conv4_body,ResNet50_conv5_body,ResNet101_Conv4_Body,ResNet101_Conv5_Body,ResNet152_Conv5_Body - FPN:
fpn_ResNet50_conv5_body,fpn_ResNet50_conv5_P2only_body,fpn_ResNet101_conv5_body,fpn_ResNet101_conv5_P2only_body,fpn_ResNet152_conv5_body,fpn_ResNet152_conv5_P2only_body
ResNeXt is also implemented but not yet tested.
- ResNet:
-
Box head:
ResNet_roi_conv5_head,roi_2mlp_head -
Mask head:
mask_rcnn_fcn_head_v0upshare,mask_rcnn_fcn_head_v0up,mask_rcnn_fcn_head_v1up4convs,mask_rcnn_fcn_head_v1up -
Keypoints head:
roi_pose_head_v1convX
NOTE: the naming is similar to the one used in Detectron. Just remove any prepending add_.
Supported Datasets
Only COCO is supported for now. However, the whole dataset library implementation is almost identical to Detectron's, so it should be easy to add more datasets supported by Detectron.
Configuration Options
Architecture specific configuration files are put under configs. The general configuration file lib/core/config.py has almost all the options with same default values as in Detectron's, so it's effortless to transform the architecture specific configs from Detectron.
Some options from Detectron are not used because the corresponding functionalities are not implemented yet. For example, data augmentation on testing.
Extra options
MODEL.LOAD_IMAGENET_PRETRAINED_WEIGHTS = True: Whether to load ImageNet pretrained weights.RESNETS.IMAGENET_PRETRAINED_WEIGHTS = '': Path to pretrained residual network weights. If start with'/', then it is treated as a absolute path. Otherwise, treat as a relative path toROOT_DIR.
TRAIN.ASPECT_CROPPING = False,TRAIN.ASPECT_HI = 2,TRAIN.ASPECT_LO = 0.5: Options for aspect cropping to restrict image aspect ratio range.RPN.OUT_DIM_AS_IN_DIM = True,RPN.OUT_DIM = 512,RPN.CLS_ACTIVATION = 'sigmoid': Official implement of RPN has same input and output feature channels and use sigmoid as the activation function for fg/bg class prediction. In jwyang's implementation, it fix output channel number to 512 and use softmax as activation function.
How to transform configuration files from Detectron
- Remove
MODEL.NUM_CLASSES. It will be set according to the dataset specified by--dataset. - Remove
TRAIN.WEIGHTS,TRAIN.DATASETSandTEST.DATASETS - For module type options (e.g
MODEL.CONV_BODY,FAST_RCNN.ROI_BOX_HEAD...), removeadd_in the string if exists. - If want to load ImageNet pretrained weights for the model, add
RESNETS.IMAGENET_PRETRAINED_WEIGHTSpointing to the pretrained weight file. If not, setMODEL.LOAD_IMAGENET_PRETRAINED_WEIGHTStoFalse. - [Optional] Delete
OUTPUT_DIR: .at the last line - Do NOT change the option
NUM_GPUSin the config file. It's used to infer the original batch size for training, and learning rate will be linearly scaled according to batch size change. Proper learning rate adjustment is important for training with different batch size.
My nn.DataParallel
- Keep certain keyword inputs on cpu Official DataParallel will broadcast all the input Variables to GPUs. However, many rpn related computations are done in CPU, and it's unnecessary to put those related inputs on GPUs.
- Allow Different blob size for different GPU To save gpu memory, images are padded seperately for each gpu.
- Work with returned value of dictionary type
Benchmark
Benchmark results with Detectron's checkpoints are same as the numbers reported by Detetron.
faster_rcnn
-
tutorial_2gpu_e2e_faster_rcnn_R-50-FPN.yaml
Mentioned in Detectron's GETTING_STARTED.md:
Box AP on coco_2014_minival should be around 22.1% (+/- 0.1% stdev measured over 3 runs)
Because lack of multiple GPUs for training with larger batch size, this tutorial example is a good example for measuring the training from scratch performance.
-
Training command:
python tools/train_net_step.py --dataset coco2017 --cfg configs/tutorial_2gpu_e2e_faster_rcnn_R-50-FPN.yaml -
Exactly same settings as Detectron.
-
Results:
Box
AP50:95 AP50 AP75 APs APm APl 0.221 0.412 0.215 0.094 0.238 0.317
-
mask_rcnn
-
e2e_mask_rcnn-R-50-FPN_1x with 4 x M40
Trained on commit 3405283, before changing the Xavier initialization implementation.
-
Training command:
python tools/train_net_step.py --dataset coco2017 --cfg configs/e2e_mask_rcnn_R-50-FPN_1x.yaml -
Same batch size and learning rate.
-
Differences to Detectron:
- Number of GPUs: 4 vs. 8
- Number of Images per GPU: 4 vs. 2 (will slightly affect image padding)
-
Results:
Box
AP50:95 AP50 AP75 APs APm APl 0.374 0.587 0.407 0.209 0.400 0.494 Mask
AP50:95 AP50 AP75 APs APm APl 0.337 0.553 0.358 0.149 0.360 0.506 -
Detectron:
Box
AP50:95 AP50 AP75 APs APm APl 0.377 0.592 0.409 0.214 0.408 0.497 Mask
AP50:95 AP50 AP75 APs APm APl 0.339 0.558 0.358 0.149 0.363 0.509
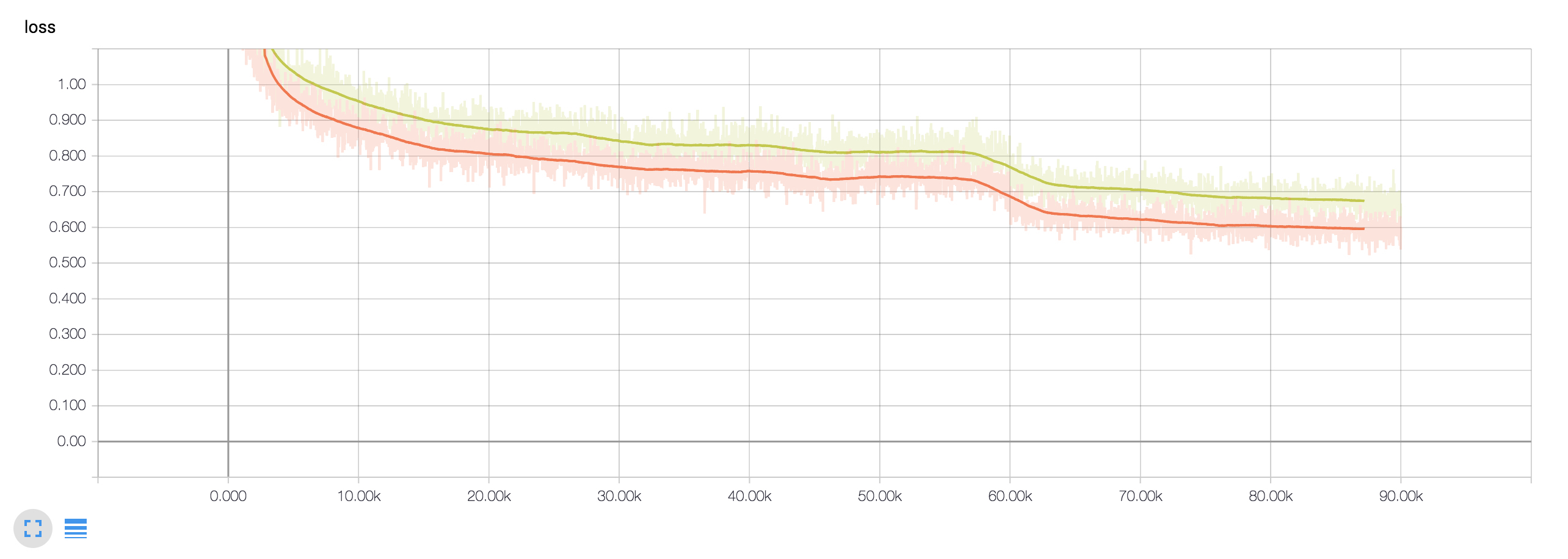 Green: loss of this training.
Green: loss of this training.
Orange: loss parsed from Detectron's log -
-
e2e_mask_rcnn-R-50-FPN_1x with 2 x 1080ti
-
Training command:
python tools/train_net_step.py --dataset coco2017 --cfg configs/e2e_mask_rcnn_R-50-FPN_1x.yaml --bs 6 -
Same solver configuration as to Detectron, i.e. same training steps and so on.
-
Differences to Detectron:
- Batch size: 6 vs. 16
- Learing rate: 3/8 of the Detectron's learning rate on each step.
- Number of GPUs: 2 vs. 8
- Number of Images per GPU: 3 vs. 2
-
Results:
Box
AP50:95 AP50 AP75 APs APm APl 0.341 0.555 0.367 0.194 0.364 0.448 Mask
AP50:95 AP50 AP75 APs APm APl 0.311 0.521 0.325 0.139 0.332 0.463 -
Detectron:
Box
AP50:95 AP50 AP75 APs APm APl 0.377 0.592 0.409 0.214 0.408 0.497 Mask
AP50:95 AP50 AP75 APs APm APl 0.339 0.558 0.358 0.149 0.363 0.509
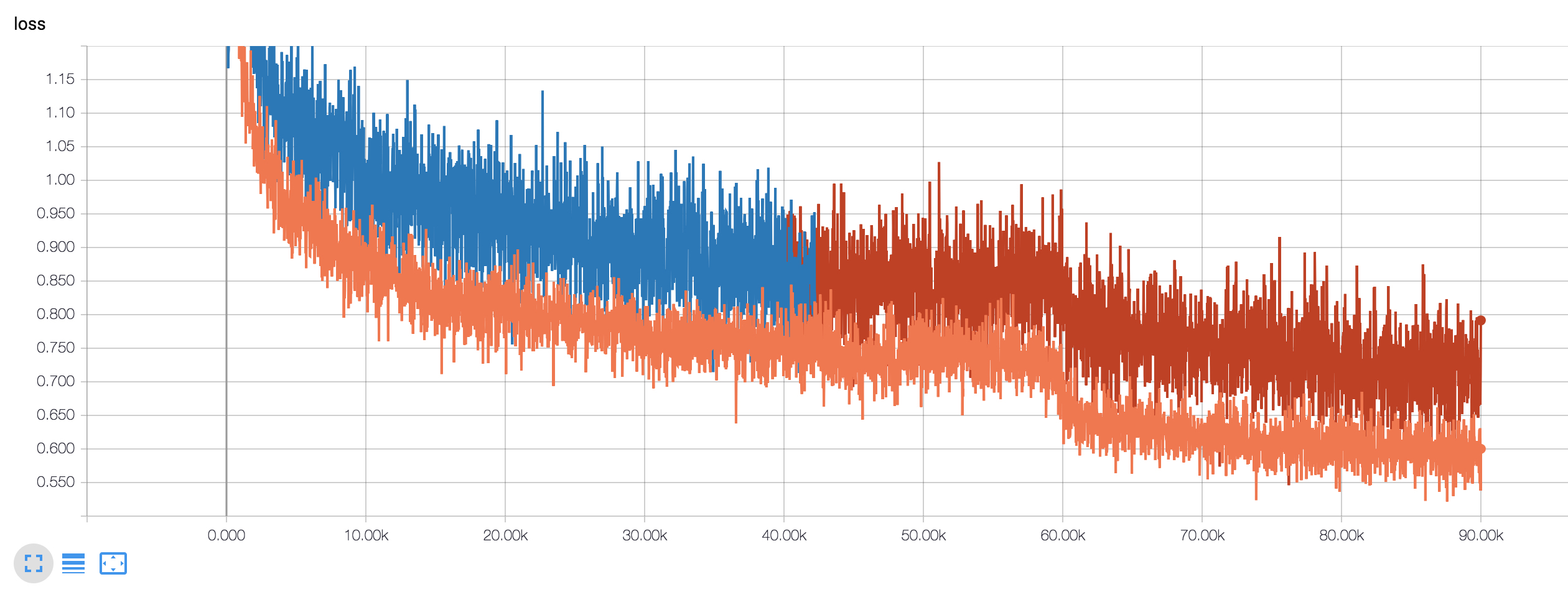 Orange: loss parsed from Detectron's log
Orange: loss parsed from Detectron's log
Blue + Brown: loss of this training. -


keypoint_rcnn
- e2e_keypoint_rcnn_R-50-FPN_1x
-
Training command:
python tools/train_net_step.py --dataset keypoints_coco201 --cfg configs/e2e_keypoint_rcnn_R-50-FPN_1x.yaml --bs 8 -
Same solver configuration as to Detectron, i.e. same training steps and so on.
-
Differences to Detectron:
- Batch size: 8 vs. 16
- Learing rate: 1/2 of the Detectron's learning rate on each step.
- Number of GPUs: 2 vs. 8
- Number of Images per GPU: 4 vs. 2
-
Results:
Box
AP50:95 AP50 AP75 APm APl 0.520 0.815 0.566 0.352 0.597 Keypoint
AP50:95 AP50 AP75 APm APl 0.623 0.853 0.673 0.570 0.710 -
Detectron:
Box
AP50:95 AP50 AP75 APm APl 0.536 0.828 0.583 0.365 0.612 Keypoint
AP50:95 AP50 AP75 APm APl 0.642 0.864 0.699 0.585 0.734 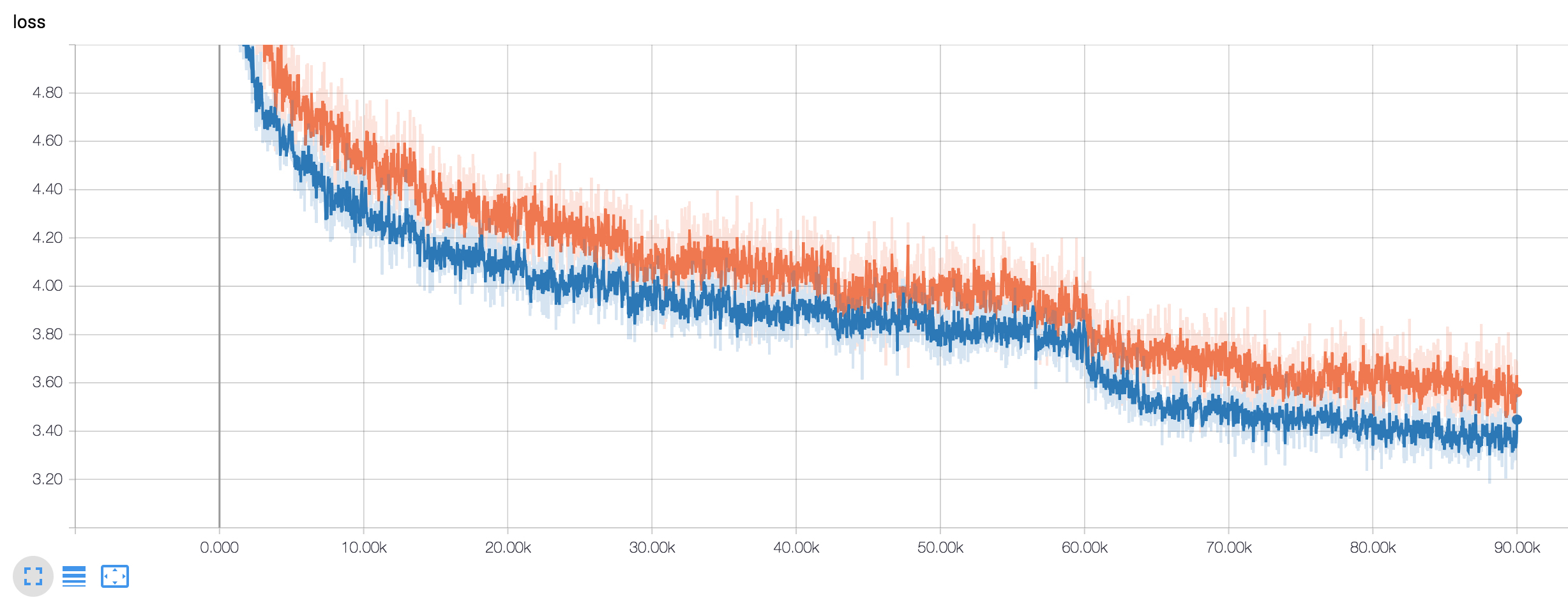 Orange: loss of this training.
Orange: loss of this training.
Blue: loss parsed from Detectron's log
-
