完整文档:https://zhuanlan.zhihu.com/p/166496466
最近在做命名实体识别(Named Entity Recognition, NER)的工作,也就是序列标注(Sequence Tagging),老 NLP task 了,虽然之前也做过但是想细致地捋一下,看一下自从有了 LSTM+CRF 之后,NER 在做些什么,顺便记录一下最近的工作,中间有些经验和想法,有什么就记点什么
命名实体识别虽然是一个历史悠久的老任务了,但是自从2015年有人使用了BI-LSTM-CRF模型之后,这个模型和这个任务简直是郎才女貌,天造地设,轮不到任何妖怪来反对。直到后来出现了BERT。在这里放两个问题:
- 2015-2019年,BERT出现之前4年的时间,命名实体识别就只有 BI-LSTM-CRF 了吗?
- 2019年BERT出现之后,命名实体识别就只有 BERT-CRF(或者 BERT-LSTM-CRF)了吗?
经过我不完善也不成熟的调研之后,好像的确是的,一个能打的都没有
既然模型打不动了,然后我找了找 ACL2020 做NER的论文,看看现在的NER还在做哪些事情,主要分几个方面
- 多特征:实体识别不是一个特别复杂的任务,不需要太深入的模型,那么就是加特征,特征越多效果越好,所以字特征、词特征、词性特征、句法特征、KG表征等等的就一个个加吧,甚至有些中文NER任务里还加入了拼音特征、笔画特征。。?心有多大,特征就有多多
- 多任务:很多时候做NER的目的并不仅是为了NER,而是一个大任务下的子任务,比如信息抽取、问答系统等等的,如果要做一个端到端的模型,那么就需要根据自己的需求和场景,做成一个多任务模型,把NER作为其中一个子任务;另外,单独的NER本身也可以做成多任务,比如一个用来识别实体,一个用来判断实体类型
- 时令大杂烩:把当下比较流行的深度学习话题或方法跟NER结合一下,比如结合强化学习的NER、结合 few-shot learning 的NER、结合多模态信息的NER、结合跨语种学习的NER等等的,具体就不提了
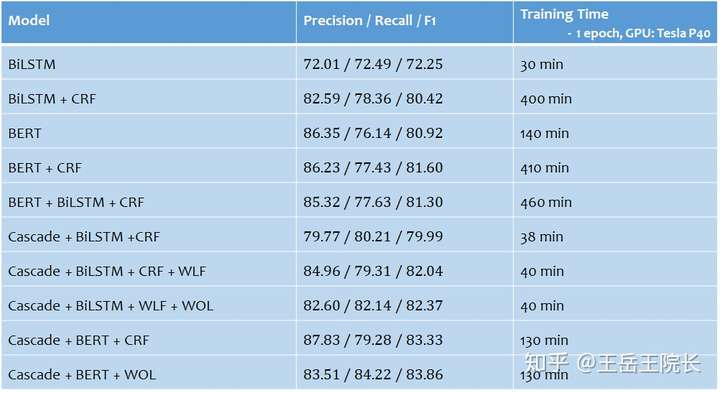
所以沿着上述思路,就在一个中文NER任务上做一些实践,写一些模型。都列在下面了,首先是 LSTM-CRF 和 BERT-CRF,然后 Cascade 开头的是几个多任务模型(因为实体类型比较多,把NER拆成两个任务,一个用来识别实体,另一个用来判断实体类型),后面的几个模型里,WLF 指的是 Word Level Feature(即在原本字级别的序列标注任务上加入词级别的表征),WOL 指的是 Weight of Loss(即在loss函数方面通过设置权重来权衡Precision与Recall,以达到提高F1的目的)