

Xorbits is an open-source computing framework that makes it easy to scale data science and machine learning workloads — from data preprocessing to tuning, training, and model serving. Xorbits can leverage multi-cores or GPUs to accelerate computation on a single machine or scale out up to thousands of machines to support processing terabytes of data and training or serving large models.
Xorbits provides a suite of best-in-class libraries for data scientists and machine learning practitioners. Xorbits provides the capability to scale tasks without the necessity for extensive knowledge of infrastructure.
Xorbits features a familiar Python API that supports a variety of libraries, including pandas, NumPy, PyTorch, XGBoost, etc. With a simple modification of just one line of code, your pandas workflow can be seamlessly scaled using Xorbits:
As ML and AI workloads continue to grow in complexity, the computational demands soar high. Even though single-node development environments like your laptop provide convenience, but they fall short when it comes to accommodating these scaling demands.
To use Xorbits, you do not need to specify how to distribute the data or even know how many cores your system has. You can keep using your existing notebooks and still enjoy a significant speed boost from Xorbits, even on your laptop.
Xorbits can leverage all of your computational cores. It is especially beneficial for handling larger datasets, where pandas may slow down or run out of memory.
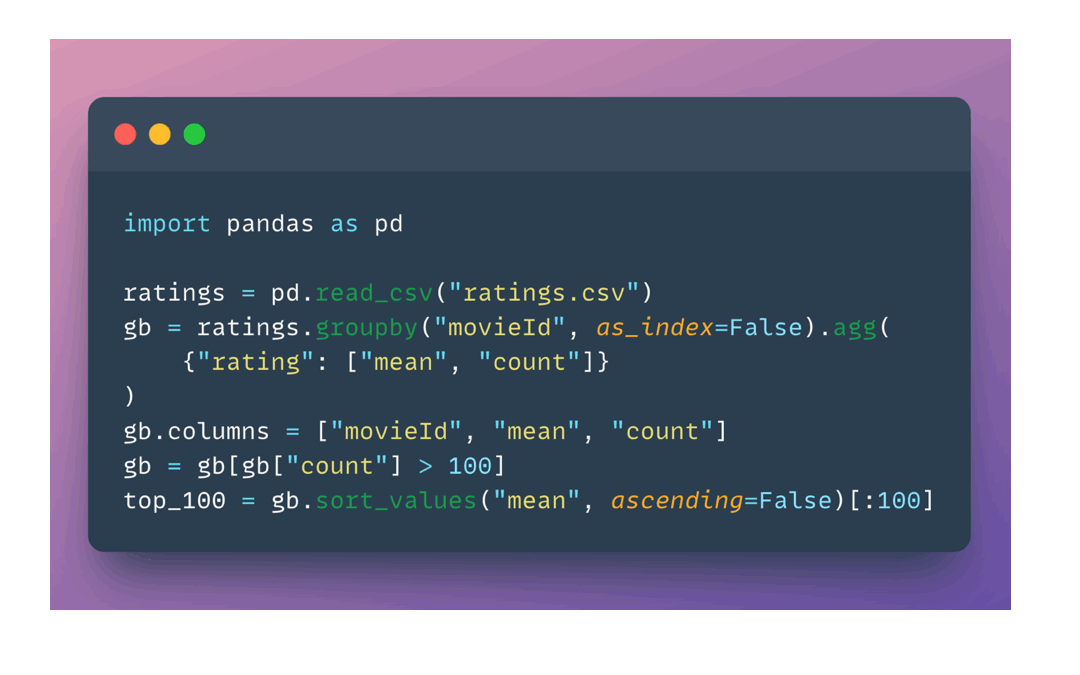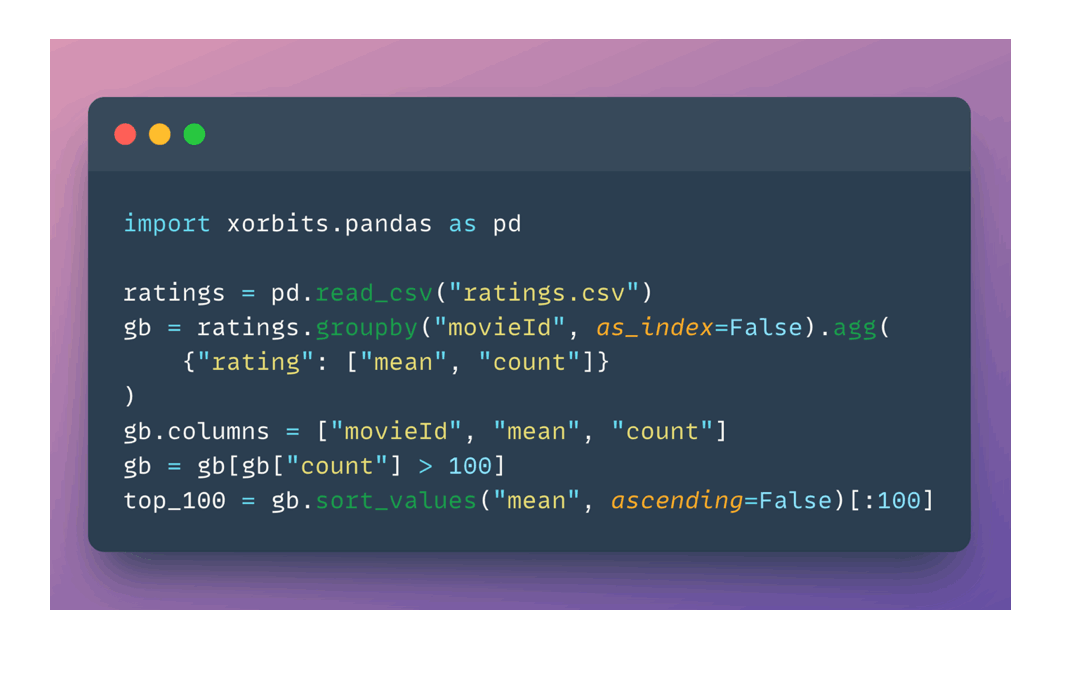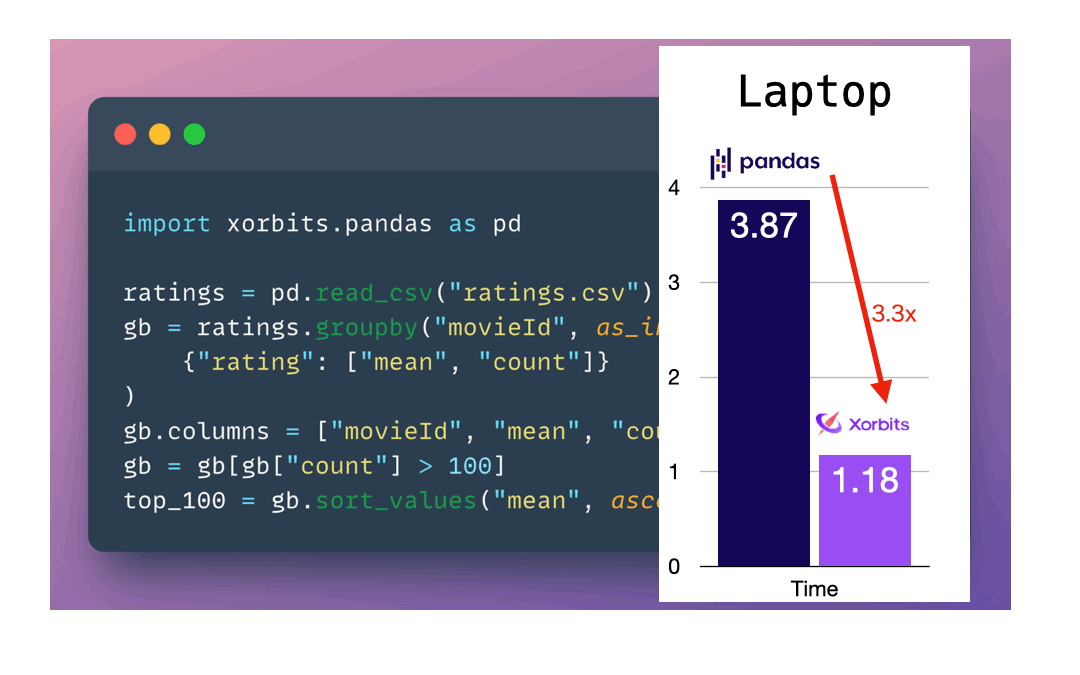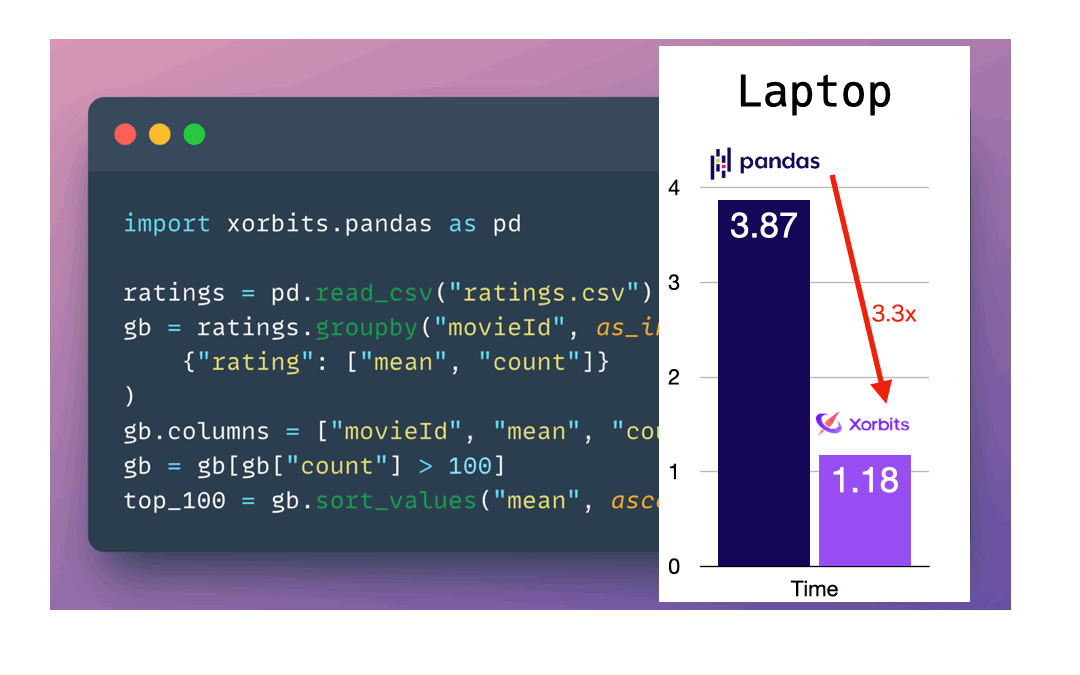
According to our benchmark tests, Xorbits surpasses other popular pandas API frameworks in speed and scalability. See our performance comparison and explanation.
Xorbits aims to take full advantage of the entire ML ecosystem, offering native integration with pandas and other libraries.
The source code is currently hosted on GitHub at: https://github.com/xorbitsai/xorbits
Binary installers for the latest released version are available at the Python Package Index (PyPI).
# PyPI
pip install xorbitsThe main goals we want to achieve in the future include the following:
- Transitioning from pandas native to arrow native for data storage
will reduce the memory cost substantially and is more friendly for compute engine. - Introducing native engines that leverage technologies like vectorization and codegen to accelerate computations.
- Scale as many libraries and algorithms as possible!
More detailed roadmaps will be revealed soon. Stay tuned!
The creators of Xorbits are mainly those of Mars, and we currently built Xorbits on Mars to reduce duplicated work, but the vision of Xorbits suggests that it's not appropriate to put everything on Mars. Instead, we need a new project to support the roadmaps better. In the future, we will replace some core internal components with other upcoming ones we will propose. Stay tuned!
| Platform | Purpose |
|---|---|
| Discourse Forum | Asking usage questions and discussing development. |
| Github Issues | Reporting bugs and filing feature requests. |
| Slack | Collaborating with other Xorbits users. |
| StackOverflow | Asking questions about how to use Xorbits. |
| Staying up-to-date on new features. |