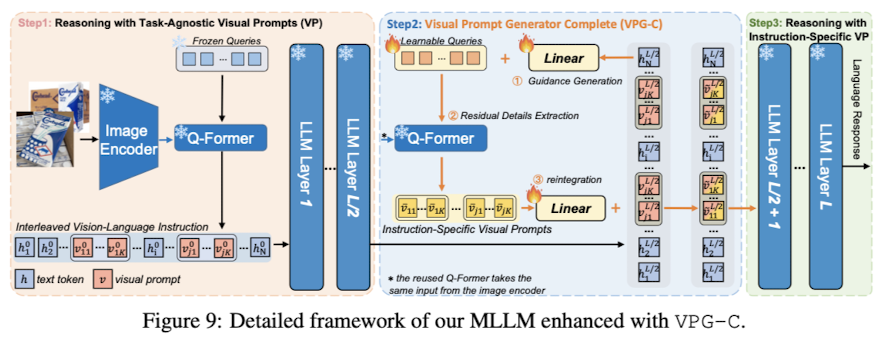
| Folder | Description |
|---|---|
| LVLM Model | Large multimodal models |
| LVLM Agent | Agent & Application of LVLM |
| LVLM Hallucination | Benchmark & Methods for Hallucination |
| Title | Venue/Date | Note | Code | Demo | Picture |
|---|---|---|---|---|---|
 InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning |
NeurIPS 2023 | InstructBLIP | Github | Local Demo |  |
 Visual Instruction Tuning |
NeurIPS 2023 | LLaVA | GitHub | Demo |  |
 LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model |
2023-04 | LLaMA Adapter v2 | Github | Demo |  |
 mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality |
2023-04 | mPLUG | Github | Demo |  |
 MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models |
2023-04 | MiniGPT-4 | Github | - | 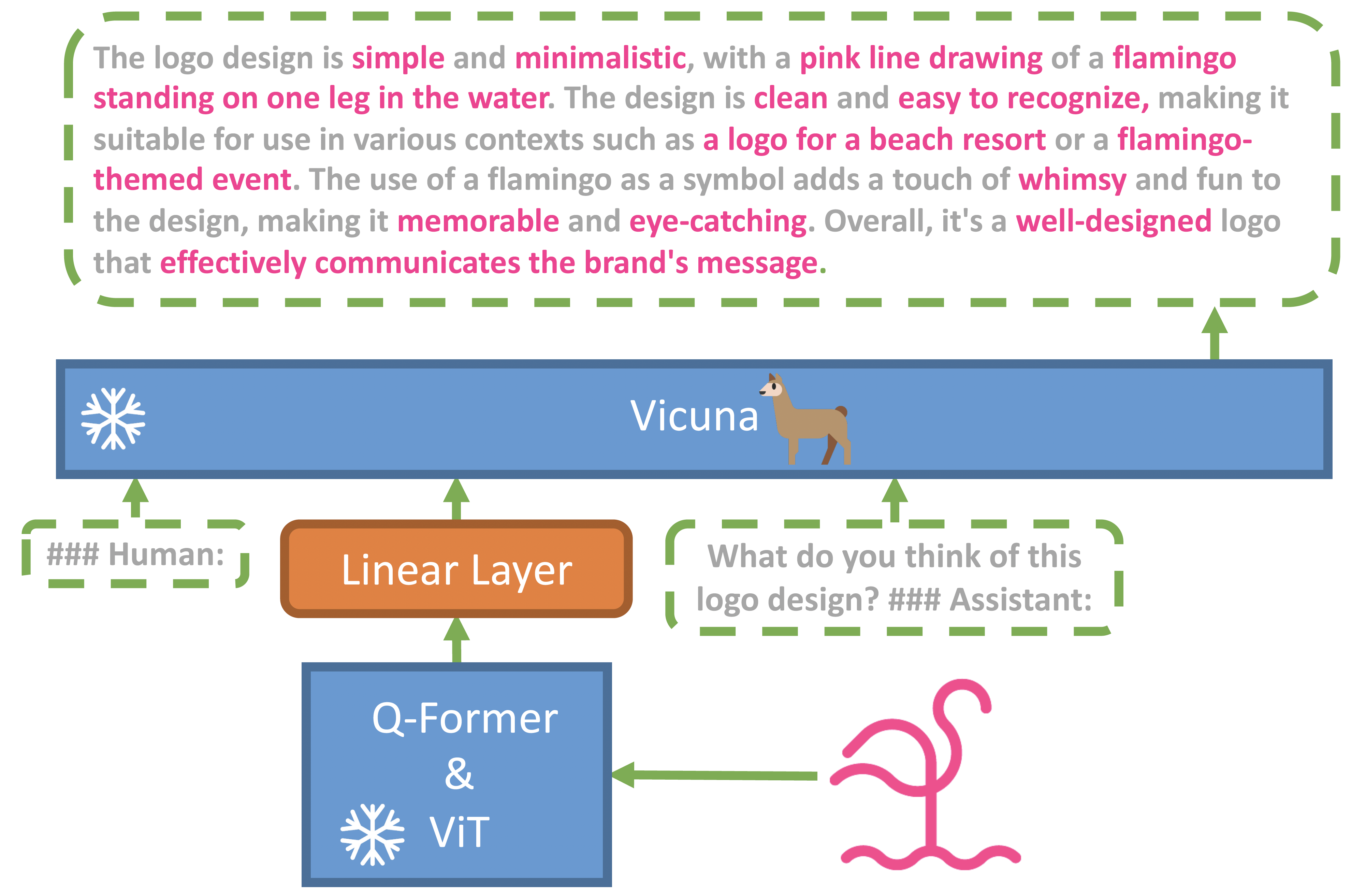 |
 TextBind: Multi-turn Interleaved Multimodal Instruction-following |
2023-09 | TextBind | Github | Demo | 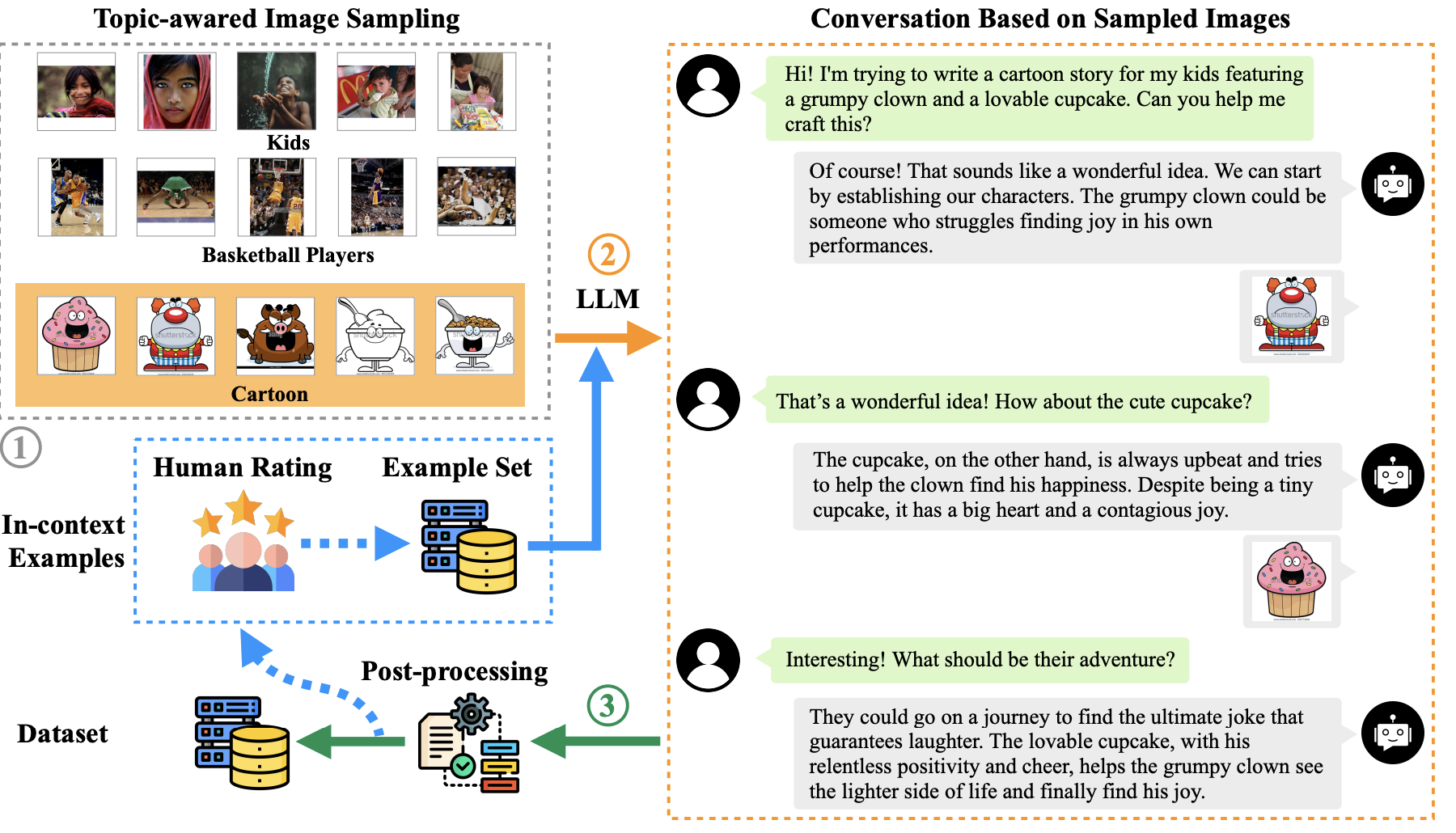 |
| InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning |
2023-09 | BLIP-Diffusion | Github | Demo | 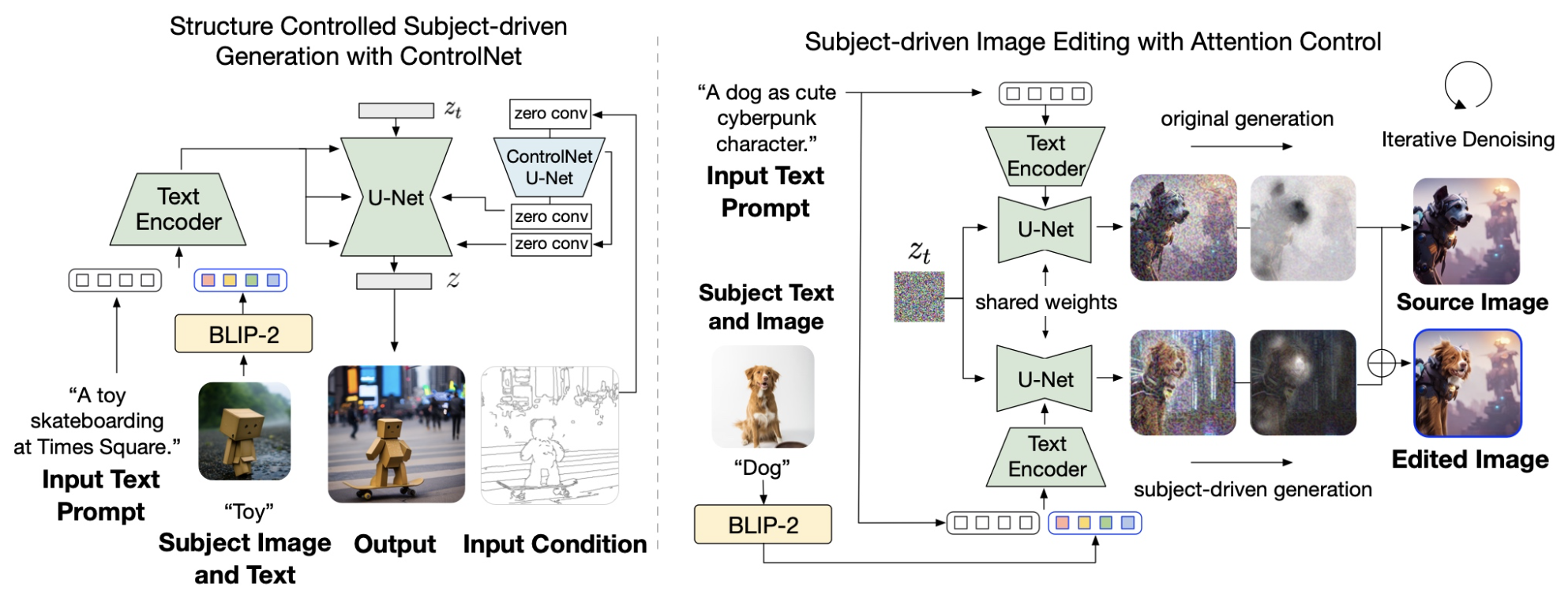 |
 NExT-GPT: Any-to-Any Multimodal LLM |
2023-09 | NeXT-GPT | Github | Demo |  |
| Title | Venue/Date | Note | Code | Demo | Picture |
|---|---|---|---|---|---|
 MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action |
2023-03 | MM-REACT | Github | Demo |  |
 Visual Programming: Compositional visual reasoning without training |
CVPR 2023 Best Paper | VISPROG (Similar to ViperGPT) | Github | Local Demo | 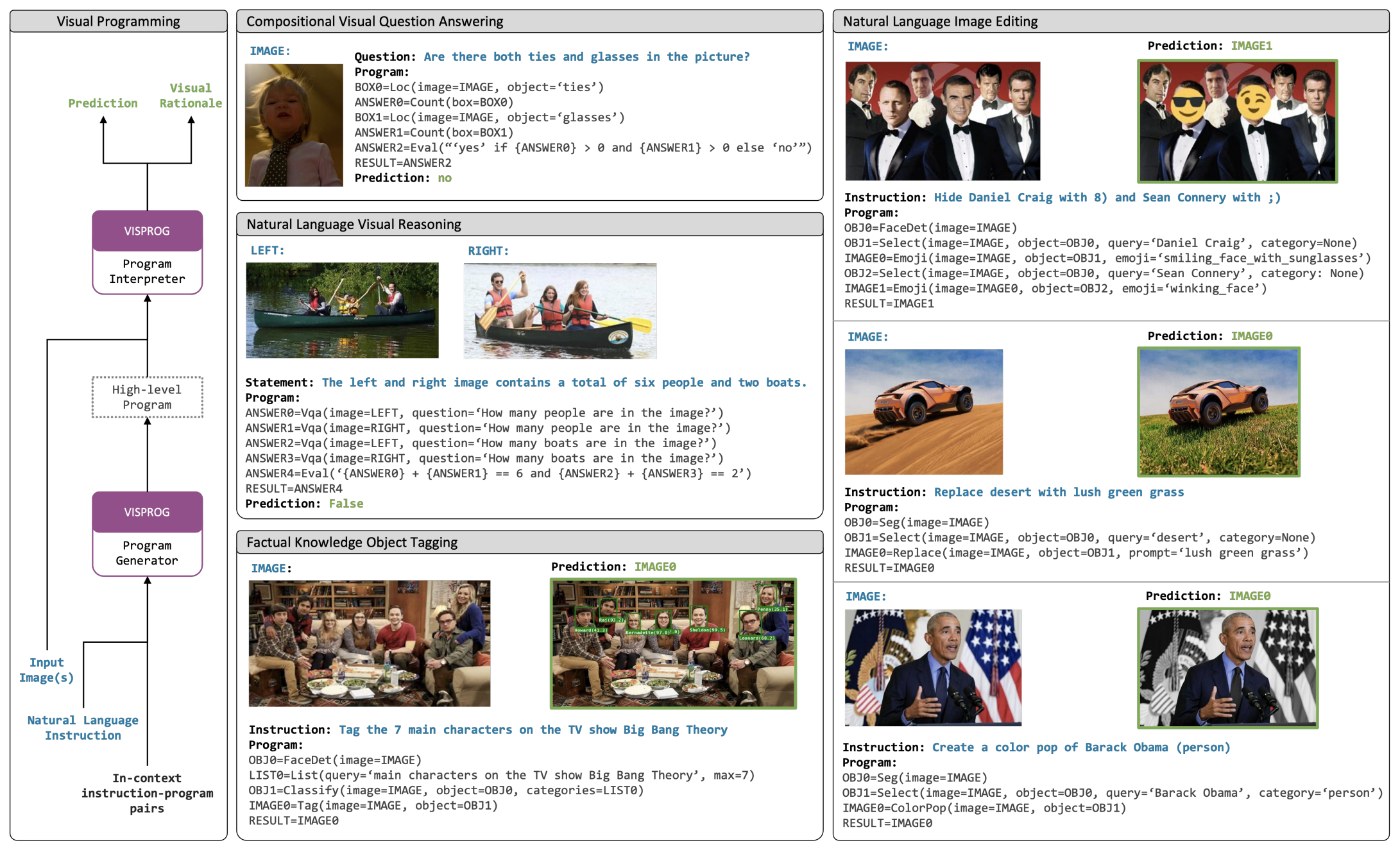 |
 HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace |
2023-03 | HuggingfaceGPT | Github | Demo | 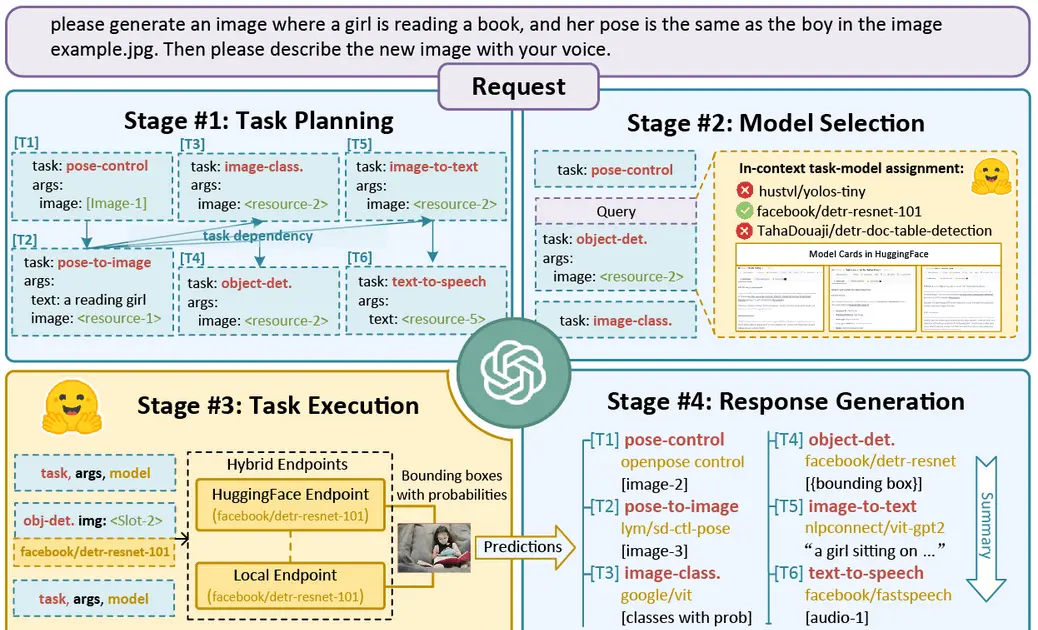 |
 Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models |
2023-04 | Chameleon | Github | Demo | 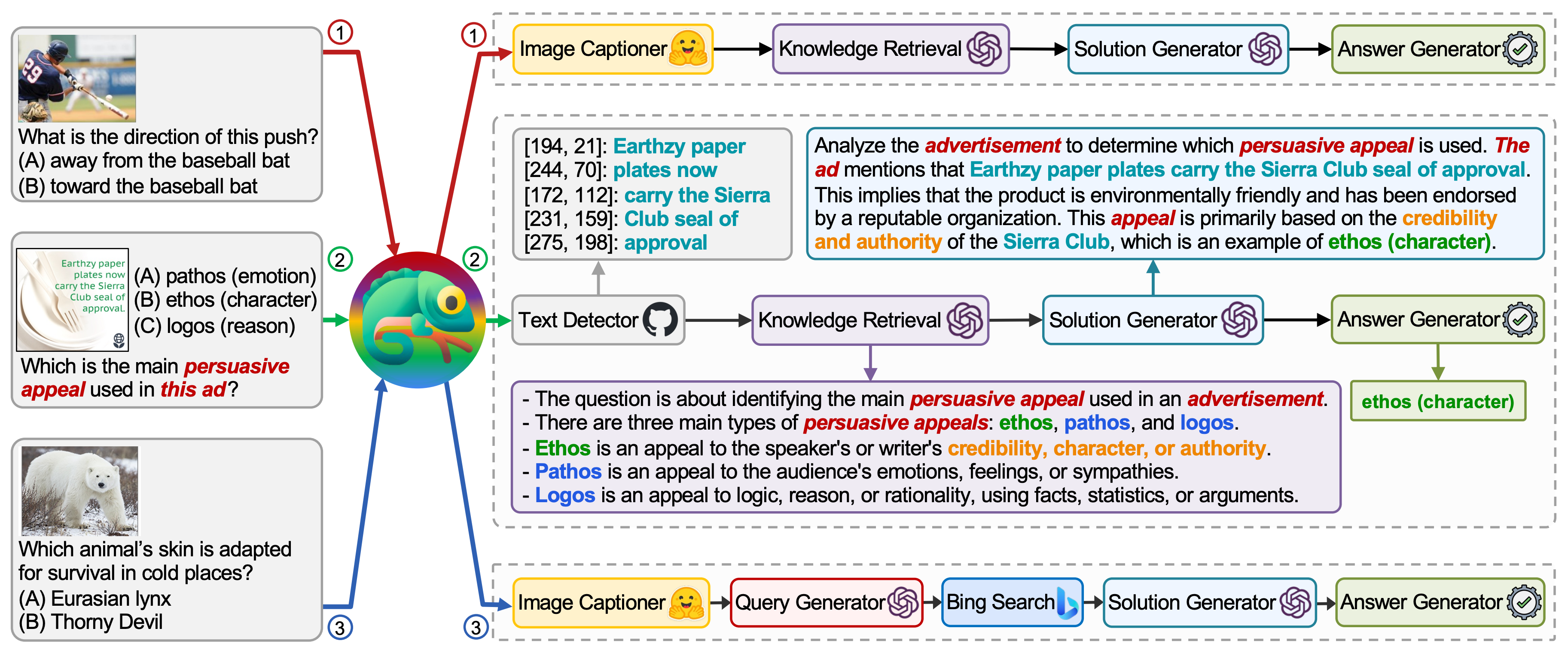 |
 IdealGPT: Iteratively Decomposing Vision and Language Reasoning via Large Language Models |
2023-05 | IdealGPT | Github | Local Demo |  |
 AssistGPT: A General Multi-modal Assistant that can Plan, Execute, Inspect, and Learn |
2023-06 | AssistGPT | Github | - | 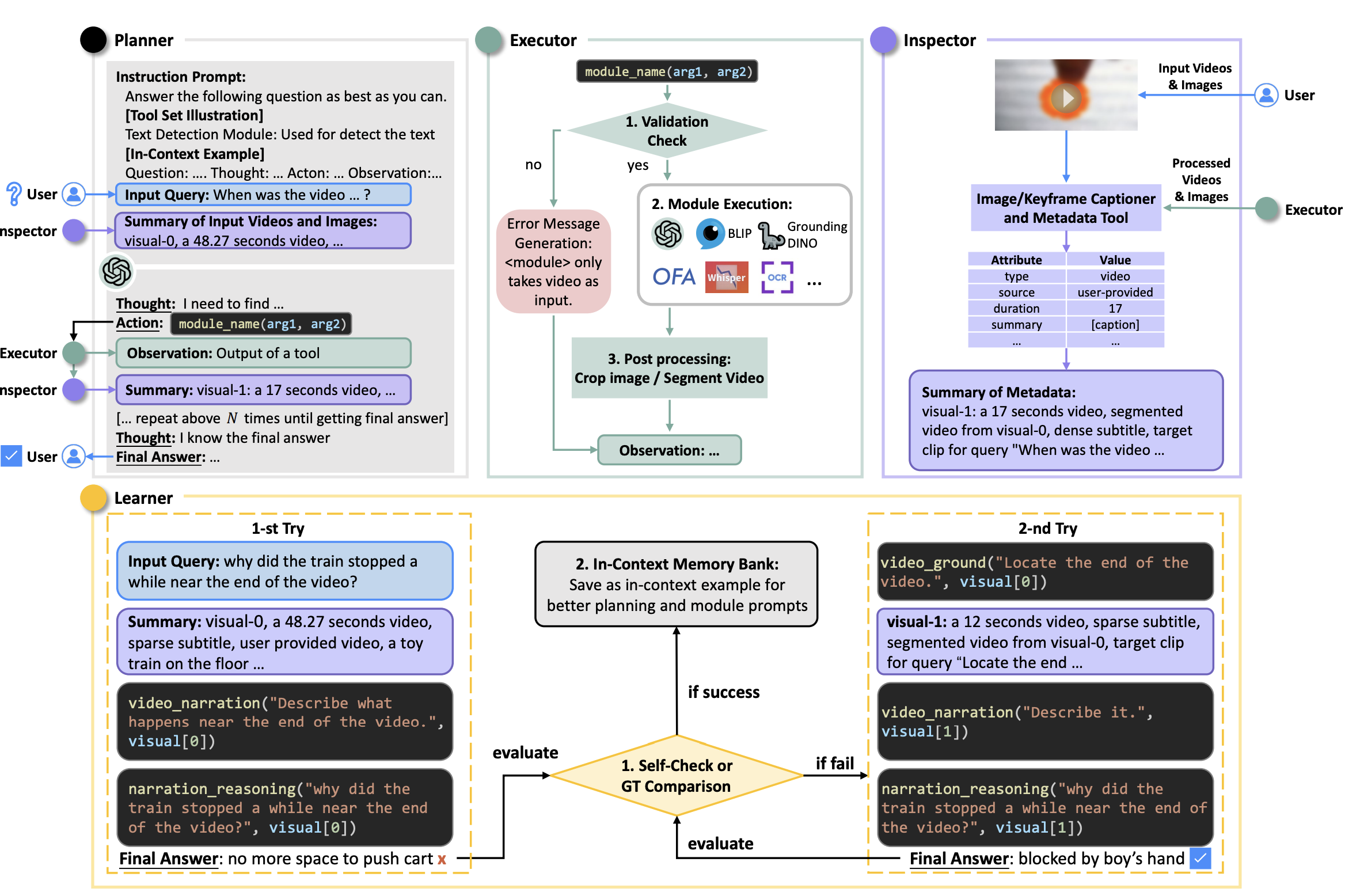 |