![]()
![]()


Ktorm is a lightweight and efficient ORM Framework for Kotlin directly based on pure JDBC. It provides strong-typed and flexible SQL DSL and convenient sequence APIs to reduce our duplicated effort on database operations. All the SQL statements, of course, are generated automatically. Ktorm is open source and available under the Apache 2.0 license. Please leave a star if you've found this library helpful!
For more documentation, go to our site: https://www.ktorm.org.
- No configuration files, no XML, no annotations, even no third-party dependencies, lightweight, easy to use.
- Strong typed SQL DSL, exposing low-level bugs at compile time.
- Flexible queries, fine-grained control over the generated SQLs as you wish.
- Entity sequence APIs, writing queries via sequence functions such as
filter,map,sortedBy, etc., just like using Kotlin's native collections and sequences. - Extensible design, write your own extensions to support more operators, data types, SQL functions, database dialects, etc.
Ktorm was deployed to maven central, so you just need to add a dependency to your pom.xml file if you are using maven:
<dependency>
<groupId>org.ktorm</groupId>
<artifactId>ktorm-core</artifactId>
<version>${ktorm.version}</version>
</dependency>Or Gradle:
compile "org.ktorm:ktorm-core:${ktorm.version}"Firstly, create Kotlin objects to describe your table schemas:
object Departments : Table<Nothing>("t_department") {
val id = int("id").primaryKey()
val name = varchar("name")
val location = varchar("location")
}
object Employees : Table<Nothing>("t_employee") {
val id = int("id").primaryKey()
val name = varchar("name")
val job = varchar("job")
val managerId = int("manager_id")
val hireDate = date("hire_date")
val salary = long("salary")
val departmentId = int("department_id")
}Then, connect to your database and write a simple query:
fun main() {
val database = Database.connect("jdbc:mysql://localhost:3306/ktorm", user = "root", password = "***")
for (row in database.from(Employees).select()) {
println(row[Employees.name])
}
}Now you can run this program, Ktorm will generate a SQL select * from t_employee, selecting all employees in the table and printing their names. You can use the for-each loop here because the query object returned by the select function overloads the iteration operator.
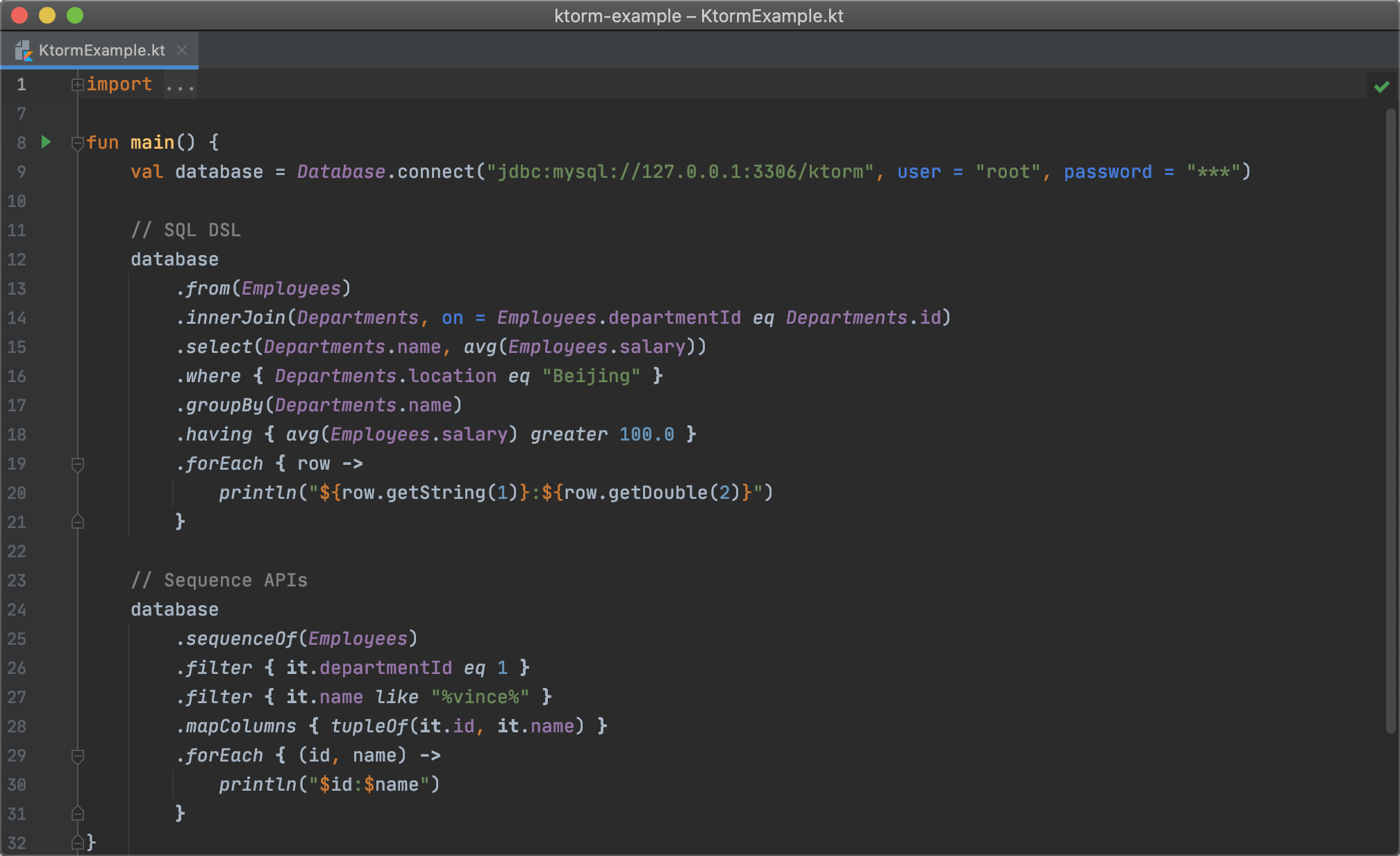
Let's add some filter conditions to the query:
database
.from(Employees)
.select(Employees.name)
.where { (Employees.departmentId eq 1) and (Employees.name like "%vince%") }
.forEach { row ->
println(row[Employees.name])
}Generated SQL:
select t_employee.name as t_employee_name
from t_employee
where (t_employee.department_id = ?) and (t_employee.name like ?) That's the magic of Kotlin, writing a query with Ktorm is easy and natural, the generated SQL is exactly corresponding to the origin Kotlin code. And moreover, it's strong-typed, the compiler will check your code before it runs, and you will be benefited from the IDE's intelligent sense and code completion.
Dynamic query that will apply different filter conditions in different situations:
val query = database
.from(Employees)
.select(Employees.name)
.whereWithConditions {
if (someCondition) {
it += Employees.managerId.isNull()
}
if (otherCondition) {
it += Employees.departmentId eq 1
}
}Aggregation:
val t = Employees.aliased("t")
database
.from(t)
.select(t.departmentId, avg(t.salary))
.groupBy(t.departmentId)
.having { avg(t.salary) gt 100.0 }
.forEach { row ->
println("${row.getInt(1)}:${row.getDouble(2)}")
}Union:
val query = database
.from(Employees)
.select(Employees.id)
.unionAll(
database.from(Departments).select(Departments.id)
)
.unionAll(
database.from(Departments).select(Departments.id)
)
.orderBy(Employees.id.desc())Joining:
data class Names(val name: String?, val managerName: String?, val departmentName: String?)
val emp = Employees.aliased("emp")
val mgr = Employees.aliased("mgr")
val dept = Departments.aliased("dept")
val results = database
.from(emp)
.leftJoin(dept, on = emp.departmentId eq dept.id)
.leftJoin(mgr, on = emp.managerId eq mgr.id)
.select(emp.name, mgr.name, dept.name)
.orderBy(emp.id.asc())
.map { row ->
Names(
name = row[emp.name],
managerName = row[mgr.name],
departmentName = row[dept.name]
)
}Insert:
database.insert(Employees) {
set(it.name, "jerry")
set(it.job, "trainee")
set(it.managerId, 1)
set(it.hireDate, LocalDate.now())
set(it.salary, 50)
set(it.departmentId, 1)
}Update:
database.update(Employees) {
set(it.job, "engineer")
set(it.managerId, null)
set(it.salary, 100)
where {
it.id eq 2
}
}Delete:
database.delete(Employees) { it.id eq 4 }Refer to detailed documentation for more usages about SQL DSL.
In addition to SQL DSL, entity objects are also supported just like other ORM frameworks do. We need to define entity classes firstly and bind table objects to them. In Ktorm, entity classes are defined as interfaces extending from Entity<E>:
interface Department : Entity<Department> {
companion object : Entity.Factory<Department>()
val id: Int
var name: String
var location: String
}
interface Employee : Entity<Employee> {
companion object : Entity.Factory<Employee>()
val id: Int
var name: String
var job: String
var manager: Employee?
var hireDate: LocalDate
var salary: Long
var department: Department
}Modify the table objects above, binding database columns to entity properties:
object Departments : Table<Department>("t_department") {
val id = int("id").primaryKey().bindTo { it.id }
val name = varchar("name").bindTo { it.name }
val location = varchar("location").bindTo { it.location }
}
object Employees : Table<Employee>("t_employee") {
val id = int("id").primaryKey().bindTo { it.id }
val name = varchar("name").bindTo { it.name }
val job = varchar("job").bindTo { it.job }
val managerId = int("manager_id").bindTo { it.manager.id }
val hireDate = date("hire_date").bindTo { it.hireDate }
val salary = long("salary").bindTo { it.salary }
val departmentId = int("department_id").references(Departments) { it.department }
}Naming Strategy: It's highly recommended to name your entity classes by singular nouns, name table objects by plurals (eg. Employee/Employees, Department/Departments).
Now that column bindings are configured, so we can use sequence APIs to perform many operations on entities. Let's add two extension properties for Database first. These properties return new created sequence objects via sequenceOf and they can help us improve the readability of the code:
val Database.departments get() = this.sequenceOf(Departments)
val Database.employees get() = this.sequenceOf(Employees)The following code uses the find function to obtain an employee by its name:
val employee = database.employees.find { it.name eq "vince" }We can also filter the sequence by the function filter. For example, obtaining all the employees whose names are vince:
val employees = database.employees.filter { it.name eq "vince" }.toList()The find and filter functions both accept a lambda expression, generating a select sql with the condition returned by the lambda. The generated SQL auto left joins the referenced table t_department:
select *
from t_employee
left join t_department _ref0 on t_employee.department_id = _ref0.id
where t_employee.name = ?Save entities to database:
val employee = Employee {
name = "jerry"
job = "trainee"
hireDate = LocalDate.now()
salary = 50
department = database.departments.find { it.name eq "tech" }
}
database.employees.add(employee)Flush property changes in memory to database:
val employee = database.employees.find { it.id eq 2 } ?: return
employee.job = "engineer"
employee.salary = 100
employee.flushChanges()Delete an entity from database:
val employee = database.employees.find { it.id eq 2 } ?: return
employee.delete()Detailed usages of entity APIs can be found in the documentation of column binding and entity query.
Ktorm provides a set of APIs named Entity Sequence, which can be used to obtain entity objects from databases. As the name implies, its style and use pattern are highly similar to the sequence APIs in Kotlin standard lib, as it provides many extension functions with the same names, such as filter, map, reduce, etc.
Most of the entity sequence APIs are provided as extension functions, which can be divided into two groups, they are intermediate operations and terminal operations.
These functions don’t execute the internal queries but return new-created sequence objects applying some modifications. For example, the filter function creates a new sequence object with the filter condition given by its parameter. The following code obtains all the employees in department 1 by using filter:
val employees = database.employees.filter { it.departmentId eq 1 }.toList()We can see that the usage is almost the same as kotlin.sequences, the only difference is the == in the lambda is replaced by the eq function. The filter function can also be called continuously, as all the filter conditions are combined with the and operator.
val employees = database.employees
.filter { it.departmentId eq 1 }
.filter { it.managerId.isNotNull() }
.toList()Generated SQL:
select *
from t_employee
left join t_department _ref0 on t_employee.department_id = _ref0.id
where (t_employee.department_id = ?) and (t_employee.manager_id is not null)Use sortedBy or soretdByDescending to sort entities in a sequence:
val employees = database.employees.sortedBy { it.salary }.toList()Use drop and take for pagination:
val employees = database.employees.drop(1).take(1).toList()Terminal operations of entity sequences execute the queries right now, then obtain the query results and perform some calculations on them. The for-each loop is a typical terminal operation, and the following code uses it to print all employees in the sequence:
for (employee in database.employees) {
println(employee)
}Generated SQL:
select *
from t_employee
left join t_department _ref0 on t_employee.department_id = _ref0.idThe toCollection functions (including toList, toSet, etc.) are used to collect all the elements into a collection:
val employees = database.employees.toCollection(ArrayList())The mapColumns function is used to obtain the results of a column:
val names = database.employees.mapColumns { it.name }Additionally, if we want to select two or more columns, we just need to wrap our selected columns by tupleOf in the closure, and the function’s return type becomes List<TupleN<C1?, C2?, .. Cn?>>.
database.employees
.filter { it.departmentId eq 1 }
.mapColumns { tupleOf(it.id, it.name) }
.forEach { (id, name) ->
println("$id:$name")
}Generated SQL:
select t_employee.id, t_employee.name
from t_employee
where t_employee.department_id = ?Other familiar functions are also supported, such as fold, reduce, forEach, etc. The following code calculates the total salary of all employees:
val totalSalary = database.employees.fold(0L) { acc, employee -> acc + employee.salary }The entity sequence APIs not only allow us to obtain entities from databases just like using kotlin.sequences, but they also provide rich support for aggregations, so we can conveniently count the columns, sum them, or calculate their averages, etc.
The following code obtains the max salary in department 1:
val max = database.employees
.filter { it.departmentId eq 1 }
.aggregateColumns { max(it.salary) }Also, if we want to aggregate two or more columns, we just need to wrap our aggregate expressions by tupleOf in the closure, and the function’s return type becomes TupleN<C1?, C2?, .. Cn?>. The example below obtains the average and the range of salaries in department 1:
val (avg, diff) = database.employees
.filter { it.departmentId eq 1 }
.aggregateColumns { tupleOf(avg(it.salary), max(it.salary) - min(it.salary)) }Generated SQL:
select avg(t_employee.salary), max(t_employee.salary) - min(t_employee.salary)
from t_employee
where t_employee.department_id = ?Ktorm also provides many convenient helper functions implemented based on aggregateColumns, they are count, any, none, all, sumBy, maxBy, minBy, averageBy.
The following code obtains the max salary in department 1 using maxBy instead:
val max = database.employees
.filter { it.departmentId eq 1 }
.maxBy { it.salary }Additionally, grouping aggregations are also supported, we just need to call groupingBy before calling aggregateColumns. The following code obtains the average salaries for each department. Here, the result's type is Map<Int?, Double?>, in which the keys are departments' IDs, and the values are the average salaries of the departments.
val averageSalaries = database.employees
.groupingBy { it.departmentId }
.aggregateColumns { avg(it.salary) }Generated SQL:
select t_employee.department_id, avg(t_employee.salary)
from t_employee
group by t_employee.department_idKtorm also provides many convenient helper functions for grouping aggregations, they are eachCount(To), eachSumBy(To), eachMaxBy(To), eachMinBy(To), eachAverageBy(To). With these functions, we can write the code below to obtain average salaries for each department:
val averageSalaries = database.employees
.groupingBy { it.departmentId }
.eachAverageBy { it.salary }Other familiar functions are also supported, such as aggregate, fold, reduce, etc. They have the same names as the extension functions of kotlin.collections.Grouping, and the usages are totally the same. The following code calculates the total salaries for each department using fold:
val totalSalaries = database.employees
.groupingBy { it.departmentId }
.fold(0L) { acc, employee ->
acc + employee.salary
}Detailed usages of entity sequence APIs can be found in the documentation of entity sequence and sequence aggregation.