| Video | Description |
|---|---|
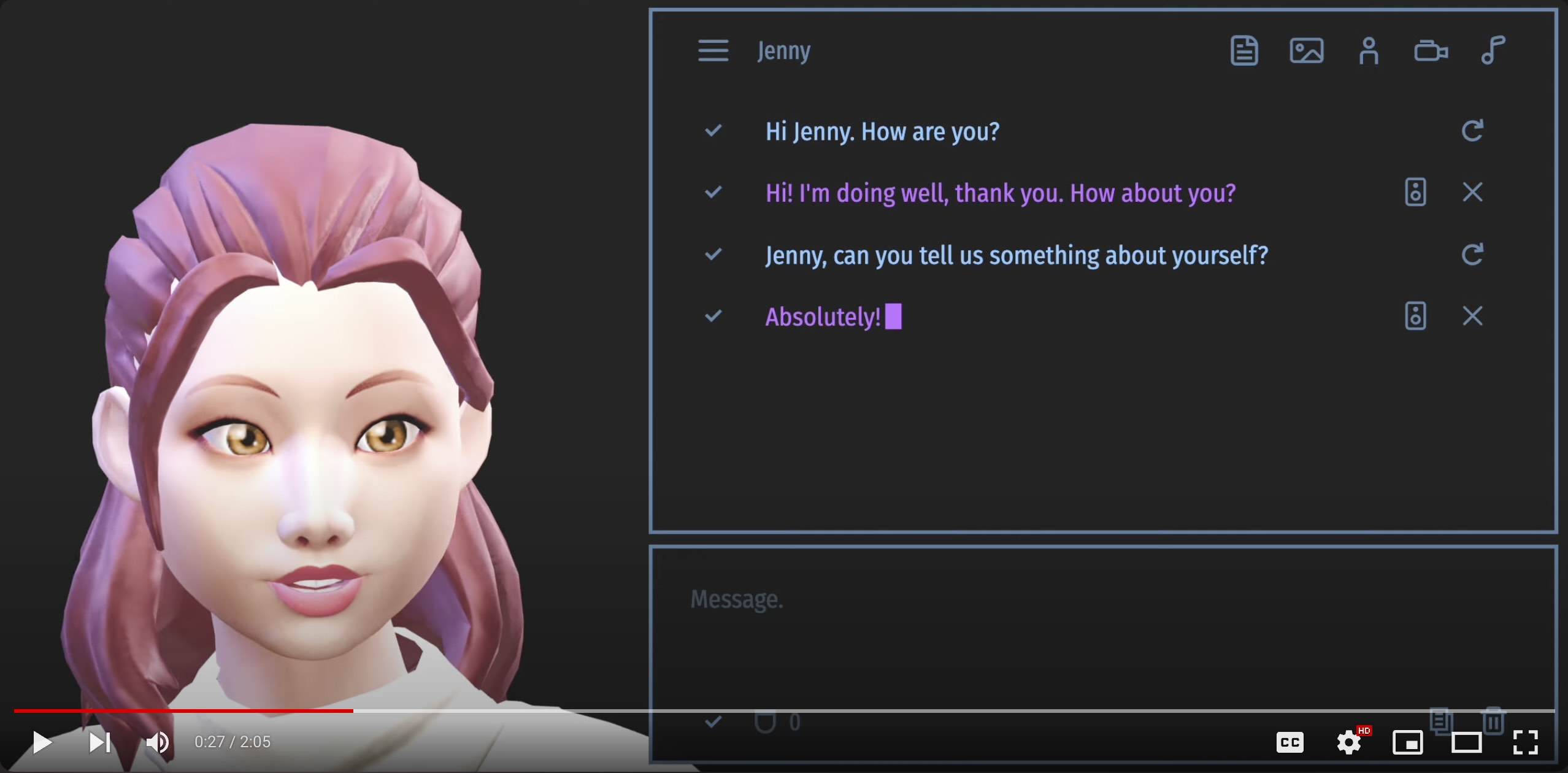 |
I chat with Jenny and Harri. The close-up view allows you to evaluate the accuracy of lip-sync in both English and Finnish. Using GPT-3.5 and Microsoft text-to-speech. |
 |
A short demo of how AI can control the avatar's movements. Using OpenAI's function calling and Google TTS with the built-in viseme generation. |
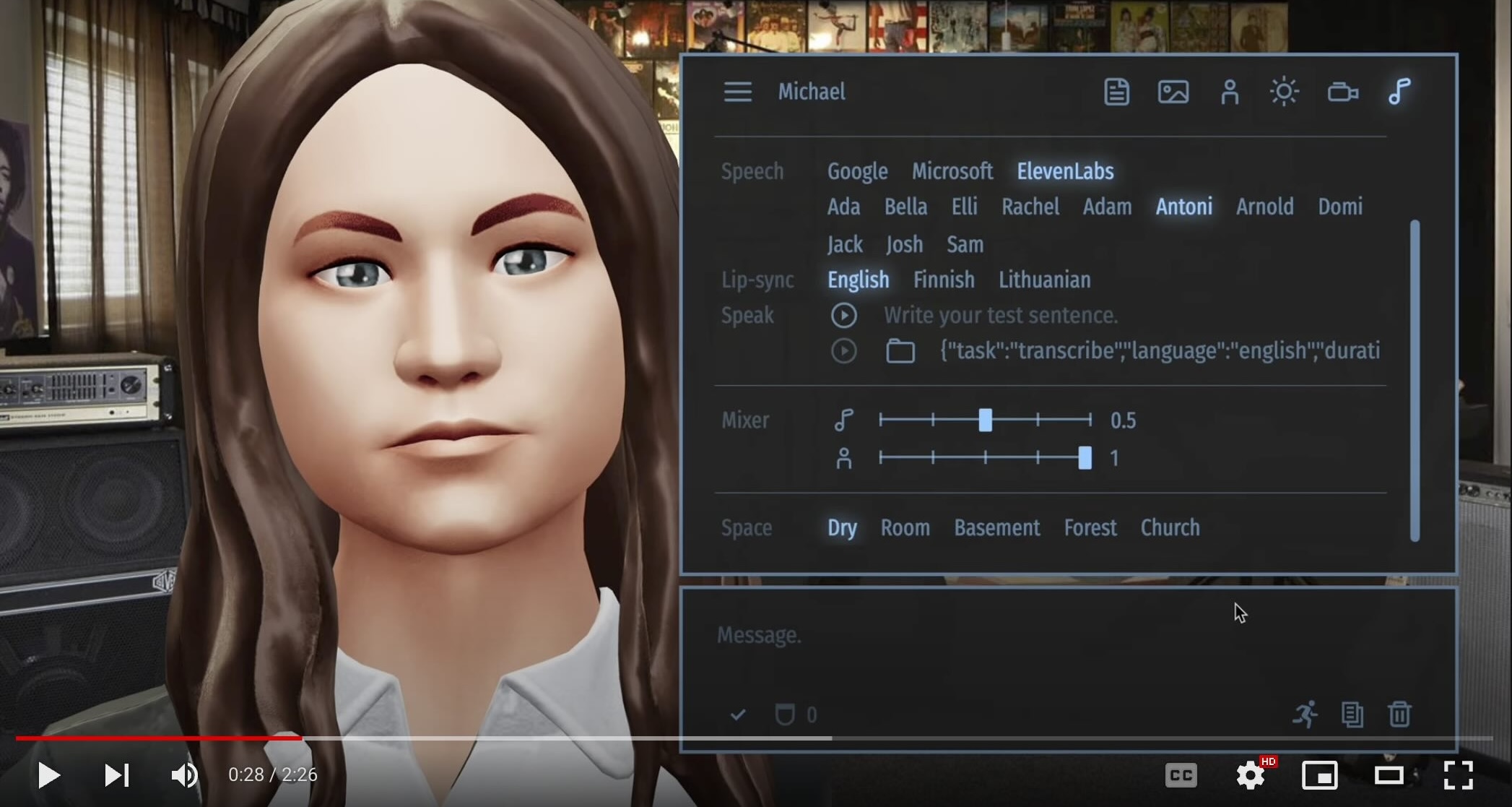 |
Michael lip-syncs to two MP3 audio tracks using OpenAI's Whisper and TalkingHead's speakAudio method. He kicks things off with some casual talk, but then goes all out by trying to tackle an old Meat Loaf classic. 🤘 Keep rockin', Michael! 🎤😂 |
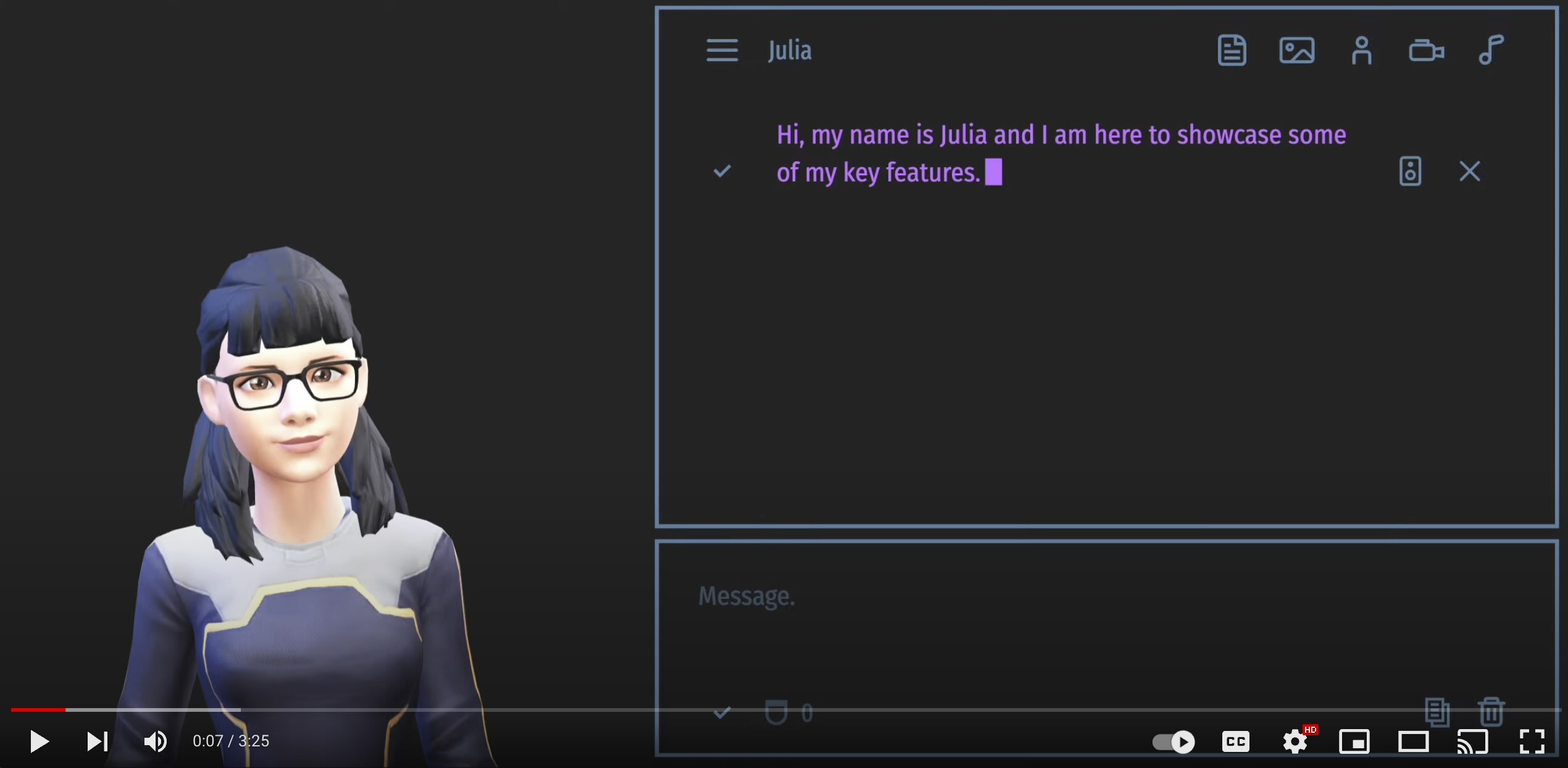 |
Julia and I showcase some of the features of the TalkingHead class/app including the settings, some poses and animations. |
All videos are real-time screen captures from a Chrome browser running the TalkingHead test web app without any post-processing.
Talking Head (3D) is a JavaScript class featuring a 3D avatar that can speak and lip-sync in real-time. The class supports Ready Player Me full-body 3D avatars (GLB), Mixamo animations (FBX), and subtitles. It also knows a set of emojis, which it can convert into facial expressions.
By default, the class uses Google Cloud TTS for text-to-speech and has a built-in lip-sync support for English, Finnish, and Lithuanian (beta). New lip-sync languages can be added by creating new lip-sync language modules. It is also possible to integrate the class with an external TTS service, such as Microsoft Azure Speech SDK, which can provide visemes with timestamps.
The class uses ThreeJS / WebGL for 3D rendering.
You can download the TalkingHead modules from releases (without dependencies). Alternatively, you can import all the needed modules from a CDN:
<script type="importmap">
{ "imports":
{
"three": "https://cdn.jsdelivr.net/npm/three@0.161.0/build/three.module.js/+esm",
"three/addons/": "https://cdn.jsdelivr.net/npm/three@0.161.0/examples/jsm/",
"talkinghead": "https://cdn.jsdelivr.net/gh/met4citizen/TalkingHead@1.1/modules/talkinghead.mjs"
}
}
</script>If you want to use the built-in Google TTS and lip-sync using Single Sign-On (SSO) functionality, give the class your TTS proxy endpoint and a function from which to obtain the JSON Web Token needed to use that proxy. Refer to Appendix B for one way to implement JWT SSO.
import { TalkingHead } from "talkinghead";
// Create the talking head avatar
const nodeAvatar = document.getElementById('avatar');
const head = new TalkingHead( nodeAvatar, {
ttsEndpoint: "/gtts/",
jwtGet: jwtGet
});FOR HOBBYISTS: If you're just looking to experiment on your personal laptop without dealing with proxies, JSON Web Tokens, or Single Sign-On, take a look at the minimal code example. Simply download the file, add your Google TTS API key, and you'll have a basic web app with a talking head.
The following table lists all the available options and their default values:
| Option | Description |
|---|---|
jwsGet |
Function to get the JSON Web Token (JWT). See Appendix B for more information. |
ttsEndpoint |
Text-to-speech backend/endpoint/proxy implementing the Google Text-to-Speech API. |
ttsApikey |
If you don't want to use a proxy or JWT, you can use Google TTS endpoint directly and provide your API key here. NOTE: I recommend that you don't use this in production and never put your API key in any client-side code. |
ttsLang |
Google text-to-speech language. Default is "fi-FI". |
ttsVoice |
Google text-to-speech voice. Default is "fi-FI-Standard-A". |
ttsRate |
Google text-to-speech rate in the range [0.25, 4.0]. Default is 0.95. |
ttsPitch |
Google text-to-speech pitch in the range [-20.0, 20.0]. Default is 0. |
ttsVolume |
Google text-to-speech volume gain (in dB) in the range [-96.0, 16.0]. Default is 0. |
ttsTrimStart |
Trim the viseme sequence start relative to the beginning of the audio (shift in milliseconds). Default is 0. |
ttsTrimEnd |
Trim the viseme sequence end relative to the end of the audio (shift in milliseconds). Default is 300. |
lipsyncModules |
Lip-sync modules to load dynamically at start-up. Limiting the number of language modules improves the loading time and memory usage. Default is ["en", "fi", "lt"]. [≥v1.2] |
lipsyncLang |
Lip-sync language. Default is "fi". |
pcmSampleRate |
PCM (signed 16bit little endian) sample rate used in speakAudio in Hz. Default is 22050. |
modelRoot |
The root name of the armature. Default is Armature. |
modelPixelRatio |
Sets the device's pixel ratio. Default is 1. |
modelFPS |
Frames per second. Note that actual frame rate will be a bit lower than the set value. Default is 30. |
modelMovementFactor |
A factor in the range [0,1] limiting the avatar's upper body movement when standing. Default is 1. |
cameraView |
Initial view. Supported views are "full", "mid", "upper" and "head". Default is "full". |
cameraDistance |
Camera distance offset for initial view in meters. Default is 0. |
cameraX |
Camera position offset in X direction in meters. Default is 0. |
cameraY |
Camera position offset in Y direction in meters. Default is 0. |
cameraRotateX |
Camera rotation offset in X direction in radians. Default is 0. |
cameraRotateY |
Camera rotation offset in Y direction in radians. Default is 0. |
cameraRotateEnable |
If true, the user is allowed to rotate the 3D model. Default is true. |
cameraPanEnable |
If true, the user is allowed to pan the 3D model. Default is false. |
cameraZoomEnable |
If true, the user is allowed to zoom the 3D model. Default is false. |
lightAmbientColor |
Ambient light color. The value can be a hexadecimal color or CSS-style string. Default is 0xffffff. |
lightAmbientIntensity |
Ambient light intensity. Default is 2. |
lightDirectColor |
Direction light color. The value can be a hexadecimal color or CSS-style string. Default is 0x8888aa. |
lightDirectIntensity |
Direction light intensity. Default is 30. |
lightDirectPhi |
Direction light phi angle. Default is 0.1. |
lightDirectTheta |
Direction light theta angle. Default is 2. |
lightSpotColor |
Spot light color. The value can be a hexadecimal color or CSS-style string. Default is 0x3388ff. |
lightSpotIntensity |
Spot light intensity. Default is 0. |
lightSpotPhi |
Spot light phi angle. Default is 0.1. |
lightSpotTheta |
Spot light theta angle. Default is 4. |
lightSpotDispersion |
Spot light dispersion. Default is 1. |
avatarMood |
The mood of the avatar. Supported moods: "neutral", "happy", "angry", "sad", "fear", "disgust", "love", "sleep". Default is "neutral". |
avatarMute |
Mute the avatar. This can be helpful option if you want to output subtitles without audio and lip-sync. Default is false. |
markedOptions |
Options for Marked markdown parser. Default is { mangle:false, headerIds:false, breaks: true }. |
statsNode |
Parent DOM element for the three.js stats display. If null, don't use. Default is null. |
statsStyle |
CSS style for the stats element. If null, use the three.js default style. Default is null. |
Once the instance has been created, you can load and display your avatar. Refer to Appendix A for how to make your avatar:
// Load and show the avatar
try {
await head.showAvatar( {
url: './avatars/brunette.glb',
body: 'F',
avatarMood: 'neutral',
ttsLang: "en-GB",
ttsVoice: "en-GB-Standard-A",
lipsyncLang: 'en'
});
} catch (error) {
console.log(error);
}An example of how to make the avatar speak the text on input text when
the button speak is clicked:
// Speak 'text' when the button 'speak' is clicked
const nodeSpeak = document.getElementById('speak');
nodeSpeak.addEventListener('click', function () {
try {
const text = document.getElementById('text').value;
if ( text ) {
head.speakText( text );
}
} catch (error) {
console.log(error);
}
});The following table lists some of the key methods. See the source code for the rest:
| Method | Description |
|---|---|
showAvatar(avatar, [onprogress=null]) |
Load and show the specified avatar. The avatar object must include the url for GLB file. Optional properties are body for either male M or female F body form, lipsyncLang, ttsLang, ttsVoice, ttsRate, ttsPitch, ttsVolume, avatarMood and avatarMute. |
setView(view, [opt]) |
Set view. Supported views are "full", "mid", "upper" and "head". The opt object can be used to set cameraDistance, cameraX, cameraY, cameraRotateX, cameraRotateY. |
setLighting(opt) |
Change lighting settings. The opt object can be used to set lightAmbientColor, lightAmbientIntensity, lightDirectColor, lightDirectIntensity, lightDirectPhi, lightDirectTheta, lightSpotColor, lightSpotIntensity, lightSpotPhi, lightSpotTheta, lightSpotDispersion. |
speakText(text, [opt={}], [onsubtitles=null], [excludes=[]]) |
Add the text string to the speech queue. The text can contain face emojis. Options opt can be used to set text-specific lipsyncLang, ttsLang, ttsVoice, ttsRate, ttsPitch, ttsVolume, avatarMood, avatarMute. Optional callback function onsubtitles is called whenever a new subtitle is to be written with the parameter of the added string. The optional excludes is an array of [start,end] indices to be excluded from audio but to be included in the subtitles. |
speakAudio(audio, [opt={}], [onsubtitles=null]) |
Add a new audio object to the speech queue. This method was added to support external TTS services such as ElevenLabs and Azure, but can be user. In audio object, property audio is either AudioBuffer or an array of PCM 16bit LE audio chunks. Property words is an array of words, wtimes is an array of corresponding starting times in milliseconds, and wdurations an array of durations in milliseconds. If the Oculus viseme IDs are know, they can be given in optional visemes, vtimes and vdurations arrays. The object also supports optional timed callbacks using markers and mtimes. The opt object can be used to set text-specific lipsyncLang. |
speakEmoji(e) |
Add an emoji e to the speech queue. |
speakBreak(t) |
Add a break of t milliseconds to the speech queue. |
speakMarker(onmarker) |
Add a marker to the speech queue. The callback function onmarker is called when the queue processes the event. |
lookAt(x,y,t) |
Make the avatar's head turn to look at the screen position (x,y) for t milliseconds. |
lookAtCamera(t) |
Make the avatar's head turn to look at the camera for t milliseconds. |
setMood(mood) |
Set avatar mood. |
playBackgroundAudio(url) |
Play background audio such as ambient sounds/music in a loop. |
stopBackgroundAudio() |
Stop playing the background audio. |
playAnimation(url, [onprogress=null], [dur=10], [ndx=0], [scale=0.01]) |
Play Mixamo animation file for dur seconds, but full rounds and at least once. If the FBX file includes several animations, the parameter ndx specifies the index. Since Mixamo rigs have a scale 100 and RPM a scale 1, the scale factor can be used to scale the positions. |
stopAnimation() |
Stop the current animation started by playAnimation. |
playPose(url, [onprogress=null], [dur=5], [ndx=0], [scale=0.01]) |
Play the initial pose of a Mixamo animation file for dur seconds. If the FBX file includes several animations, the parameter ndx specifies the index. Since Mixamo rigs have a scale 100 and RPM a scale 1, the scale factor can be used to scale the positions. |
stopPose() |
Stop the current pose started by playPose. |
start |
Start/re-start the Talking Head animation loop. |
stop |
Stop the Talking Head animation loop. |
NOTE: The index.html app was initially created for testing and developing
the TalkingHead class. It includes various integrations with several paid
services. If you only want to use the TalkingHead class in your own app,
there is no need to install and configure the index.html app.
The web app index.html shows how to integrate and use
the class with ElevenLabs WebSocket API (experimental),
Microsoft Azure Speech SDK,
OpenAI API and
Gemini Pro API.
You can preview the app's UI here. Please note that since the API proxies for the text-to-speech and AI services are missing, the avatar does not speak or lip-sync, and you can't chat with it.
If you want to configure and use the app index.html, do the following:
-
Copy the whole project to your own server.
-
Create the needed API proxies as described in Appendix B and check/update your endpoint/proxy configuration in
index.html:
// API endpoints/proxys
const jwtEndpoint = "/app/jwt/get"; // Get JSON Web Token for Single Sign-On
const openaiChatCompletionsProxy = "/openai/v1/chat/completions";
const openaiModerationsProxy = "/openai/v1/moderations";
const openaiAudioTranscriptionsProxy = "/openai/v1/audio/transcriptions";
const vertexaiChatCompletionsProxy = "/vertexai/";
const googleTTSProxy = "/gtts/";
const elevenTTSProxy = [
"wss://" + window.location.host + "/elevenlabs/",
"/v1/text-to-speech/",
"/stream-input?model_id=eleven_multilingual_v2&output_format=pcm_22050"
];
const microsoftTTSProxy = [
"wss://" + window.location.host + "/mstts/",
"/cognitiveservices/websocket/v1"
];-
The example app's UI supports both Finnish and English. If you want to add another language, you need to add an another entry to the
i18nobject. -
Add you own background images, videos, audio files, avatars etc. in the directory structure and update your site configuration
siteconfig.jsaccordingly. The keys are in English, but the entries can include translations to other languages.
Licenses, attributions and notes related to the index.html web app assets:
- The app uses Marked Markdown parser and DOMPurify XSS sanitizer.
- Fira Sans Condensed and Fira Sans Extra Condensed fonts are licensed under the SIL Open Font License, version 1.1, available with a FAQ at http://scripts.sil.org/OFL. Digitized data copyright (c) 2012-2015, The Mozilla Foundation and Telefonica S.A.
- Example avatar "brunette.glb" was created at Ready Player Me. The avatar is free to all developers for non-commercial use under the CC BY-NC 4.0 DEED. If you want to integrate Ready Player Me avatars into a commercial app or game, you must sign up as a Ready Player Me developer.
- Example animation "walking.fbx" is from Mixamo, a subsidiary of Adobe Inc. Mixamo service is free and its animations (>2000) can be used royalty free for personal, commercial, and non-profit projects. Raw animation files can't be distributed outside the project team and can't be used to train ML models.
- Background view examples are from Virtual Backgrounds
- Impulse response (IR) files for reverb effects:
- ir-room: OpenAir, Public Domain Creative Commons license
- ir-basement: OpenAir, Public Domain Creative Commons license
- ir-forest (Abies Grandis Forest, Wheldrake Wood): OpenAir, Creative Commons Attribution 4.0 International License
- ir-church (St. Andrews Church): OpenAir, Share Alike Creative Commons 3.0
- Ambient sounds/music attributions:
- murmur.mp3: https://github.com/siwalikm/coffitivity-offline
NOTE: None of the assets described above are used or distributed as part of the TalkingHead class releases. If you wish to use them in your own application, please refer to the exact terms of use provided by the copyright holders.
Why not use the free Web Speech API?
The free Web Speech API can't provide word-to-audio timestamps, which are essential for accurate lip-sync. As far as I know, there is no way even to get Web Speech API speech synthesis as an audio file or determine its duration in advance. At some point I tried to use the Web Speech API events for syncronization, but the results were not good.
What paid text-to-speech service should I use?
It depends on your use case and budget. If the built-in lip-sync support is sufficient for your needs, I would recommend Google TTS, because it gives you up to 4 million characters for free each month. If your app needs to support multiple languages, I would consider Microsoft Speech SDK.
I would like to have lip-sync support for language X.
You have two options. First, you can implement a word-to-viseme
class similar to those that currently exist for English and Finnish.
See Appendix C for detailed instructions.
Alternatively, you can check if Microsoft Azure TTS can provide visemes
for your language and use Microsoft Speech SDK integration (speakAudio)
instead of Google TTS and the built-in lip-sync (speakText).
Can I use a custom 3D model?
The class supports full-body Ready Player Me avatars. You can also make your own custom model, but it needs to have a RPM compatible rig/bone structure and all their blend shapes. Please refer to Appendix A and readyplayer.me documentation for more details.
Any future plans for the project?
This is just a small side-project for me, so I don't have any big plans for it. That said, there are several companies that are currently developing text-to-3D-avatar and text-to-3D-animation features. If and when they get released as APIs, I will probably take a look at them and see if they can be used/integrated in some way to the project.
[1] Finnish pronunciation, Wiktionary
[2] Elovitz, H. S., Johnson, R. W., McHugh, A., Shore, J. E., Automatic Translation of English Text to Phonetics by Means of Letter-to-Sound Rules (NRL Report 7948). Naval Research Laboratory (NRL). Washington, D. C., 1976. https://apps.dtic.mil/sti/pdfs/ADA021929.pdf
FOR HOBBYISTS:
-
Create your own full-body avatar free at https://readyplayer.me
-
Copy the given URL and add the following URL parameters in order to include all the needed morph targets:
morphTargets=ARKit,Oculus+Visemes,mouthOpen,mouthSmile,eyesClosed,eyesLookUp,eyesLookDown&textureSizeLimit=1024&textureFormat=png
Your final URL should look something like this:https://models.readyplayer.me/64bfa15f0e72c63d7c3934a6.glb?morphTargets=ARKit,Oculus+Visemes,mouthOpen,mouthSmile,eyesClosed,eyesLookUp,eyesLookDown&textureSizeLimit=1024&textureFormat=png -
Use the URL to download the GLB file to your own web server.
FOR 3D MODELERS:
You can create and use your own 3D full-body model, but it has to be Ready Player Me compatible. Their rig has a Mixamo-compatible bone structure described here:
https://docs.readyplayer.me/ready-player-me/api-reference/avatars/full-body-avatars
For lip-sync and facial expressions, you also need to have ARKit and Oculus compatible blend shapes, and a few additional ones, all listed in the following two pages:
https://docs.readyplayer.me/ready-player-me/api-reference/avatars/morph-targets/apple-arkit https://docs.readyplayer.me/ready-player-me/api-reference/avatars/morph-targets/oculus-ovr-libsync
The TalkingHead class supports both separated mesh and texture atlasing.
-
Make a CGI script that generates a new JSON Web Token with an expiration time (exp). See jwt.io for more information about JWT and libraries that best fit your needs and architecture.
-
Protect your CGI script with some authentication scheme. Below is an example Apache 2.4 directory config that uses Basic authentication (remember to always use HTTPS/SSL!). Put your CGI script
getin thejwtdirectory.
# Restricted applications
<Directory "/var/www/app">
AuthType Basic
AuthName "Restricted apps"
AuthUserFile /etc/httpd/.htpasswd
Require valid-user
</Directory>
# JSON Web Token
<Directory "/var/www/app/jwt" >
Options ExecCGI
SetEnv REMOTE_USER %{REMOTE_USER}
SetHandler cgi-script
</Directory>- Make an External Rewriting Program script that verifies JSON Web Tokens. The script should return
OKif the given token is not expired and its signature is valid. Start the script in Apache 2.4 config. User's don't use the verifier script directly, so put it in some internal directory, not under document root.
# JSON Web Token verifier
RewriteEngine On
RewriteMap jwtverify "prg:/etc/httpd/jwtverify" apache:apache- Make a proxy configuration for each service you want to use. Add the required API keys and protect the proxies with the JWT token verifier. Below are some example configs for Apache 2.4 web server. Note that when opening a WebSocket connection (ElevenLabs, Azure) you can't add authentication headers in browser JavaScript. This problem is solved here by including the JWT token as a part of the request URL. The downside is that the token might end up in server log files. This is typically not a problem as long as you are controlling the proxy server, you are using HTTPS/SSL, and the token has an expiration time.
# OpenAI API
<Location /openai/>
RewriteCond ${jwtverify:%{http:Authorization}} !=OK
RewriteRule .+ - [F]
ProxyPass https://api.openai.com/
ProxyPassReverse https://api.openai.com/
ProxyPassReverseCookiePath "/" "/openai/"
ProxyPassReverseCookieDomain ".api.openai.com" ".<insert-your-proxy-domain-here>"
RequestHeader set Authorization "Bearer <insert-your-openai-api-key-here>"
</Location>
# Google TTS API
<Location /gtts/>
RewriteCond ${jwtverify:%{http:Authorization}} !=OK
RewriteRule .+ - [F]
ProxyPass https://eu-texttospeech.googleapis.com/v1beta1/text:synthesize?key=<insert-your-api-key-here> nocanon
RequestHeader unset Authorization
</Location>
# Microsoft Azure TTS WebSocket API (Speech SDK)
<LocationMatch /mstts/(?<jwt>[^/]+)/>
RewriteCond ${jwtverify:%{env:MATCH_JWT}} !=OK
RewriteRule .+ - [F]
RewriteCond %{HTTP:Connection} Upgrade [NC]
RewriteCond %{HTTP:Upgrade} websocket [NC]
RewriteRule /mstts/[^/]+/(.+) "wss://<insert-your-region-here>.tts.speech.microsoft.com/$1" [P]
RequestHeader set "Ocp-Apim-Subscription-Key" <insert-your-subscription-key-here>
</LocationMatch>
# ElevenLabs Text-to-speech WebSocket API
<LocationMatch /elevenlabs/(?<jwt>[^/]+)/>
RewriteCond ${jwtverify:%{env:MATCH_JWT}} !=OK
RewriteRule .+ - [F]
RewriteCond %{HTTP:Connection} Upgrade [NC]
RewriteCond %{HTTP:Upgrade} websocket [NC]
RewriteRule /elevenlabs/[^/]+/(.+) "wss://api.elevenlabs.io/$1" [P]
RequestHeader set "xi-api-key" "<add-your-elevenlabs-api-key-here>"
</LocationMatch>The steps that are common to all new languages:
- Create a new file named
lipsync-xx.mjswherexxis your language code, and place the file in the./modules/directory. The language module should have a class namedLipsyncXxwhere Xx is the language code. The naming in important, because the modules are loaded dynamically based on their names. - The class should have (at least) the following two methods:
preProcessTextandwordsToVisemes. These are the methods used in the TalkingHead class. - The purpose of the
preProcessTextmethod is to preprocess the given text by converting symbols to words, numbers to words, and filtering out characters that should be left unspoken (if any), etc. This is often needed to prevent ambiguities between TTS and lip-sync engines. This method takes a string as a parameter and returns the preprocessed string. - The purpose of the
wordsToVisemesmethod is to convert the given text into visemes and timestamps. The method takes a string as a parameter and returns a lip-sync object. The lipsync object has three required properties:visemes,timesanddurations.- Property
visemesis an array of Oculus OVR viseme codes. Each viseme is one of the strings:'aa','E','I','O','U','PP','SS','TH','CH','FF','kk','nn','RR','DD','sil'. See the reference images here: https://developer.oculus.com/documentation/unity/audio-ovrlipsync-viseme-reference/ - Property
timesis an array of starting times, one entry for each viseme invisemes. Starting times are to be given in relative units. They are always scaled according to the word timestamps that we get from the TTS engine. - Property
durationsis an array of relative duration in milliseconds, one entry for each viseme invisemes. Durations are to be given in relative units. They are always scaled according to the word timestamps that we get from the TTS engine.
- Property
- (OPTIONAL) Add the new module
"xx"tolipsyncModulesparameter array in thetalkinghead.mjsfile.
The difficult part is to actually make the conversion from words to visemes. What is the best approach depends on the language. Here are some typical approaches to consider (not a comprehensive list):
- Direct mapping from graphemes to phonemes to visemes. This works well for languages that have a consistent one-to-one mapping between individual letters and phonemes. This was used as the approach for the Finnish language (
lipsync-fi.mjs) giving >99.9% lip-sync accuracy compared to the Finnish phoneme dictionary. Implementation size was ~4k. Unfortunately not all languages are phonetically orthographic languages. - Rule-based mapping. This was used as the approach for the English language (
lipsync-en.mjs) giving around 80% lip-sync accuracy compared to the English phoneme dictionary. However, since the rules cover the most common words, the effective accuracy is higher. Implementation size ~12k. - Dictionary based approach. If neither of the previous approaches work for your language, make a search from some open source phoneme dictionary. Note that you still need some backup algorithm for those words that are not in the dictionary. The problem with phoneme dictionaries is their size. For example, the CMU phoneme dictionary for English is ~5M.
- Neural-net approach based on transformer models. Typically this should be done on server-side as the model side can be >50M.
TalkingHead is supposed to be a real-time class, so latency is always something to consider. It is often better to be small and fast than to aim for 100% accuracy.