LLaMA-rs
Do the LLaMA thing, but now in Rust
🦀 🚀 🦙
![]()
Image by @darthdeus, using Stable Diffusion




LLaMA-rs is a Rust port of the llama.cpp project. This allows running inference for Facebook's LLaMA model on a CPU with good performance using full precision, f16 or 4-bit quantized versions of the model.
Just like its C++ counterpart, it is powered by the
ggml tensor library, achieving the same performance as the original code.
Getting started
Make sure you have a rust toolchain set up.
- Get a copy of the model's weights1
- Clone the repository
- Build (
cargo build --release) - Run with
cargo run --release -- <ARGS>
NOTE: For best results, make sure to build and run in release mode. Debug builds are going to be very slow.
For example, you try the following prompt:
cargo run --release -- -m /data/Llama/LLaMA/7B/ggml-model-q4_0.bin -p "Tell me how cool the Rust programming language is:"Some additional things to try:
-
Use
--helpto see a list of available options. -
If you have the alpaca-lora weights, try
--replmode!cargo run --release -- -m <path>/ggml-alpaca-7b-q4.bin -f examples/alpaca_prompt.txt --repl.
-
Prompt files can be precomputed to speed up processing using the
--cache-promptand--restore-promptflags so you can save processing time for lengthy prompts.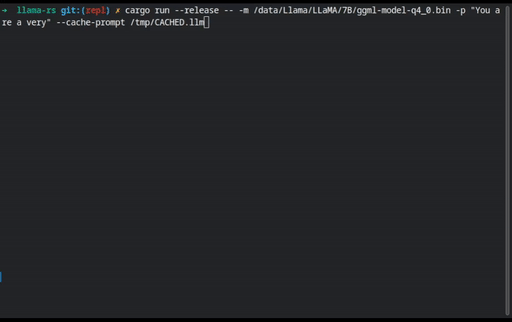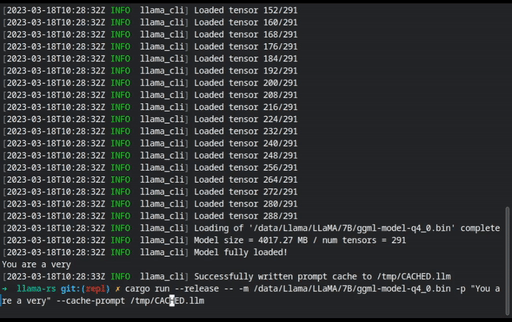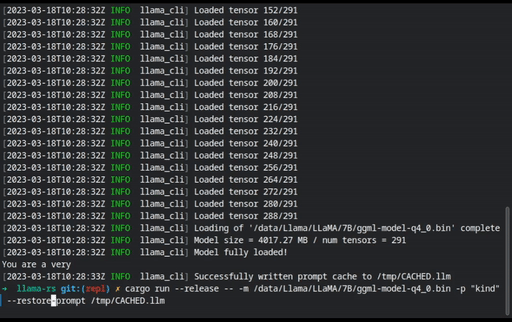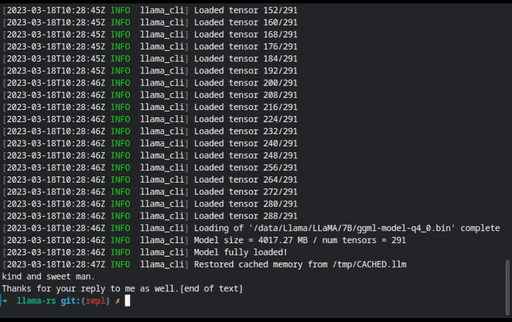


Q&A
-
Q: Why did you do this?
-
A: It was not my choice. Ferris appeared to me in my dreams and asked me to rewrite this in the name of the Holy crab.
-
Q: Seriously now
-
A: Come on! I don't want to get into a flame war. You know how it goes, something something memory something something cargo is nice, don't make me say it, everybody knows this already.
-
Q: I insist.
-
A: Sheesh! Okaaay. After seeing the huge potential for llama.cpp, the first thing I did was to see how hard would it be to turn it into a library to embed in my projects. I started digging into the code, and realized the heavy lifting is done by
ggml(a C library, easy to bind to Rust) and the whole project was just around ~2k lines of C++ code (not so easy to bind). After a couple of (failed) attempts to build an HTTP server into the tool, I realized I'd be much more productive if I just ported the code to Rust, where I'm more comfortable. -
Q: Is this the real reason?
-
A: Haha. Of course not. I just like collecting imaginary internet points, in the form of little stars, that people seem to give to me whenever I embark on pointless quests for rewriting X thing, but in Rust.
Known issues / To-dos
Contributions welcome! Here's a few pressing issues:
- The quantization code has not been ported (yet). You can still use the quantized models with llama.cpp.
- No crates.io release. The name
llama-rsis reserved and I plan to do this soon-ish. - Any improvements from the original C++ code. (See rustformers#15)
- Debug builds are currently broken.
- The code needs to be "library"-fied. It is nice as a showcase binary, but the real potential for this tool is to allow embedding in other services.
- The code only sets the right CFLAGS on Linux. The
build.rsscript inggml_rawneeds to be fixed, so inference will be very slow on every other OS.
Footnotes
-
The only legal source to get the weights at the time of writing is this repository. The choice of words also may or may not hint at the existence of other kinds of sources.
↩