经过一段时间的探索,此次反爬中感觉还是以IP代理为主,免费的IP代理还可以,现充更强。删除浏览器中的cookies时,在某些时间段会出现Robot Check也就是验证码,填完验证码有了cookies就可以正常访问。并且验证码页面在我测试的时段刷新页面(推到爬虫我认为也就是头铁重复request)还是会有验证码。
在小王给我做code review之前,我的cookies池是不会在运行时更新的,也就是用的cookies是从上一次代码跑完的cookies池拿的。Anyway,不管cookies池起到什么程度的作用,整挺好。
这也意味着要重新调整一波Max_Fail_Cnt(cookies最大连续失败次数2->15(可能比较合理的值--))了。
本项目是为数仓项目写的一个简单的cookies池。数据仓库的前期任务是爬取亚马逊的25w条电影的数据。该项目中用到的反爬策略有:
- 代理IP
- cookies
- User Agent
个人认为,代理IP和User Agent在反爬中比较普适,cookies池这种相对而言可能稍微需要针对具体情况去做一些分析。因此在项目中实现了一个较为简单的cookies池。由于这部分相对来说是比较独立的一个模块,所以改改代码抽出一个仓库纪念下这两天的辛苦劳动hhh。
本地配置redis数据库,包括分别存储product_id(要爬取的电影的ID)和cookies的数据库。在config.py中进行配置:
COOKIE_HOST = 'localhost'
COOKIE_PORT = 6379
URL_HOST = 'localhost'
URL_PORT = 6379代理IP获取和header获取,在cookie_caching中填入你的逻辑:
# 代理IP的逻辑
# 建议https://github.com/jhao104/proxy_pool
def get_proxy():
return None
# 在这里填写user agent的逻辑
# 建议使用fake_useragent
def get_header():
return NonePS:你不搞IP代理和headers说不定也可以拿到页面--
config.py:数据库配置
db_api.py:cookies池的接口
cookie_caching.py:cookies更新,爬取逻辑
url_manager.py:要爬取的url的接口
crawler.py:多线程爬取,跑这个就行
以下截取自个人博客嘻嘻
借鉴proxy_pool,我决定用本地的Redis充当存放cookies的地方。proxy_pool的逻辑大概就是爬完代理IP,然后扔进数据库里,再开一个RESTful的接口去供外部提供代理IP。考虑到数据库一般是在本地,所以我是用CookiePool类封装了redis的接口,向外提供cookies的插入、更新、删除等操作。
事实上证明这样的操作也是合理的,数据库相当于就是一个帮你处理各种并发请求的队列,省心高效。
前面提到,带or不带cookies都可能被锤或者成功,成功的访问一般都会有cookies返回,你可以
cookiejar = response.cookies
cookiedict = requests.utils.dict_from_cookiejar(cookiejar)这样可以拿到一个字典形式的字典。
发与不发cookies我们借鉴了前面好心人的做法,有一定的概率不带cookies,这样就会有新的cookies补充。
据我观察,首次请求拿到的cookies一般是这种格式:
i18n-prefs : USD
session-id : 132-7872740-0358531
session-id-time : 2082787201l
sp-cdn : "L5Z9:CN" 我斗胆做了一下猜测,session-id是一个可以标识cookies的字段(所以我用它作为数据库cookies表的key)。当不带cookies且请求成功时,把这个cookies扔进cookies池。
@staticmethod
def cache_cookies(cookiedict):
cookies_pool.get_all()
cookies_pool.put(cookiedict['session-id'], cookiedict)后面你拿着一个cookies去做请求,如果成功你会拿到新的cookies,一般会有以下几种形式:
-
返回一些我认为的无关紧要的字段(前面的是返回的cookies,后面是发过去的cookies)

ubid-main 133-3832639-2346543 session-token ac7hD4pZPNFHeTO84/5mjShBijpi9pZ2ndWVI2VWjHqEK3KBydaqGllMsJDmPDWbQbUmxys06mr3fZSCmljj5H/CDtFrUY8OmpWPiQtPG19E/1Vjv4dwmX3F0zfP4iWpjiZhpC7OkFvTAney0VLYQfdh3lFwpW1e7iiGjL6SRetSpIFXgCdtcF55H6lxLTAs
-
返回新的
session-id,也就是和你request中带的session-id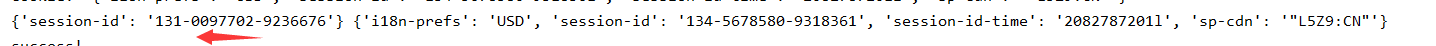


想想一个正常的浏览器和server进行交互,客户端发cookies,接cookies然后更新,所以对于上述的两种情况:
- 无关紧要的字段,更新发过去的cookies中的字段,有时候会返回新的key,这时候强行加进去就行。
session-id,我再次大胆猜测server端是想告诉我你这个cookies过期了,该换id了,于是我会把原来的cookies删除,用session-id代替原来的session-id,重新插入。
看起来好像都是更新字段,但是具体到数据库的层面,相当于我是拿session-id来做Redis的主键,所以更新操作略微有点不同。
@staticmethod
def update_cookies(cookiedict:dict, old_cookies:dict):
# session_id = old_cookies['session-id']
print('New Cookie: ', cookiedict)
# 更新cookie池缓存
cookies_pool.get_all()
if 'session-id' in cookiedict:
# 更新session-id
# session_id = cookiedict['session-id']
print('delete')
cookies_pool.delete(old_cookies['session-id'])
assert cookies_pool.get(old_cookies['session-id']) is None
for key, val in cookiedict.items():
old_cookies[key] = val
Crawler.cache_cookies(old_cookies)正常猜想,cookies是会过期的,所以需要有一个简单的淘汰机制。这里是在爬取的时候维护一个字典,记录一个cookies连续失败请求的次数,当超过Max_Cookies_Cnt次时,会把这个cookies从数据库中删除。这里一开始我的淘汰机制比较宽松,一方面是觉得cookies来之不易,另一方面是请求失败事实上不一定是cookies的锅(代理IP、网络情况之类)。
后来发现cookies有暴涨的趋势,一度维持在1000个左右...数据分开后队友一开始爬取时比较快,后续速度放缓,猜想是cookies积累老化,所以淘汰机制残酷了一些,cookies维持在700左右。