This project focuses on conducting an end-to-end analysis of the relationship between book ratings and customer reviews. To achieve this, Python webscraping techniques and regex are employed to extract data from the website https://www.goodreads.com/. The dataset stems from the Top 100 books picked by Times magazine on goodreads.com (https://www.goodreads.com/list/show/2681.Time_Magazine_s_All_Time_100_Novels).Afterwhich,the extracted data is then stored in a graph database called ArangoDB. In order to accurately explore the underlying correlation between book ratings and customer reviews, it is important to identify and filter out non-meaningful reviews as they could potentially influence our results. To aid this process, a text classification pipeline is developed using ML and NLP techniques. After determining a sufficient model, flagged reviews are cleaned from the final dataset and pushed for uploading into the database.
The web scraper is built within python utilizing the libraries Selenium and BeautifulSoup. After retrieval, all data is saved and loaded into flat files and preprocessed.
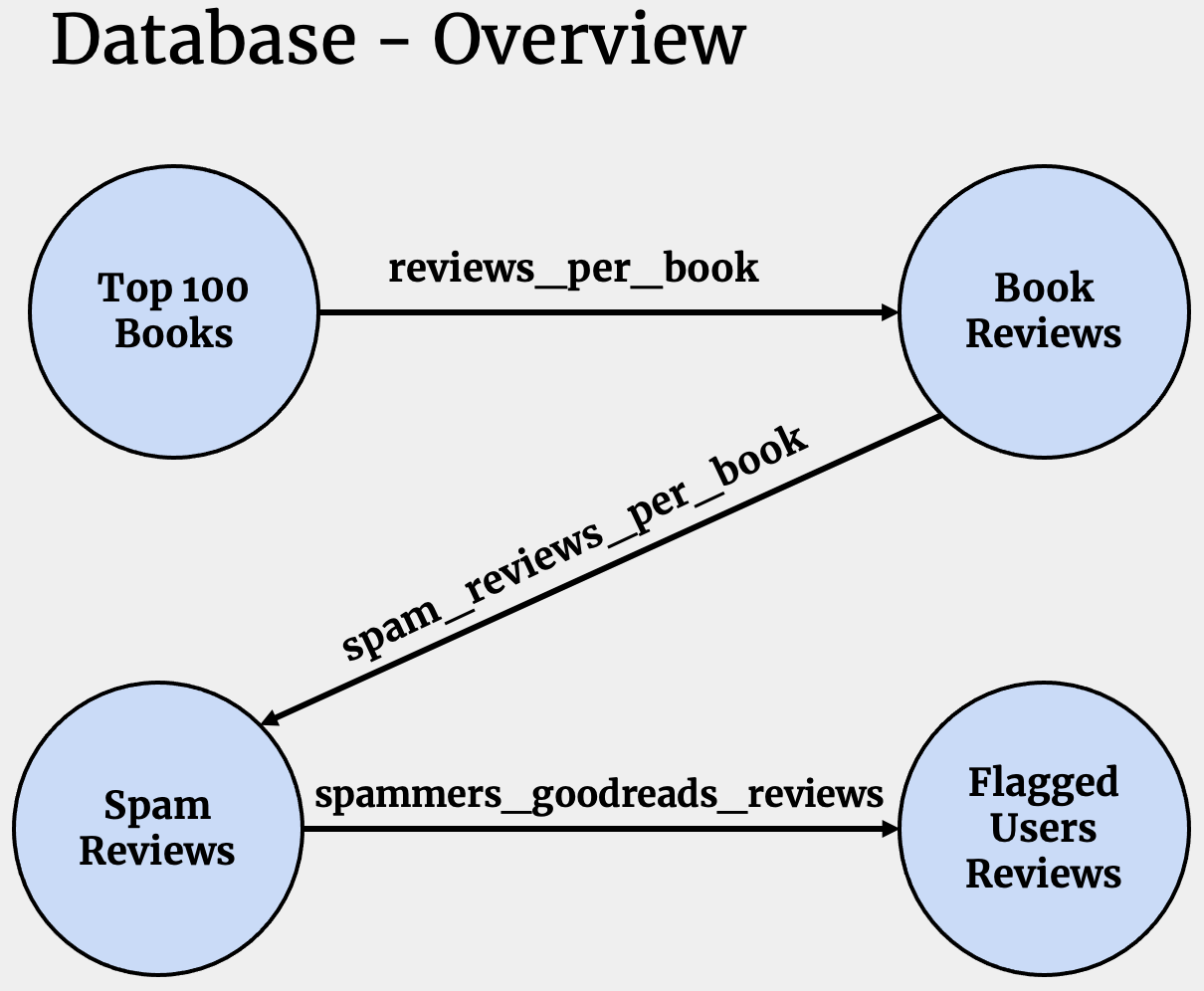
- Database Overview

The ML model is trained using a sample dataset consisting of the first 30 reviews from three books (total 87 datapoints, excluding null values). During the exercise, two models are developed: a semi-supervised SelfTrainingClassifier and a supervised SVC.
-
Text Classification Pipeline
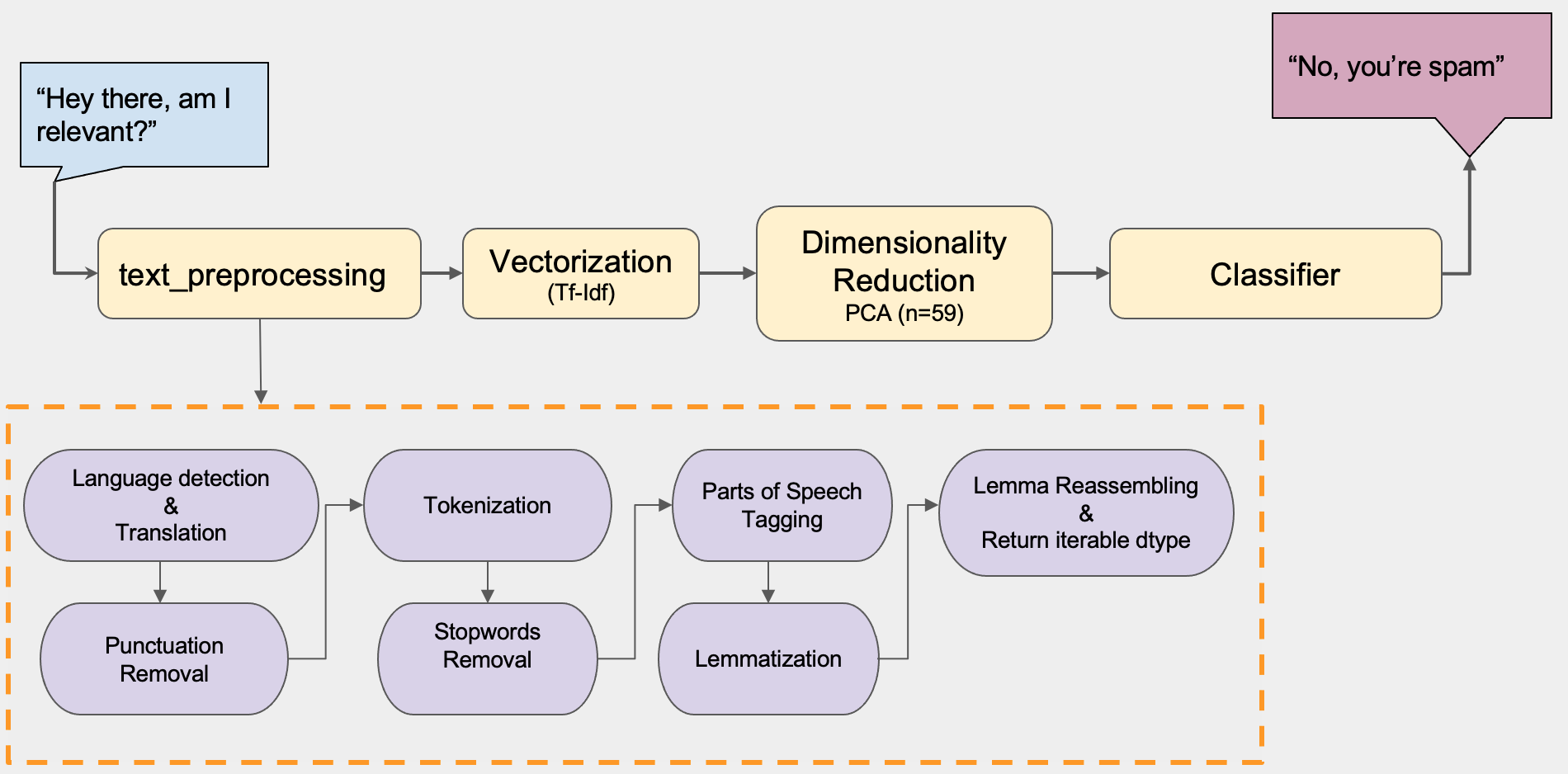
-
Classifier
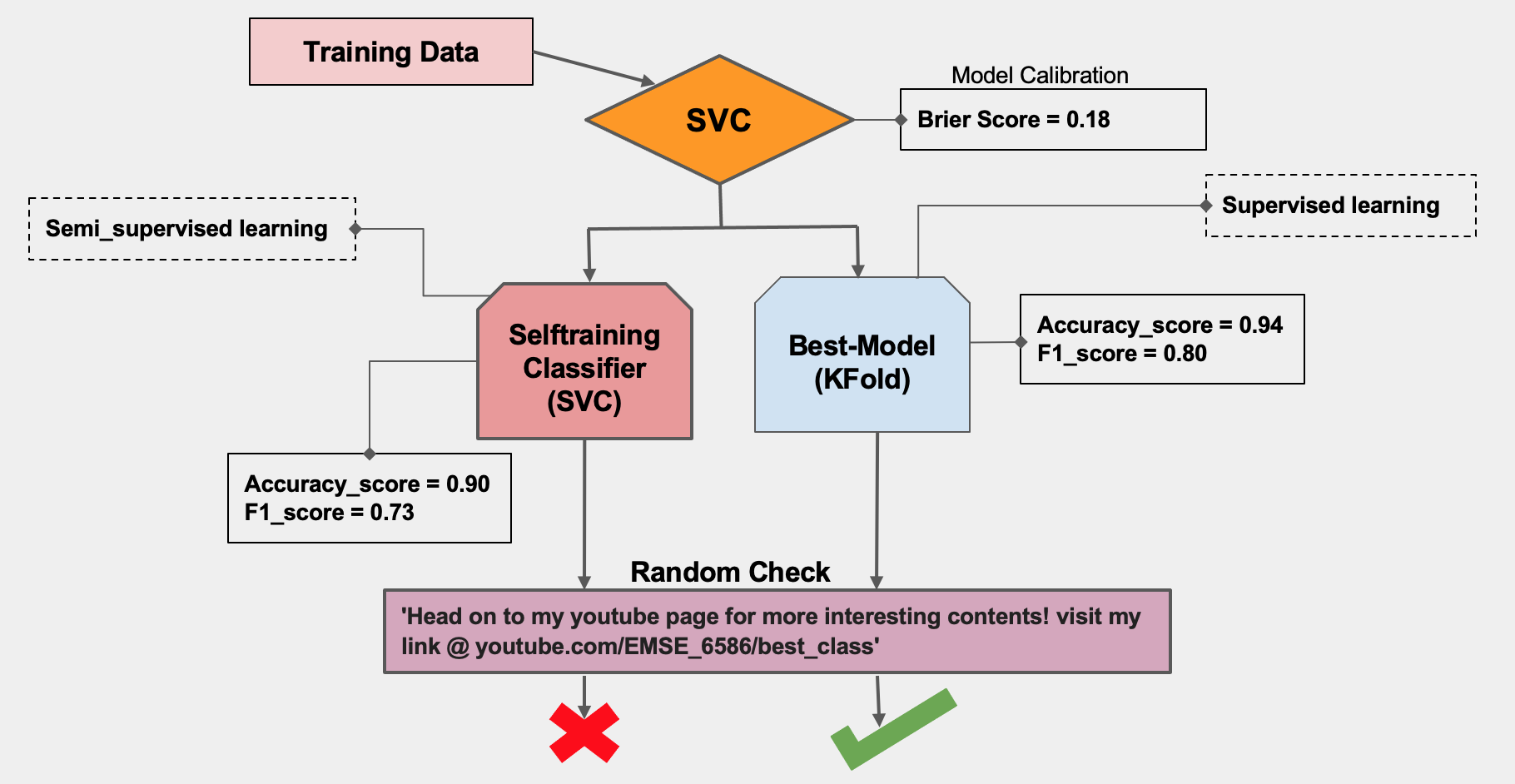


The selected model is then saved as "spam_detector.joblib" and can be loaded/imported for future use.
From the image above, we notice that Supervised Classifier predicted the random string correctly compared to the Semi_supervised model.
- By splitting the reviews into bigrams and determining their frequency of occurrence, we observe a 72% positive correlation between the frequency of bigrams and the book rating.
- According to the Chi-square test for independence, the results shows that the null hypothesis is rejected in favor of the alternative hypothesis that frequency of occurence of bigrams in reviews tells us something about the customer ratings of the books (p_value < 0.05)
- The relationship between reviews and ratings exists in the presence and frequency of words.
- Most occurring bigrams contain words that are associated with the contents, characters and authors of the books being reviewed.
- The length of reviews and the extent to which reviewers express themselves are independent of their book rating.
- Mobolaji Shobanke
- Martin Banghart